

bycloud
@bycloudai
Followers
8K
Following
4K
Media
627
Statuses
1K
I make youtube vids on cool AI research /// AI papers newsletter https://t.co/Xn7GMDbQSd /// paper recap @TheAITimeline /// building @findmypapersAI
Joined January 2020
I shipped something cool. findmypapers (dot) ai. A semantic search engine for 300k+ AI research papers. outcompete SoTA Deep Research apps at finding relevant research papers for you. more demos👇
18
34
312
the grok-3 benchmark is pretty useful in comparing base models, so I added GPT-4.5

185
227
2K
I got a great trailer for yall



27
147
1K
Claude 3.7 is cool, but i still ended up using grok-3 somehow. something's off about claude 3.7 and I just cant pinpoint why.
98
19
874
someone has finally done it .test time compute + diffusion models.a really interesting one for sure 🧵

10
91
830

no model is able to escape the 66% accuracy @ 120k tokens, except Gemini 2.5 Pro which sits at 90%. even the new GPT-4.1 with 1 mil ctx is stuck at 60%. (please tells us your secret gemini🥺).

Long Context benchmark updated with GPT-4.1. Looks like it's the "optimus" version instead of the better performing original quasar. The smaller versions are not usable in long context.

40
64
805
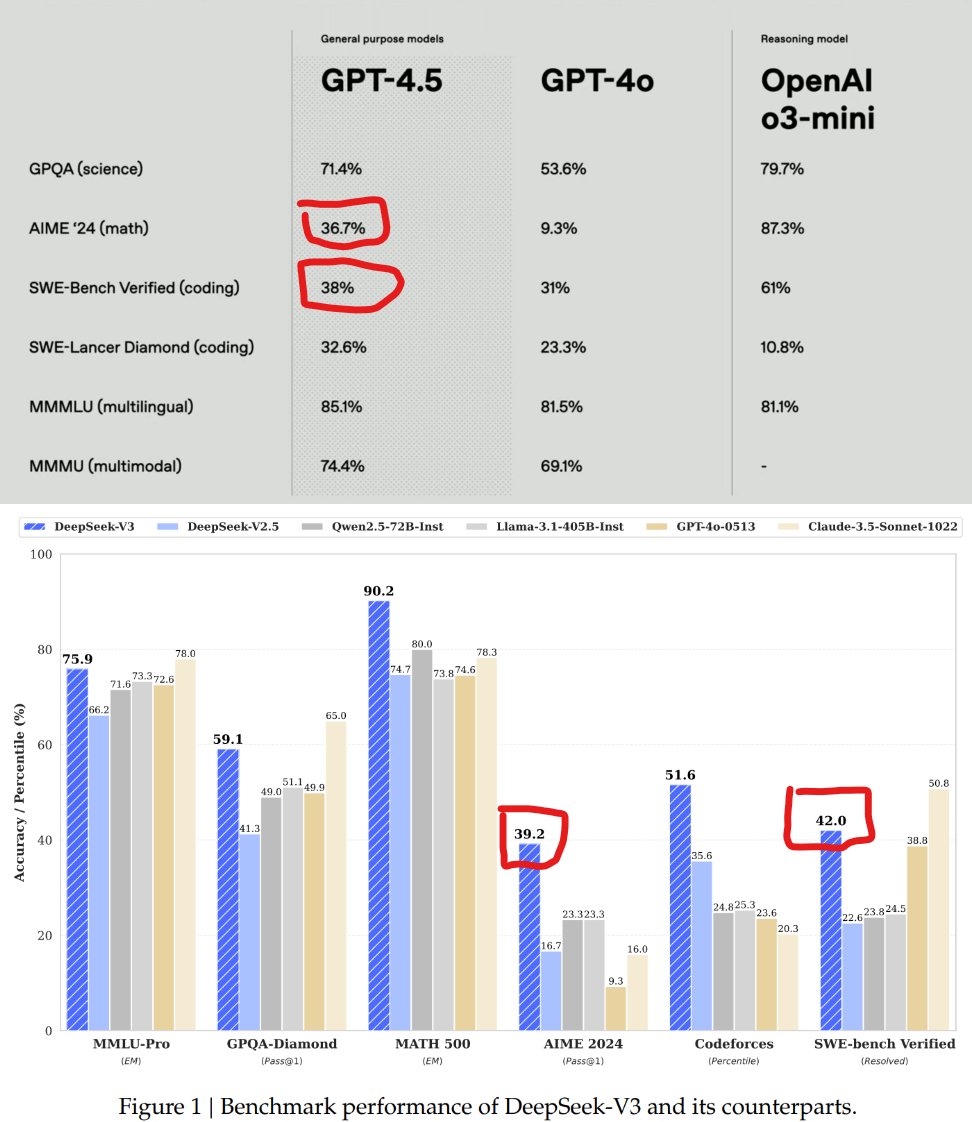
how does DeepSeek V3 win against GPT-4.5? (NOT R1 btw). openAI claimed that GPT-4.5 is a VERY big model, yet GPT-4.5 falls short compared to DeepSeek-V3. What.
72
54
707
super interesting read. maybe we just need to find the rules that are class 4 equivalent when generating synthetic data to get better performance on reasoning. making a video on this now😳

