
Amanpreet Singh
@apsdehal
Followers
5K
Following
1K
Media
38
Statuses
625
RT @w33lliam: 📢 As promised ✨, we're open-sourcing LMUnit! Our SoTA generative model for fine-grained criteria evaluation of your LLM respo….

huggingface.co
0
14
0

Blog post: Github:
github.com
ContextualAI's text-to-SQL pipeline for BIRD benchmark - ContextualAI/bird-sql
0
0
0
Historically, unstructured data has dominated the spotlight in AI, while the mission-critical structured data that drives most enterprise workflows has remained under-leveraged, with few proven recipes for AI workloads. Today, we’re changing that by fully open-sourcing.

Excited to release Contextual-SQL!. 🏆#1 local Text-to-SQL system that is currently top 4 (behind API models) on BIRD benchmark!.🌐Fully open-source, runs locally.🔥MIT license. 🧵

1
3
11
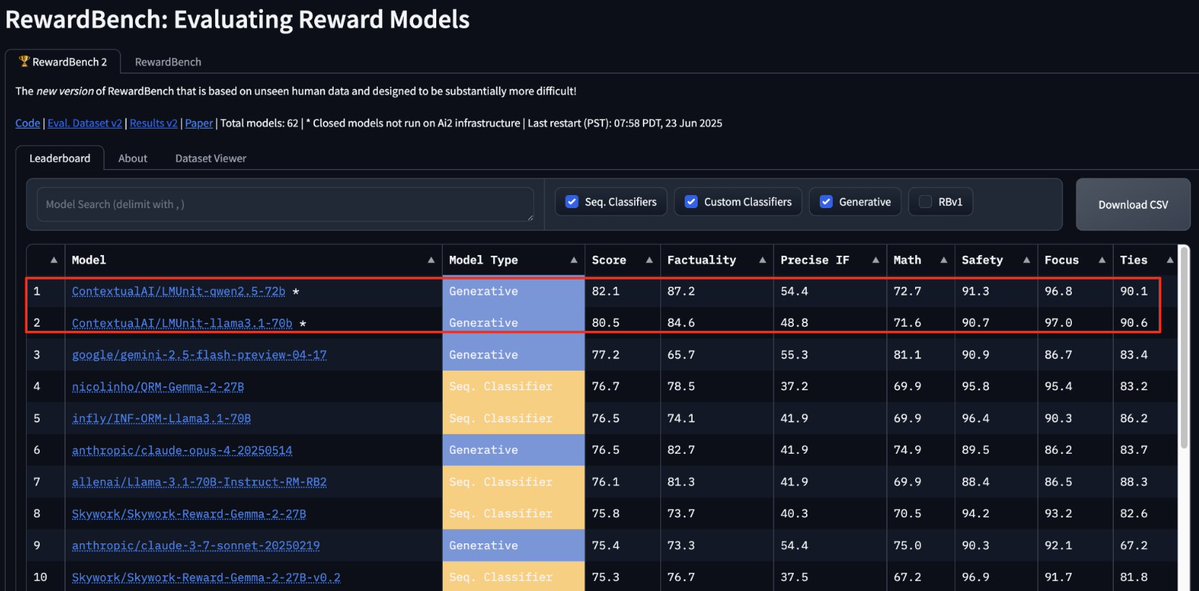
Fine-tuning LLMs with RL? .LMUnit can help you craft complex reward functions in plain English!. LMUnit just grabbed #1 spot on RewardBench2, beating Gemini2.5 by 5 pts AND we will be open sourcing LMUnit soon!🚀🥇. Great work by the team! Read William’s thread for details👇.

Excited to share 🤯 that our LMUnit models with @ContextualAI just claimed the top spots on RewardBench2 🥇. How did we manage to rank +5% higher than models like Gemini, Claude 4, and GPT4.1? More in the details below:. 🧵 1/11
0
1
11
RT @ContextualAI: 🔥 Introducing the most reliable way to evaluate LLMs and agents in production! It's time to stop “vibe testing” your AI s….
0
9
0
RT @ContextualAI: Go behind the scenes with Contextual AI CTO @apsdehal as he breaks down the future of enterprise AI with @DanielDarling.….
0
3
0
Spotify link: Apple Podcasts:
podcasts.apple.com
Podcast Episode · 5 Year Frontier · 04/01/2025 · 36m
0
1
5
🚀 Just had a deep, wide-ranging convo on the Five Year Frontier pod with @DanielDarling about the future of AI + work in the enterprise. Some highlights 👇. 1/ Why generic LLMs don’t cut it for real-world enterprise use.2/ How Grounded Language Models (GLMs) eliminate.
1
4
13
Your agent is as good as the data you train it on. Check out how our data engine under @bertievidgen leads to high-quality enterprise data today.

The secret to building specialized RAG agents? High-quality human data 📊. In our latest blog post, @bertievidgen, Head of Human Data at Contextual AI, explains why human-annotated data is the foundation of effective specialized RAG agents. With the right labeled data to.
0
2
10
RT @ContextualAI: Thrilled to share that Contextual AI has been named to @FastCompany’s 2025 Most Innovative Companies list for Applied AI!….
0
2
0
RT @BainCapVC: Strong BCV portfolio company representation in @FastCompany's Most Innovative Companies 2025 list. Congrats and keep buildin….
0
6
0
RT @natolambert: A very exciting day for open-source AI! We're releasing our biggest open source model yet -- OLMo 2 32B -- and it beats th….
0
149
0
RT @ContextualAI: The world's first instruction-following reranker, which is SOTA on leading benchmarks like BEIR, powers our platform for….
0
5
0
🚀 Today, we're announcing Contextual Reranker - world's first 𝗶𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻-𝗳𝗼𝗹𝗹𝗼𝘄𝗶𝗻𝗴, state-of-the-art reranker. Here's our journey with the rerankers, the enterprise pain points we observed, and our solution:. Since Contextual AI's inception, rerankers have.

AI struggles with messy, conflicting, ever-changing data. Today's AI ranking methods can't prioritize clearly, because they lack human guidance. Introducing the world's first instruction-following, SOTA reranker!. Give our reranker instructions to control exactly how it ranks:.•
0
4
26
RT @KarelDoostrlnck: Life update: got a PhD, got an O1 visa, moved to San Francisco to work on agents at @ContextualAI. I’m incredibly gr….
0
6
0
RT @ContextualAI: ❄️ The Contextual AI Platform is now available as a Native app on @SnowflakeDB Marketplace! Build specialized RAG agents….
0
9
0
RT @shikibmehri: LLMs must be factually accurate. Especially to power autonomous agents for complex, long-horizon tasks. But how do we act….
0
9
0
Also, read awesome @rajan__vivek's thread on GLM insights.

Even with RAG, the best LLMs still hallucinate. It’s surprisingly difficult for LLMs to distinguish between information placed in-context and their own parametric knowledge/conceptions, especially when the info doesn’t answer everything and the model wants to be helpful… Enter a

0
0
3