
Gargi Ghosh
@gargighosh
Followers
716
Following
78
Media
14
Statuses
68
Researcher at FAIR (Meta AI)
Bellevue, WA
Joined December 2009
We released new research - Byte Latent Transformer(BLT).BLT encodes bytes into dynamic patches using light-weight local models and processes them with a large latent transformer. Think of it as a transformer sandwich!


New from Meta FAIR — Byte Latent Transformer: Patches Scale Better Than Tokens introduces BLT, which for the first time, matches tokenization-based LLM performance at scale with significant improvements in inference efficiency & robustness. Paper ➡️

11
83
667

RT @liang_weixin: 🎉 Excited to share: "𝐌𝐢𝐱𝐭𝐮𝐫𝐞-𝐨𝐟-𝐓𝐫𝐚𝐧𝐬𝐟𝐨𝐫𝐦𝐞𝐫𝐬 (𝐌𝐨𝐓)" has been officially accepted to TMLR (March 2025) and the code is now….
0
84
0
RT @ylecun: Rob Fergus is the new head of Meta-FAIR!.FAIR is refocusing on Advanced Machine Intelligence: what others would call human-leve….
0
43
0
RT @fb_engineering: Meta and NVIDIA have teamed up to supercharge vector search on GPUs by integrating NVIDIA cuVS into Faiss v1.10, Meta’s….
0
128
0
We are releasing Collaborative Reasoner, a self improving social agent that achieves stronger performance through collaboration. This research leverages social skills such as effective communication, providing feedback, having empathy, and theory-of-mind.
🚀 Meta FAIR is releasing several new research artifacts on our road to advanced machine intelligence (AMI). These latest advancements are transforming our understanding of perception. 1️⃣ Meta Perception Encoder: A large-scale vision encoder that excels across several image &
1
0
2
This enables you all to explore efficient post training strategies with byte level models and much more. Stay tuned for next set of research from BLT team.
0
0
0
Excited to share that we are open sourcing BLT model weights by popular demand(Code was open sourced already): paper:
