

Bo Liu
@cranialxix
Followers
354
Following
167
Media
1
Statuses
32
Research Scientist @Meta FAIR | CS PhD @UT Austin | Former Research Intern @DeepMind, @Nvidia, @Baidu
Mountain View, CA
Joined January 2018
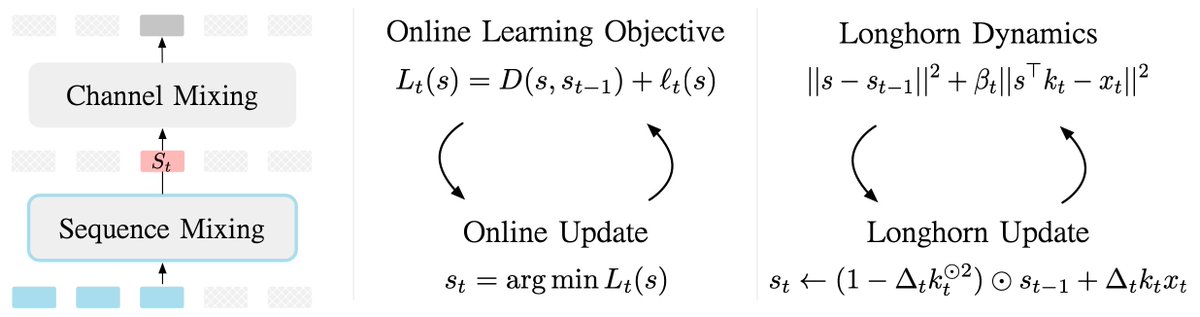
How to design State Space Models (SSM) from principles? We propose to view SSM's recurrence as the per-step closed-form solution to an online learning problem. To this end, we present Longhorn, a novel SSM that achieves 1.8x better sampling efficiency against Mamba.
6
37
179
RT @qiwang067: 🚀 Excited to announce our workshop “Embodied World Models for Decision Making” at #NeurIPS2025! 🎉. Keynote speakers, panelis….
0
13
0
RT @TheOfficialACM: 🙌 Meet the 2024 ACM Technical Awards Recipients!.We’re proud to honor this year’s innovators in autonomous systems, cry….
0
14
0
If you are interested in learning/using flow/diffusion models, please check this thread from the original author of rectified flow (RF). It contains:. 1. a tutorial blog (to quickly get a sense of what RF is and some interesting findings we had lately).2. a codebase (a minimal.

🚀 New Rectified Flow materials (WIP)!. 📖 Tutorials: 💻 Code: 📜 Notes: Contributions from @RunlongLiao, @XixiHu12, @cranialxix, and many others! 🔥. Let us know your thoughts! 🚀.
0
3
8
For imitation learning in robotics: as cheap as behavioral cloning, as expressive as diffusion policy. From the original group that designed the rectified flow.

🚀 Excited to share AdaFlow at #NeurIPS2024!. A fast, adaptive method for training robots to act with one-step efficiency—no distillation needed! 🌟. Come check out our poster! . 📍 West Ballroom A-D #7309.📅 Today 11 am - 2 pm. #MachineLearning #Robotics

0
0
12
RT @wightmanr: One of the last minute papers I added support for that delayed this release was 'Cautious Optimizers' As I promised, I pushe….

