
David Chanin
@chanindav
Followers
100
Following
13
Media
7
Statuses
27
Joined January 2011
9/9: 🏁 Feature hedging may be a core reason SAEs underperform. By understanding and addressing it, e.g., with Balance Matryoshka SAEs, we hope to help SAEs reach their full potential!. 🔗 paper: By @chanindav, @TomasDulka, @AdriGarriga.

arxiv.org
It is assumed that sparse autoencoders (SAEs) decompose polysemantic activations into interpretable linear directions, as long as the activations are composed of sparse linear combinations of...
0
0
1
8/9: 📊 Promising Results! Our "Balance Matryoshka SAEs," when tuned, show improved performance on several SAEBench metrics (like TPP, k-sparse probing, feature splitting) compared to standard Matryoshka or non-Matryoshka SAEs.
1
0
1
7/9: 💡 Our Solution: Balance Matryoshka SAEs! We propose modifying Matryoshka SAEs by adding a scaling coefficient to each level's loss term. This allows tuning the trade-off to better balance the competing forces of absorption and hedging.

2
0
1
6/9: 🪆Hedging is bad news for Matryoshka SAEs. Matryoshka SAEs solve feature absorption by enforcing hierarchy. However, their inner, narrower levels are more susceptible to feature hedging! Matryoshka SAEs essentially trade less absorption for more hedging.
1
0
0
5/9: 🔬 We study feature hedging theoretically in toy models and empirically in SAEs trained on LLMs like Gemma-2-2b & Llama-3.2-1b. We also introduce "hedging degree," a metric to quantify hedging in SAEs. Our results show hedging is much worse for narrower SAEs.

1
0
0
4/9: 🔍 Hedging vs. Absorption:. Hedging: Caused by MSE loss, worse in narrower SAEs, affects encoder/decoder symmetrically, needs only correlation. Absorption: Caused by sparsity, worse in wider SAEs, affects encoder/decoder asymmetrically, needs hierarchical features.
1
0
0
3/9: 🤯 This is a big deal for LLM SAEs:. LLM SAEs are almost certainly narrower than the true number of underlying features, and features in LLMs are highly likely to be correlated. Thus, feature hedging is likely the norm, not the exception!.
1
0
0
2/9: 🤔 What's Feature Hedging? When an SAE doesn't have enough 'space' (latents) for all underlying true features, and these features are correlated, MSE loss makes it 'hedge' by mixing components of correlated features into its learned latents, destroying monosemanticity.
1
0
0
1/9: 🚀 New Paper! "Feature Hedging: Correlated Features Break Narrow Sparse Autoencoders". We find an SAE problem called "feature hedging." If an SAE is too narrow and features are correlated, features get merged, harming the SAE. But there is hope!🧵. #AI #LLMs #mechinterp

1
0
10
RT @DanielCHTan97: 🧭 When do Steering Vectors actually work for AI alignment? We conducted the first large-scale study testing their effect….
0
5
0
We show feature absorption in toy models, and show absorption can be solved by tying the SAE encoder and decoder together. Really excited for this work with @JBloomAus, @hrdkbhatnagar, @TomasDulka, and James Wilken-Smith. Blog post:

0
5
11
RT @JBloomAus: 0/8 I’m super excited about work done by my LASR scholars @chanindav, @TomasDulka, @hrdkbhatnagar and James Wilken-Smith. Th….
0
14
0
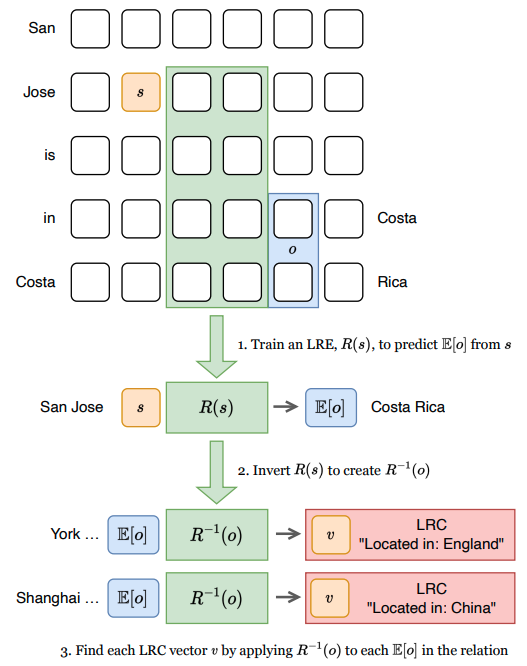
Excited to present our paper "Identifying Linear Relational Concepts in Large Language Models" at #NAACL2024 in 🇲🇽 Mexico City! Come check out the talk this Wednesday at 9am in the Interpretability and Analysis track.

1
4
32
Excited to share that our paper "Identifying Linear Relational Concepts in LLMs" with @oanacamb and Anthony Hunter has been accepted to #NAACL2024! Details 👇. Paper: Code: See you in Mexico! 🇲🇽. #XAI #MechanisticInterpretability
0
7
27
Introducing Steering Vectors, a Python library for training and applying steering vectors to control LLM behavior inspired by CAA from @NinaRimsky et al. It should work out-of-the-box with any Huggingface LM. Give it a try - Feedback/PRs welcome!.
github.com
Steering vectors for transformer language models in Pytorch / Huggingface - steering-vectors/steering-vectors
0
0
3
🤔 Can we find concepts in large language models more effectively than using probing classifiers? Yes!. 💡In our new work with @oanacamb and Anthony Hunter, we find concept directions in #LLMs that outperform SVMs. 🔗 #XAI #MechanisticInterpretability

1
1
10
0
35
0
How we use Flux with Rest at Quizlet @floydophone @sebmarkbage is this a good idea or an abomination?.
0
0
0
RT @quizlet: Watch our lead Android engineer, Arun, talk about UI challenges faced in building Android Create Set! http://t.co/WBPtP3n0JX @….
0
3
0