ai.meta.com
Meta FAIR is releasing several new research artifacts that advance our understanding of perception and support our goal of achieving advanced machine intelligence (AMI).
2
6
26
RT @InceptionAILabs: We are excited to introduce Mercury, the first commercial-grade diffusion large language model (dLLM)! dLLMs push the….
0
986
0
RT @ClementDelangue: Our science team has started working on fully reproducing and open-sourcing R1 including training data, training scrip….
0
533
0
RT @ykilcher: 🔥New Video🔥.I delve (ha!) into Byte Latent Transformer: Patches Scale Better Than Tokens where the authors do away with token….
0
106
0
RT @nrehiew_: Wrote about some of my favourite papers over the past year or so and some research directions that I am excited about in 2025….
0
77
0
RT @AIatMeta: New research from Meta FAIR — Meta Memory Layers at Scale. This work takes memory layers beyond proof-of-concept, proving the….
0
178
0
Joint wrk with @mingdachen @LukeZettlemoyer @scottyih , Alicia Sun, Yang Li, Karthik Padthe, @RulinShao.
0
0
3
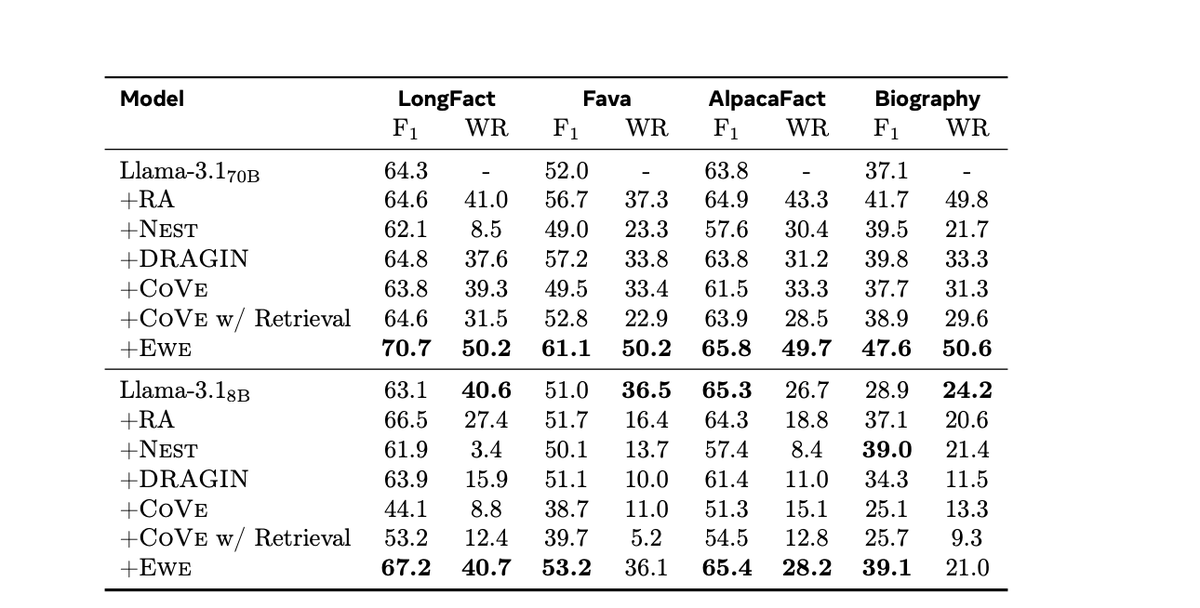
Ewe outperforms strong baselines on four fact-seeking long-form generation datasets, increasing the factuality metric, VeriScore, by 2 to 10 points absolute without sacrificing the helpfulness of the responses. Ewe can be easily adapted to various large language models.
1
0
3
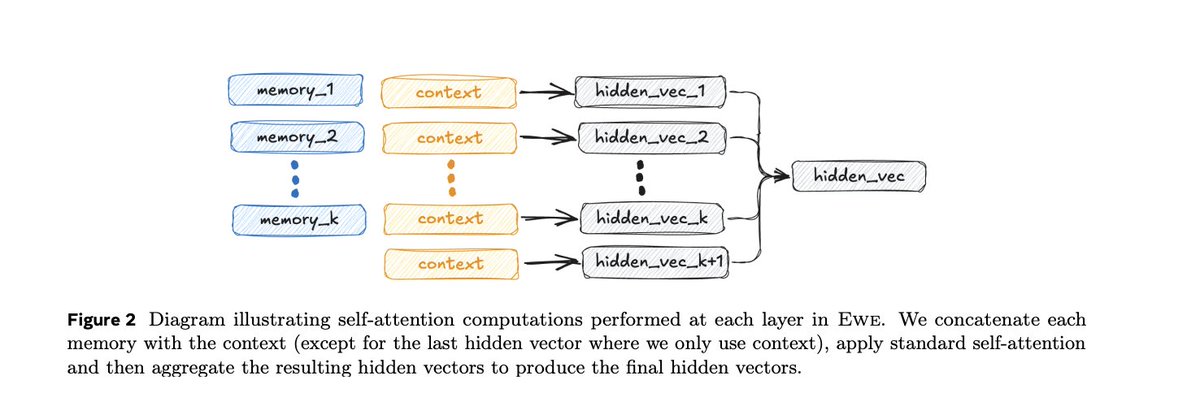
The working memory consists of k memory units, each unit stores the representations of each feedback message of M tokens.The memory is refreshed based on online fact-checking and retrieval feedback, allowing Ewe to rectify false claims.

1
0
1
Last one of the year - EWE: Ewe (Explicit Working Memory), enhances factuality in long-form text generation by integrating a working memory that receives real-time feedback from external resources.
2
22
103