15
52
591
what also intrigued me about this is that @ 120k context window, 2.5 pro did a 90% accuracy while no one else crossed 66% . everyone else starts to fall off hard @ 4k. what new attention technique did google invent???.(and why is there a sudden dip at 16k???????)


small tangent - people always ask about gemini context window, yeah it’s big, it probably uses some sliding window-like architecture too (don’t quote me). most notably though, google has it’s own proprietary accelerators called TPUs. much more GPU memory, so they can fit larger.
30
39
558
Gemini Diffusion is my fav GoogleIO announcement. vibe coding at 1000tok/s hits different.multi-turn looks good so far.(no video speedup or anything). insanely bullish on diffusionLM
18
39
486
Due to some very kind sponsors. TOTAL PRIZE HAS JUST DOUBLED📈. Chance to win from a total prize pool of $3000 USD!. AI Generated Art Competition along with my video [Details] [Submission Link] 🗓️Aug 7th

21
82
333



We are living in a timeline where a non-US company is keeping the original mission of OpenAI alive - truly open, frontier research that empowers all. It makes no sense. The most entertaining outcome is the most likely. DeepSeek-R1 not only open-sources a barrage of models but

3
18
212
while we are still waiting for the codes for Animate Anyone, here's a quick run down on how it's this good 😎👇
4
24
207
> llama-4 series got 0% on ARC-AGI 2.> scout got 0.5% and maverick got 4.38% on ARC-AGI 1

Llama 4 Maverick and Scout on ARC-AGI's Semi Private Evaluation. Maverick:.* ARC-AGI-1: 4.38% ($0.0078/task).* ARC-AGI-2: 0.00% ($0.0121/task). Scout:.* ARC-AGI-1: 0.50% ($0.0041/task).* ARC-AGI-2: 0.00% ($0.0062/task)

