
Edward Milsom
@edward_milsom
Followers
459
Following
1K
Media
52
Statuses
419
Machine learning PhD student working on deep learning and deep kernel methods. Compass CDT, University of Bristol.
Compass, University of Bristol
Joined March 2022
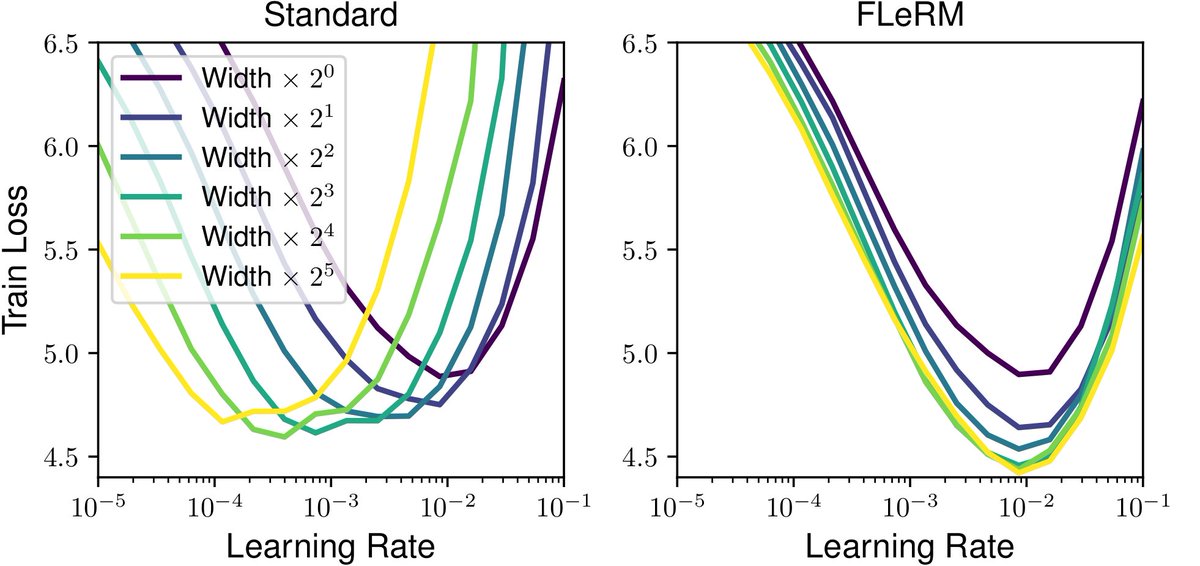
Our paper "Function-Space Learning Rates" is on arXiv! We give an efficient way to estimate the magnitude of changes to NN outputs caused by a particular weight update. We analyse optimiser dynamics in function space, and enable hyperparameter transfer with our scheme FLeRM! 🧵👇
12
69
425
RT @giffmana: Over the past year or so I've come across a ton of papers improving on or broadening muP. So many that i kinda lost track. H….
0
15
0

RT @beenwrekt: The NeurIPS paper checklist corroborates the bureaucratic theory of statistics.

argmin.net
The NeurIPS checklist corroborates the bureaucratic theory of statistics.
0
28
0
What's some "must read" literature on generalisation in neural networks? I keep thinking about this paper and it really makes me want to understand better the link between optimisation and generalisation.

arxiv.org
In this work, we investigate the implicit regularization induced by teacher-student learning dynamics in self-distillation. To isolate its effect, we describe a simple experiment where we consider...
5
30
224
Me: Asks literally any question. LLM: Excellent! You're really getting to the heart of computer architecture / electrical infrastructure / The history of Barcelona. Don't flatter me LLM, I am aware of my own limitations, even if you are not.
1
0
9
RT @benaibean: Is it possible to _derive_ an attention scheme with effective zero-shot generalisation? The answer turns out to be yes! To a….
0
54
0
RT @xidulu: This is really a beautiful idea: Autodiff alleviates graduate students' pain from manually deriving the gradient, but MuP-ish w….
0
4
0
As long as your model is autodiffable, you can use a method like FLeRM (or hopefully an even better future approach to this idea).
0
0
2
Since this post gained a little bit of traction: to clarify: suppose we only had mu-P derived for transformers. Maybe SSMs could actually work better, but we don't know good hyperparameters for huge SSMs. Empirical approaches let you fix that with zero thought required.
1
0
4
To address the "parameterisation lottery" (ideas win because they work well with popular choices of e.g. learning rates) I think empirical hyperparameter transfer methods are crucial. Rules like mu-P require you to derive them first, which is painful.
Our paper "Function-Space Learning Rates" is on arXiv! We give an efficient way to estimate the magnitude of changes to NN outputs caused by a particular weight update. We analyse optimiser dynamics in function space, and enable hyperparameter transfer with our scheme FLeRM! 🧵👇
1
6
62
RT @laurence_ai: Happy to announce that my lab has four papers accepted at ICML, including one spotlight:.
0
7
0
It seems none of the big open-source models are using mu-P still (correct me if I'm wrong!). According to this it should be quite easy: Are there any major drawbacks to using mu-P? (I'd be very surprised if Grok wasn't using it because Greg Yang.).

cerebras.ai
Cerebras is the go-to platform for fast and effortless AI training. Learn more at cerebras.ai.
3
1
21
RT @sambowyer__: Our position paper on LLM eval error bars has just been accepted to ICML 2025 as a spotlight poster!.
0
10
0
RT @xidulu: I talked to a lot of people about "a weight decay paper from Wang and Aitchison" at ICLR, which is officially been accepted at….
0
10
0
Function-Space Learning Rates has been accepted to ICML 2025!. Go read about our paper here:.
Our paper "Function-Space Learning Rates" is on arXiv! We give an efficient way to estimate the magnitude of changes to NN outputs caused by a particular weight update. We analyse optimiser dynamics in function space, and enable hyperparameter transfer with our scheme FLeRM! 🧵👇
3
14
137
RT @SeunghyunSEO7: wow, didnt know cs336 cover scaling things. scaling law, critical bsz, muP and so on. (this lecture slide screenshot is….
0
34
0
Easy (but informative) exercise: Show by induction that an exponential moving average is distributive i.e. EMA(\sum_i X_i)_t = \sum_i EMA(X_i)_t. What EMA initialisation strategies make the base case hold?.
0
0
1
RT @tslwn: There's a lot to process here, but I was pleased to see that Anthropic's 'Circuit Tracing' paper cites three of our recent contr….
0
6
0