huggingface.co
0
7
0
RT @wightmanr: I was going to publish a new timm release yesterday with significant Optimizer updates: Adopt, Big Vision Adafactor, MARS, a….
0
12
0
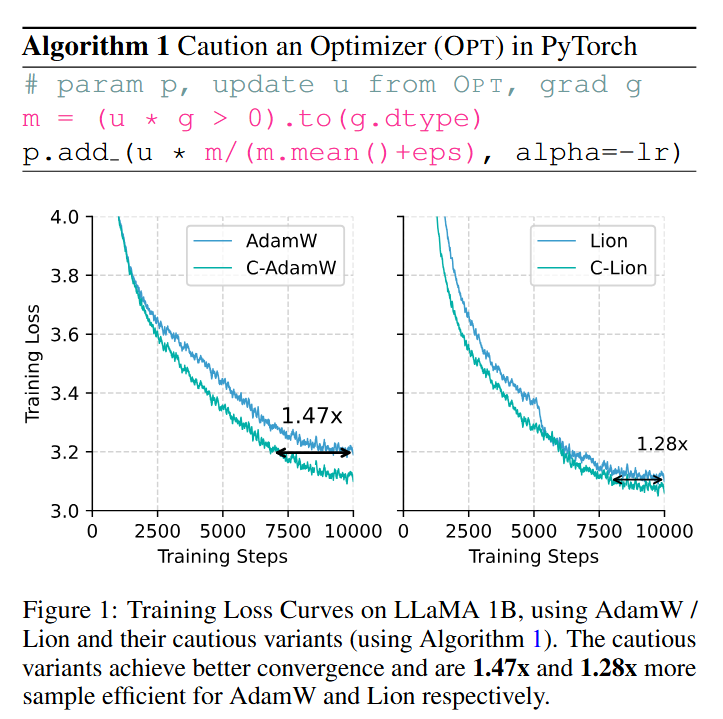
One line of code for improved training by ensuring the update aligns with the gradient. Note that there is no need to tune hyperparameters; just use those from AdamW or Lion.

TLDR: 1⃣ line modification, satisfaction (theoretically and empirically) guaranteed 😀😀😀.Core idea: 🚨Do not update if you are not sure.👨💻🤗📚 @cranialxix @lqiang67 @Tim38463182
0
4
16
RT @JiahengHu1: 🚀 Despite efforts to scale up Behavior Cloning for Robots, large-scale BC has yet to live up to its promise. How can we bre….
0
37
0
RWKV-7'update is pretty similar to the Longhorn model's update (, which is derived explicitly from solving online associative recall in closed form. The household transform used in the RWKV-7, (diag(w) - a \alpha^\top \beta), stems from optimizing a.

RWKV-7 "Goose" 🪿 preview rc2 => Peak RNN architecture?😃Will try to squeeze more performance for the final release. Preview code:

0
2
17
RT @yzhang_cs: 🍾🍾🍾𝙀𝙭𝙘𝙞𝙩𝙚𝙙 𝙩𝙤 𝙞𝙣𝙩𝙧𝙤𝙙𝙪𝙘𝙚 𝙤𝙪𝙧 𝙡𝙖𝙩𝙚𝙨𝙩 𝙬𝙤𝙧𝙠: 𝙂𝙖𝙩𝙚𝙙 𝙎𝙡𝙤𝙩 𝘼𝙩𝙩𝙚𝙣𝙩𝙞𝙤𝙣 (𝙂𝙎𝘼), a new linear attention model inspired by ABC @haopeng_n….

huggingface.co
0
35
0
RT @KyleLiang5: SVD in Galore is an OVERKILL! Lyapunov analysis says any reasonable projection matrix works. Here comes Online Subspace De….
0
7
0
Interested in the continual adaptation of large AI models? Join us by submitting your work to our NeurIPS workshop :) This is a great opportunity to engage with experts and advance the dialogue on how foundation models can be dynamically updated. Deadline is Sept 9th AoE.

[1/4] Happy to announce that we are organizing a workshop on continuous development of foundation models at NeurIPS’24. Website:
0
1
12

Unlike previous SSMs, Longhorn shares the same architecture as Mamba, except that we replace the Mamba SSM with the Longhorn's SSM. We believe this forms a fair comparison. Moreover, as Longhorn's update is derived, it does not require a separately parameterized forget gate.
1
0
5
We release our code following the NanoGPT style for the convenience of the community. It contains the one-file implementation of:. LLaMA, RetNet, GLA, RWKV, Mamba, and Longhorn,. and uses the OpenWebText dataset. Code:

github.com
Official PyTorch Implementation of the Longhorn Deep State Space Model - Cranial-XIX/longhorn
1
0
19
RT @Ar_Douillard: We release the async extension of DiLoCo shared in November, led by our amazing intern @cranialxix!. 👀 TL;DR: we do distr….
0
8
0
RT @_akhaliq: Google Deepmind present Asynchronous Local-SGD Training for Language Modeling. paper page: Local sto….
0
29
0
RT @RL_Conference: Thrilled to announce the first annual Reinforcement Learning Conference @RL_Conference, which will be held at UMass Amhe….
0
87
0
RT @konstmish: Constrained optimization perspective on what Lion optimizer is doing. They also generalize Lion to operations other than sig….
0
14
0