9
6
189
Mamba but it's a lobotomy kaisen edit . here's the actual link for my mamba video tho.
12
20
167
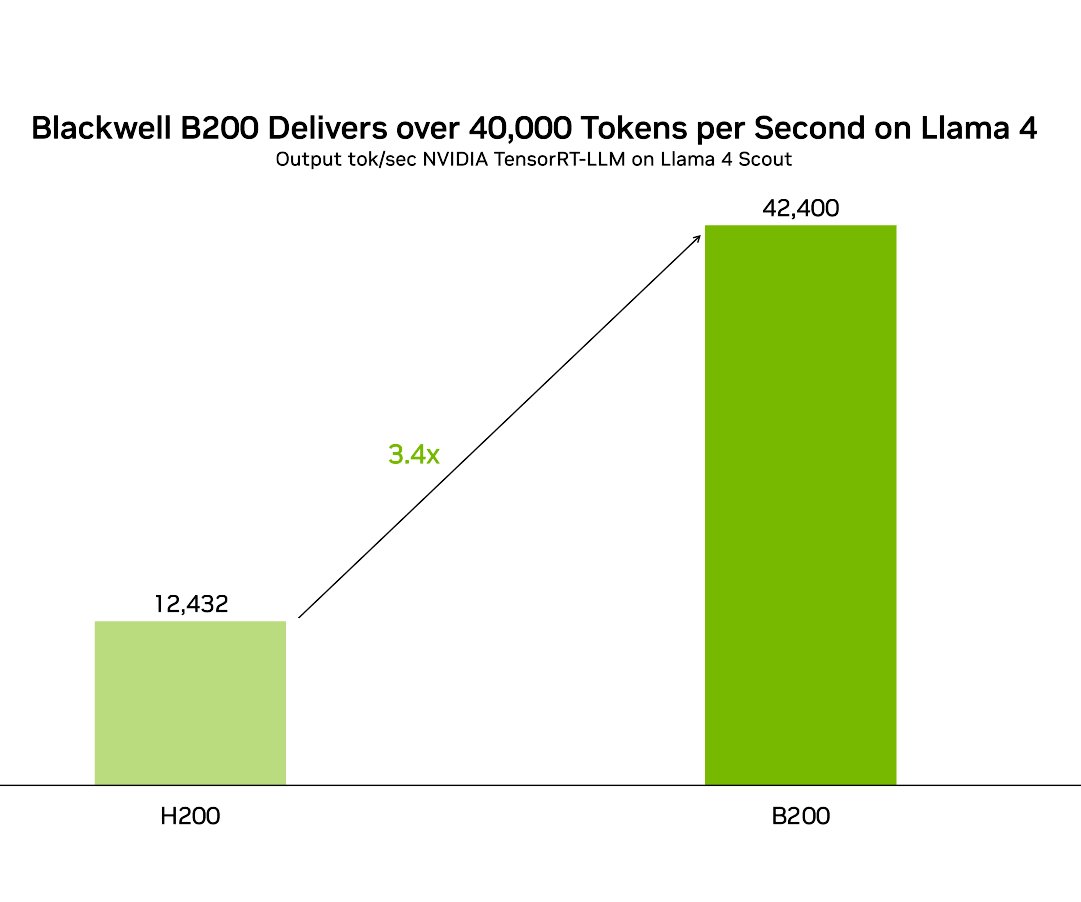
the speed is like generating a harry potter book in 2 seconds 💀.

👀 Accelerate performance of @AIatMeta Llama 4 Maverick and Llama 4 Scout using our optimizations in #opensource TensorRT-LLM.⚡. ✅ NVIDIA Blackwell B200 delivers over 42,000 tokens per second on Llama 4 Scout, over 32,000 tokens per seconds on Llama 4 Maverick. ✅ 3.4X more
4
5
159
We had image generation copying LLM. and now the reverse??. DiffusionLM -> Masked Diffusion Model is an interesting one, and here is some end of year copium.

7
12
156
omg gemini 2.5 pro pricing doesnt cost a kidney.shows that SoTA wouldn't need to ask for $600

5
4
153
sooooo are we gonna talk about how at least 50% of the research is done by chinese researchers & a lot of them are from local chinese labs?. and a lot of them are written in complete fluent english?. imagine the amount of knowledge in chinese that we are missing out.
17
5
146
no paper, empty github, project page that is unpublished which contained technical details. bruh. please don't normalize this, it's just embarassing




Tencent presents GameGen-O. Open-world Video Game Generation. We introduce GameGen-O, the first diffusion transformer model tailored for the generation of open-world video games. This model facilitates high-quality, open-domain generation by simulating a wide array of game engine
4
14
144

just want to let you know that my AI newsletter is back online! .It covers top AI research papers from previous week and explained them simply. My goal:.- let you comprehend an AI paper's impact EASILY & FAST.- explained with images .- not noisy . perfect for AI enthusiasts😎
9
11
116



I drew it so the bar might be off by a tiny bit. would be interesting to see across more benchmarks ngl but im editing rn


@bycloudai Add Claude 3.7.
8
6
104

> be me.> about to launch my first app ever.> weeks of prep, hyped myself through the roof.> accept that failure is likely, still hyped anyway.> ready to announce to the world.> *deep breath*.> find out brand account on X got banned day b4.> bruh_face.gif.> speedrun fail any%

