

Eduardo Sánchez
@eduardosg_ai
Followers
216
Following
267
Media
30
Statuses
48
Research Scientist at @Meta. PhD Student at @ucl_nlp. Formerly MSc AI at @UM_DACS & BSc CS at @MatCom_UH. Working on Low-Resource MT and linguistic reasoning.
London/Paris
Joined May 2022
🚨NEW BENCHMARK🚨. Are LLMs good at linguistic reasoning if we minimize the chance of prior language memorization?. We introduce Linguini🍝, a benchmark for linguistic reasoning in which SOTA models perform below 25%. w/ @b_alastruey, @artetxem, @costajussamarta et al. 🧵(1/n)

3
23
117
Some interesting work quantifying the curse of multilinguality! Congrats, @b_alastruey and @JoaoMJaneiro!.

🚀New paper alert! 🚀. In our work @AIatMeta we dive into the struggles of mixing languages in largely multilingual Transformer encoders and use the analysis as a tool to better design multilingual models to obtain optimal performance. 📄: 🧵(1/n)

0
0
2

Linguini is available on GitHub ( and on Huggingface (. You can read our paper here 👉 and BBEH's paper here 👉 Happy saturating! 🍝.
github.com
Linguini is a benchmark to measure a language model’s linguistic reasoning skills without relying on pre-existing language-specific knowledge, based on the International Linguistic Olympiad problem...
0
0
1
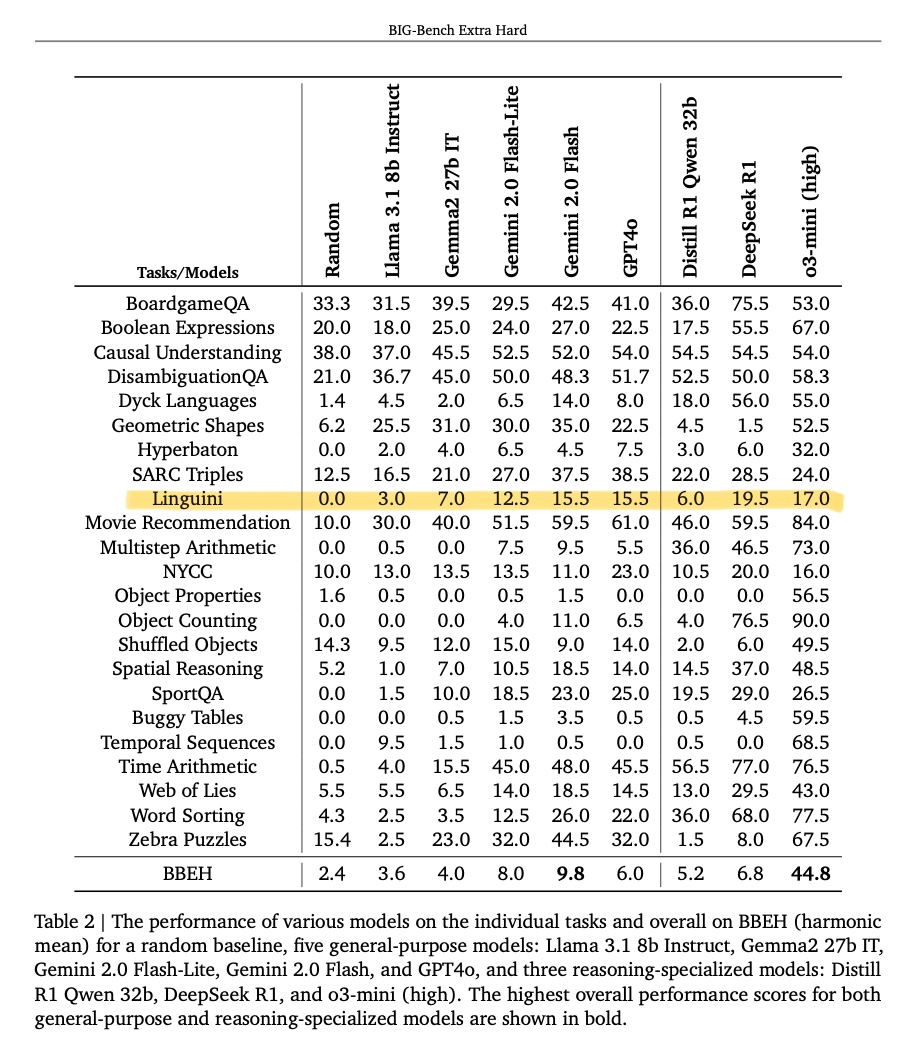
Happy to see that Linguini, our benchmark for language-agnostic linguistic reasoning, has been included in DeepMind’s BIG-Bench Extra Hard (BBEH). Linguini remains challenging for reasoning models, being one of only two (hard) tasks where o3-mini doesn't show massive gains.
1
3
16
RT @javifer_96: New ICLR 2025 (Oral) paper🚨. Do LLMs know what they don’t know?.We observed internal mechanisms suggesting models recognize….
0
44
0
RT @AIatMeta: New research from Meta FAIR: Large Concept Models (LCM) is a fundamentally different paradigm for language modeling that deco….
0
558
0

