

Eddie Yang
@ey_985
Followers
559
Following
264
Media
35
Statuses
218
Assistant professor @PurduePolSci. Prev. @UCSDPoliSci @MSFTResearch
Joined November 2017
Tenure letter write: I completely disagree with all of his work but it’s good work

@TheVixhal your post challenged me. every one of your points is wrong but i had to think about each for a while :)
0
0
0

AI presents a fundamental threat to our ability to use polls to assess public opinion. Bad actors who are able to infiltrate panels can flip close election polls for less than the cost of a Starbucks coffee. Models will also infer and confirm hypotheses in experiments. Current
26
206
631
We also developed a new R package, localLLM ( https://t.co/hijpvkPT3T), that enables reproducible annotation using LLM directly in R. More functionalities to follow!
cran.r-project.org
The 'localLLM' package provides R bindings to the 'llama.cpp' library for running large language models. The package uses a lightweight architecture where the C++ backend library is downloaded at...
2
2
17
Based on these findings (and more in the paper), we offer recommendations for best practices. We also summarized them in a checklist to facilitate a more principled procedure.
1
1
7
Finding 4: Bias-correction methods like DSL can reduce bias, but they introduce a trade-off: corrected estimates often have larger standard errors, requiring a large ground-truth sample (600-1000+) to be beneficial without losing too much precision.
1
0
7
Finding 3: In-context learning (providing a few annotated examples in the prompt) offers only marginal improvements in reliability, with benefits plateauing quickly. Changes to prompt format has a small effect (smaller and reasoning models more sensitive).
1
0
9
Finding 2: This disagreement has significant downstream consequences. Re-running the original analyses with LLM annotations produced highly variable coefficient estimates, often altering the conclusions of the original studies.
1
2
9
There is also an interesting linear relationship between LLM-human and LLM-LLM annotation agreement: when LLMs agree more with each other, they also tend to agree more with humans and supervised models! We gave some suggestions on what annotation tasks are good for LLMs.
1
0
10
Finding 1: LLM annotations show pretty low intercoder reliability with the original annotations (coded by humans or supervised models). Perhaps surprisingly, reliability among the different LLMs themselves is only moderate (larger models better).
1
2
16
The LLM annotations also allowed us to present results on: 1. effectiveness of in-context learning 2. model sensitivity to changes in prompt format 3. bias-correction methods
1
0
7
We re-annotated data from 14 published papers in political science with 15 different LLMs (300 million annotations!). We compared them with the original annotations. We then re-ran the original analyses to see how much variation in coefficient estimates these LLMs give us.
1
0
9
New paper: LLMs are increasingly used to label data in political science. But how reliable are these annotations, and what are the consequences for scientific findings? What are best practices? Some new findings from a large empirical evaluation. Paper: https://t.co/F8FlrsLbzM
6
76
251
Happy to say that I’ll be a postdoc @KelloggSchool w/ @dashunwang and join @purduepolsci as an assistant professor! Stoked and grateful to continue my study on the politics of science and AI
14
2
115

A paper entitled "The impact of US–China tensions on US science: Evidence from the NIH investigations" by Ruixue Jia @rxjia, Margaret Roberts @mollyeroberts @GPS_UCSD, Ye Wang @YeWang1576, Eddie Yang @EddieYang_ @UCSanDiego is published @PNASNews! https://t.co/zjWxEZJKkX
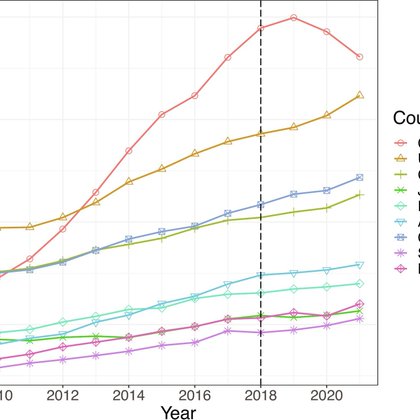
pnas.org
Amid the discourse on foreign influence investigations in research, this study examines the impact of NIH-initiated investigations starting in 2018...
1
8
15
Supporting models on and off the stage

TIL scikit-learn, an open-source ML library, has only one Platinum sponsor and it is ... Chanel?
0
0
2
More expensive to watch Caitlin Clark than the Chicago Bulls😬 at what point in my career can I bring up season ticket with the chair?
0
0
1
😅

It’s probably not feasible or ideal for a host of reasons, but I actually think that junior hiring in quantitative fields of academia would be more informative if candidates had to submit replication materials along with their JMP.
0
0
4
Every once in a while I come across one of these gems by Henry Farrell. This one published in 2018 and perfectly describing the moment we're living in now. https://t.co/D0IemyUZ8w

bostonreview.net
We live in Philip K. Dick’s future, not George Orwell’s or Aldous Huxley’s.
0
0
1
I’m in Washington DC this year. If you’re around and want to grab coffee, let me know!
0
0
0