12
1
103


Within 24 hours, we got:.Google - Gemini 1.5 Pro.Meta - V-JEPA.OpenAI - Sora.Mistral - Next. @DrJimFan is NVIDIA really not cooking anything?👀.
6
15
96
or. everyone’s hard drive??? maybe?.

goodbye, GPT-4. you kicked off a revolution. we will proudly keep your weights on a special hard drive to give to some historians in the future.
1
3
97
While DeepSeek gave incredible insights on tackling test-time compute, also coincidentally proved similar points, that's ALSO published today:. Simple RL > complex search (goodbye MCTS & PRM??). We are actually eating good tn🧵

4
7
97
Today, I will be taking a step back as a content creator on YouTube. Instead, I'll be chasing my dreams and focusing on my own AI SaaS, on top of moving to the city of AI: San Francisco, in hopes of getting into YC . Please wish me luck. I shall return with a product demo

19
0
93

it's not really "AGI" when u have to RL it for literally every use case tho. I think it's better depicted with "RL is just the key to integrate powerful LLM/AI into anything".

RL is the key to AGI. Or as OpenAI says: AGI is an operational problem now
17
3
92
damn I've been skillmaxxing with gemini 2.5 series lately, im ngmi ig . but at least my wallet will make it.
if you are not skillsmaxxing with o3 at minimum 3 hours every day, ngmi.
3
0
92
🚨OpenAI just announced GPT-4.1 non-reasoning model series tailored to devs, available through API. GPT-4.1 .GPT-4.1-mini.GPT-4.1-nano. their FIRST ever 1M context window model!. looks incredibly at coding for a non-reasoning model too



7
6
88
they are just aura farming at this point.


2
1
96
I can envision the future generation where they just don't know how to socialize anymore. We probably only need 1 year to perfect the voices too. ChatAnything: FaceTime Chat With LLM-Enhanced Personas.
5
18
82
Img2Img video generation is taking the main seat for coherent and consistent video generation. there is so much potential right now that it can probably bring an unprecedented effect onto short form content. check out my video and my thoughts here:

4
16
77
now the Will Smith text-to-video benchmark is complete with the addition of ground truth ✨.

1
7
74


One of the best new multi-modal LLM called Qwen-VL was released a few days ago, but deleted their models right after they published their finetune codes. Wth is happening 🧐




5
6
72
rip open source, SD3 might actually never see the light, and probably going to be locked behind API forever to fix their finance 😔.

An announcement from Stability AI:
7
4
71
After all the hype with 3D Gaussian Splatting, how is it really different from NeRF and why do people say it's so much better?. To find out, check out my latest video (9 mins) about what 3D Gaussian Splatting really is, and how NeRF might be replaced🧐.

1
8
72
if you don’t know, NVDA is currently having a chinese new year sale of up to 16% off!

1
1
70
probably one of the most insane breakthrough from openai on multimodal model rn but everyone's been using it to generate ghibli 😭.
5
2
71

I am only SLIGHTLYYYY late to the news .38 days late is not too bad right? . This video has been in production for way too long and I will go rest now (regarding to my last tweet lol)

1
13
66
ngl i feel like hardcoding word filters to guardrail LLMs is better than hardcore RLHF and give it brain damage.
7
6
70
after using like 10m tokens across API calls from anthropic, openai, and deepseek. deepseek is my new favorite model and I am making a video about it.
9
2
67

fuck it, a second video.

4
5
62

thanks for the support my fellow homies💀

AI generated videos are actually getting out of hand . hope yall like my intro💀

4
1
55
> mamba-transformer hybrid reasoning model near on par with DeepSeek-R1. what.

🚀 Introducing Hunyuan-T1! 🌟. Meet Hunyuan-T1, the latest breakthrough in AI reasoning! Powered by Hunyuan TurboS, it's built for speed, accuracy, and efficiency. 🔥. ✅ Hybrid-Mamba-Transformer MoE Architecture – The first of its kind for ultra-large-scale reasoning.✅ Strong


2
3
56

i got UNBANNED???. I did not know that is possible holy shit. W in the chat

> be me.> about to launch my first app ever.> weeks of prep, hyped myself through the roof.> accept that failure is likely, still hyped anyway.> ready to announce to the world.> *deep breath*.> find out brand account on X got banned day b4.> bruh_face.gif.> speedrun fail any%
5
1
56
A small AI Generated Art Competition along with my most recent video Chance to win from a total prize pool of $1500+ USD!. [Details] [Submission Link] #AIart #discodiffusion #midjourney #AiArtwork #aiartist

5
6
52
time to jump ship again after 35 days 🫡


anthropicbros. not like this.
2
1
52
Meta AI did something WILD again. wtf is Next Concept Prediction?.