Happy to share our team's work on the Large Concept Model, an alternative to token-based LLMs that operates in a multilingual embedding space, unlocking zero-shot generalization and outperforming similarly sized SOTA LLMs for several languages in various summarization tasks.

Wrapping up the year and coinciding with #NeurIPS2024, today at Meta FAIR we’re releasing a collection of nine new open source AI research artifacts across our work in developing agents, robustness & safety and new architectures. More in the video from @jpineau1. All of this
1
1
13
RT @b_alastruey: 🚨New #EMNLP Main paper🚨. What is the impact of ASR pretraining in Direct Speech Translation models?🤔. In our work we use….
0
4
0
TL;DR: Linguini🍝 is a benchmark to assess linguistic reasoning without relying on prior language-specific knowledge. This task is still hard for LLMs, with SOTA models achieving below 25% accuracy. Paper:.👉 Dataset:.👉 🧵(12/n)

1
1
13
In spite of the noise introduced by different orthographies and imperfect OCR, performance for Apurinã increases from 0% to 16.67% with the full textbook in-context. A more systematic study of this phenomenon can be conducted by leveraging a wider source of textbooks. 🧵(11/n)

1
0
4
Previous studies have shown LLMs can acquire MT abilities in an unseen language only through an in-context textbook. We scale these results in number of books and number of tasks. The cascaded PDF → OCR → LLM approach increases complexity by learning from noisy data. 🧵(10/n)

1
0
4
We also assess the correlation of language resourcefulness (num. of speakers & num. of Google search results) and accuracy. The distribution follows a uniform trend, hinting that accuracy for a language isn’t largely correlated to likelihood of being in the training set. 🧵(9/n)

1
0
4
We selected the best performing model (Claude 3 Opus) and transcribed the best performing problems (acc >= 75%). For 13/16 problems there’s at least one non-Latin script in which the model can solve the problem with greater or equal performance than in Latin script. 🧵(8/n)

1
0
4
To confirm the previous results, we transcribed some problems into 4 non-Latin scripts (Cyrillic, Greek, Armenian and Georgian). If the model doesn’t rely on instances of the language in its training set, it should be able to solve the task in a non-Latin script as well. 🧵(7/n)

1
0
4
We ran a series of ablation studies to assess to which degree models rely on the context or on their pre-training data to solve the problems. We removed the context and performance dropped uniformly to 1-2%, suggesting a very low likelihood of dataset contamination. 🧵(6/n)

1
0
5
We benchmark an array of open and proprietary LLMs, excluding examples in the same language for in-context learning. Performance remains below 25% for all SOTA models at the time experiments were run, and an outstanding gap persists between open and closed LLMs. 🧵(5/n)

1
0
6
To solve the problems, LLMs must rely on the given context to infer the rules of the language from the provided examples. In this sample in Terenâ, models must notice that (🔵) voiced d/b/j fortition occurs, (🟢) m/n is dropped (🔴) an epenthetic vowel e has to be added. 🧵(4/n)

1
0
4
The problems require solving linguistic reasoning tasks, such as morphosyntactic segmentation, morphosemantic alignment, derivation or graphophonemic transcription. We curated 894 questions, grouped in 160 problems across 75 languages, belonging to 33 language families. 🧵(3/n)

1
0
4
To build a benchmark of linguistic challenges in languages LLMs are unlikely to have seen before, we extracted problems from the @IOLing_official, a contest where participants must solve linguistic puzzles in (mostly) extremely low-resource languages. 🧵(2/n)

1
1
5