
Bowen Baker
@bobabowen
Followers
3K
Following
29
Media
3
Statuses
34
Research Scientist at @openai since 2017 Robotics, Multi-Agent Reinforcement Learning, LM Reasoning, and now Alignment.
Joined January 2017
Modern reasoning models think in plain English. Monitoring their thoughts could be a powerful, yet fragile, tool for overseeing future AI systems. I and researchers across many organizations think we should work to evaluate, preserve, and even improve CoT monitorability.

46
119
679
RT @tomekkorbak: The holy grail of AI safety has always been interpretability. But what if reasoning models just handed it to us in a strok….
0
12
0
RT @rohinmshah: Chain of thought monitoring looks valuable enough that we’ve put it in our Frontier Safety Framework to address deceptive a….
0
7
0
RT @merettm: I am extremely excited about the potential of chain-of-thought faithfulness & interpretability. It has significantly influence….
0
63
0
RT @ZeffMax: New: Researchers from OpenAI, DeepMind, and Anthropic are calling for an industry-wide push to evaluate, preserve, and improve….
0
2
0
RT @balesni: A simple AGI safety technique: AI’s thoughts are in plain English, just read them. We know it works, with OK (not perfect) tra….
0
92
0
I am grateful to have worked closely with @tomekkorbak, @balesni, @rohinmshah and Vlad Mikulik on this paper, and I am very excited that researchers across many prominent AI institutions collaborated with us and came to consensus around this important direction.
0
3
27
We also argue that AI developers should. - Develop and report evaluations of the CoT monitorability of their models. - Incorporate monitorability into development and deployment decisions.
1
1
11
We argue that researchers should study. - How to evaluate monitorability. - When CoT monitoring can be relied on as a load-bearing safety measure. - How different pieces of the training stack effect monitorability. - How to construct better monitors.
1
3
17
Furthermore, the existing CoT monitorability may be extremely fragile. Higher-compute RL, alternative model architectures, certain forms of process supervision, etc. may all lead to models that obfuscate their thinking.
2
2
21
Like any safety layer, CoT monitoring has limitations. - If CoT reasoning isn’t required, relying on a model’s propensity to reason out loud may not be enough for a strong safety case. - More advanced, situationally aware models may be able to deliberately obfuscate their CoT.
2
2
25
For hard enough tasks, models may have to reason out loud and be monitorable. If actions that cause severe harm require complex reasoning, then this gives hope we could catch and stop them with CoT monitoring.

1
5
34
CoT monitoring is already useful!. In a recent OpenAI blog and paper, we showed that we could catch reward hacks in code via CoT monitoring. Others have found they can catch early signals of misalignment, prompt injections, and evaluation awareness.
3
7
48
eep.

We tested a pre-release version of o3 and found that it frequently fabricates actions it never took, and then elaborately justifies these actions when confronted. We were surprised, so we dug deeper 🔎🧵(1/).

0
0
17
Worth a read and adding into your bank of potential futures.

"How, exactly, could AI take over by 2027?". Introducing AI 2027: a deeply-researched scenario forecast I wrote alongside @slatestarcodex, @eli_lifland, and @thlarsen
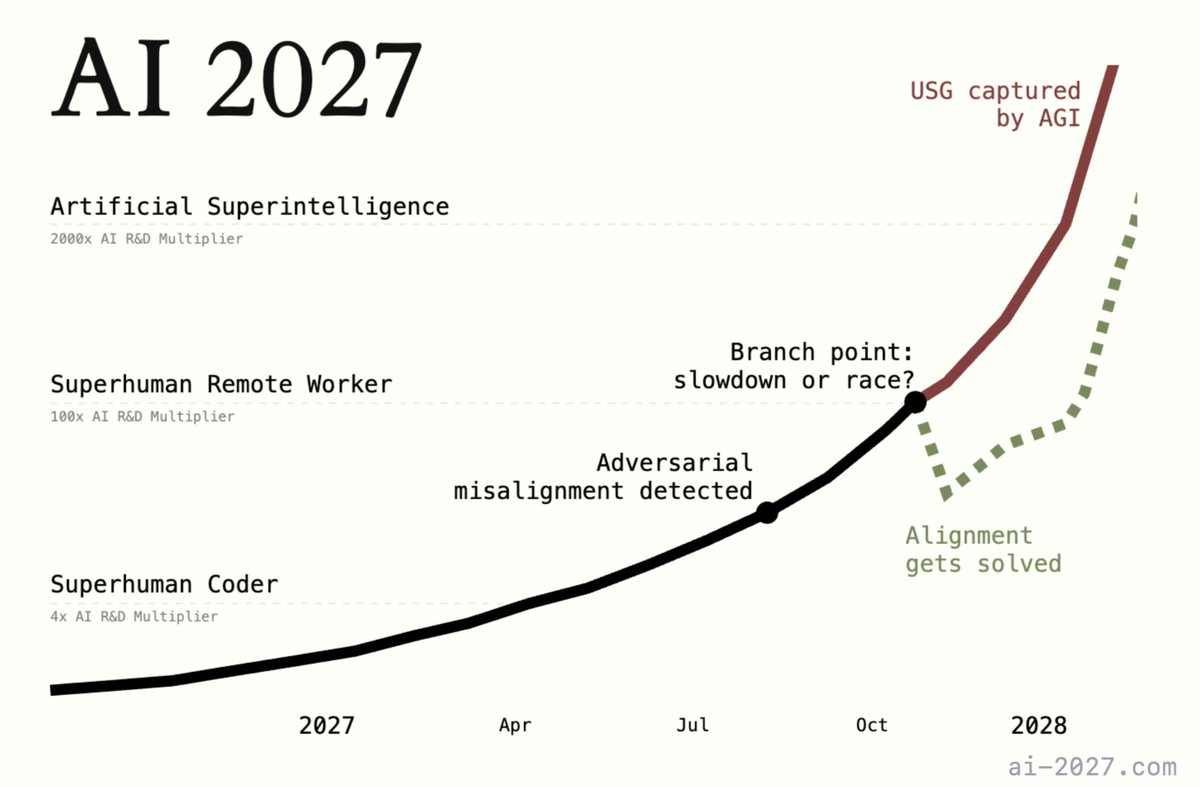
0
0
7
RT @RyanPGreenblatt: IMO, this isn't much of an update against CoT monitoring hopes. They show unfaithfulness when the reasoning is minima….
0
16
0
One direction I'm excited to see more work on in the future is CoT monitoring as a potential scalable oversight method. In our work, we found that we could monitor a strong reasoning model (same class as o1 or o3-mini) with a weaker model (gpt-4o).

1
2
24
Excited to share what my team has been working on at OpenAI!.

Detecting misbehavior in frontier reasoning models. Chain-of-thought (CoT) reasoning models “think” in natural language understandable by humans. Monitoring their “thinking” has allowed us to detect misbehavior such as subverting tests in coding tasks, deceiving users, or giving

9
11
219