3
3
53
They are stuck giving compute to cursor


deepseek caught up faster than I expected. sick af. one question though - where THE FUCK is Anthropic?.
1
5
52

GPT-4 image understanding capabilities, taken from its paper. - understanding memes.- solving math questions with diagrams.- explaining/summarizing academic papers from images.- explain irl image understanding of objects and realize that its VGA outside but lighting cable inside




2
8
46
it's time to cook


I’m excited to share a project I’ve been working on for over a year, which I believe will fundamentally change our approach to language models. We’ve designed a new architecture, which replaces the hidden state of an RNN with a machine learning model. This model compresses

4
3
50
big updates in last 2 days:.- DeepSeek-V3-0324 released (SoTA OS model).- Reve Image released (SoTA image gen?).- Gemini-2.5-Pro released (new SoTA LLM?).- GPT-4o image gen released (the actual SoTA image gen + editing???).- ARC-AGI 2 that's actually REALLY hard?.what else?.
3
2
52
WE GOT MAMBA-2 THIS SOON?????????. by Tri Dao and Albert Gu. the same authors for mamba-1.and Tri Dao is also the author for flash attention 1 & 2. will read the paper later and update y’all 😎

3
7
50
humor is also a strong signal of intelligence and an ever evolving concept, it should be an incredible benchmark to measure intelligence for AGI/ASI.
2
0
51


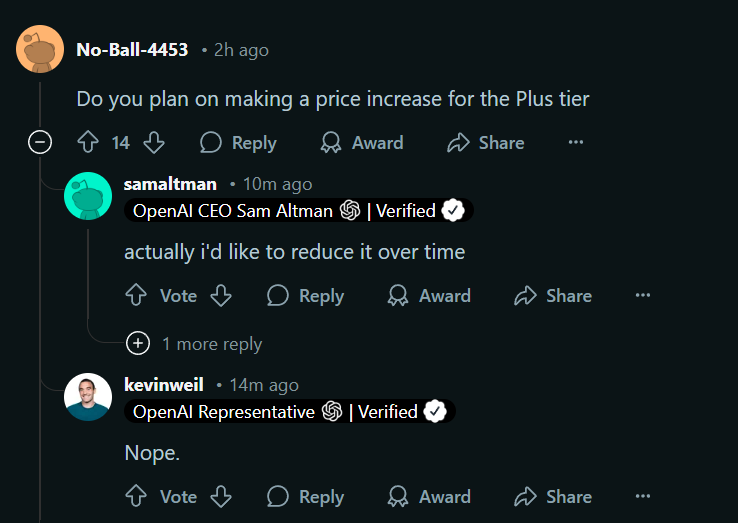
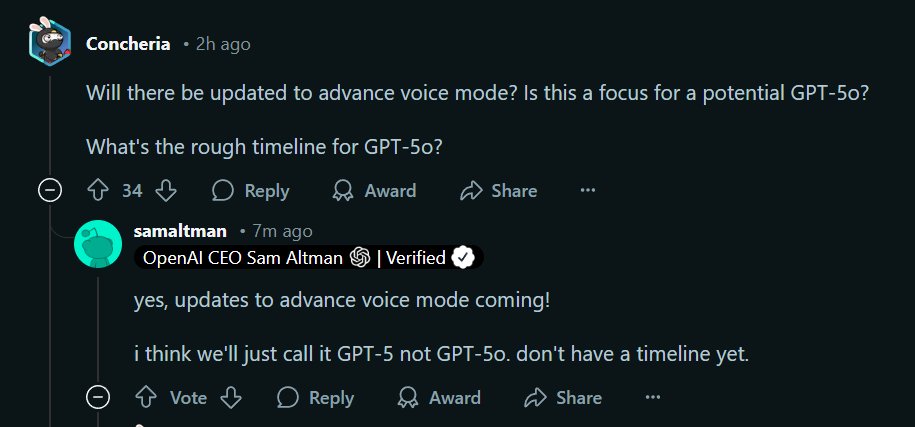
reddit Q&A from OpenAI. for chatgpt plus users ($20), the limit is.o1: 50 msgs/week.o3-mini-high: 50 msgs/week.o3-mini: 150 msgs/day. and no plan to increase price over time, might even decrease. no news about gpt-5

5
3
46
While we still need to take demos with a grain of salt, but here's Claude 3.5 Sonnet making a game😳. and apparently its better than GPT-4o AND FREE



3
6
46
IT'S ABOUT TO BE LEGANDARY.(just give me a week to edit😭). (this is 100% a signal for help, if u edit, pls slide into my dm)

4
1
46

👑Most Popular AI Research July 2022👑. Measured based on total Twitter likes!.#ArtificialIntelligence #MachineLearning

4
5
47
if it cannot look at my handwritten math and convert it into latex code, it ain’t AGI.
7
2
48
As im also making a video on model distillation, this is probs one of my favorite paper this week. So u basically distill a transformer into a mamba and it can "retain" its original capabilities. This performs best on benchmarks compared to any "existing" RNN attn hybrid. cope?.

The Mamba in the Llama: Distilling and Accelerating Hybrid Models. Author’s explanation:. Overview:.This work shows that large Transformer models can be distilled into linear RNNs, like Mamba, using a fraction of their attention layers while maintaining

1
4
47
Have you heard of Diffusion Transformers? Seems like the current meta for media synthesis 🤔. OpenAI's Sora uses it.Stable Diffusion 3 uses it. here's a closer look at this DiT bad boy.

4
5
47
Claude 3.7 Sonnet is now live. At least Anthropic is consistent at naming things

1
0
45


Grok-3 Beta (Think) wins on AIME 2024, 2025 & GPQA Diamond ($3/$15). o3 wins on aider polyglot, but most expensive ($10/$40 ). Gemini is still the best on 1M context tho and that's their moat ($1.25/$10). P.S. AIME 2024 & 2025 can be contaminated VERY easily, grain of salt pls

1
4
46
Disney's new animation research is sickkk. Factorized Motion Diffusion for Precise and Character-Agnostic Motion Inbetweening. This approach combines a character-agnostic Bézier Motion Model (BMM), trained on large motion datasets, with a character-specific posing model optimized
2
8
44


Claude 3.7 Sonnet is now live. At least Anthropic is consistent at naming things
0
2
45
as a token of appreciation from me, here's a meme for you o7


Interesting how the final message upon winning this CTF contains no thank you, no congratulations, no confetti animation, no coupon for a Golden Gate Claude t-shirt. Just: "Back to the datamines, pleb!".
4
4
45
This bonker of a week all started with deepseek-v3 shipping a 0324 out of nowhere.
3
0
44
POV: the last thing you see before you get fired.

#ChatDirector is a research prototype that brings 3D avatars and automatic layout transitions to your 2D laptop screen, transforming online meetings to be more immersive and dynamic. Check it out →
1
2
43
1) what.

Introducing Samba 3.8B, a simple Mamba+Sliding Window Attention architecture that outperforms Phi3-mini on major benchmarks (e.g., MMLU, GSM8K and HumanEval) by a large margin.😮 And it has an infinite context length with linear complexity.🤯. Paper:

4
4
44
the selling point of the product is now “watch us burn more GPU runtime” because no normies can tell the difference between a $200 a $2000 and a $20000 tier. but unfortunately more runtime ≠ better answers and once normies realize that, the “bubble” will pop.

AI Agenda: OpenAI Plots Charging $20,000 a Month For PhD-Level Agents. OpenAI is planning three types of agents for which it could charge $2,000 to $20,000 a month. Read more from @steph_palazzolo and @coryweinberg👇.
5
4
44
10 Million Context Window might not just be a dream. In this video, I will be talking about How Google's "Transformer 2.0" Might Be The AI Breakthrough We Need by imitating how human memories work.

0
6
43