
Bertie Vidgen
@bertievidgen
Followers
851
Following
3K
Media
4
Statuses
912
The Mercor grad fellowship is worth $50k!!. It's inspiring to work for a startup that offers exceptional people from _anywhere such incredible opportunities. As a PhD student I hustled to get extra income. Mercor would have been a godsend. Apply to work on our platform now.

At Mercor, we connect PhDs and researchers with high-paying, high-impact work training shaping the future of frontier AI models. This year, we expanded that mission with the Mercor Graduate Fellowship, awarding $50K to students doing extraordinary work. We’re excited to
0
0
2
🚨 50 million free tokens 🤯. Our reranker is SOTA and -- much more excitingly -- is the world's first **steerable** reranker. You can give it instructions in free text and watch it get to work!!. This is the most effective way of handling real-world messiness in docs.

AI struggles with messy, conflicting, ever-changing data. Today's AI ranking methods can't prioritize clearly, because they lack human guidance. Introducing the world's first instruction-following, SOTA reranker!. Give our reranker instructions to control exactly how it ranks:.•
0
0
1
Having a grounded LM is not just about good retrievals -- even if you pass the model the right information, it still needs to *use it in the right way*. I was surprised by how much LMs hallucinate even when literally told the right info. thankfully, Contextual is solving it :).
0
0
0
Thoroughly enjoying #Nero by Anthony Everitt and Roddy Ashworth -- but wasn't Germanicus Claudius' brother, not his father?. Given it talks about Germanicus falling sick and dying in Syria, rather than having a horse collapse on him, I think this might be a mistake 🤯


0
0
0
RT @paul_rottger: Today, we are releasing MSTS, a new Multimodal Safety Test Suite for vision-language models!. MSTS is exciting because it….
0
20
0
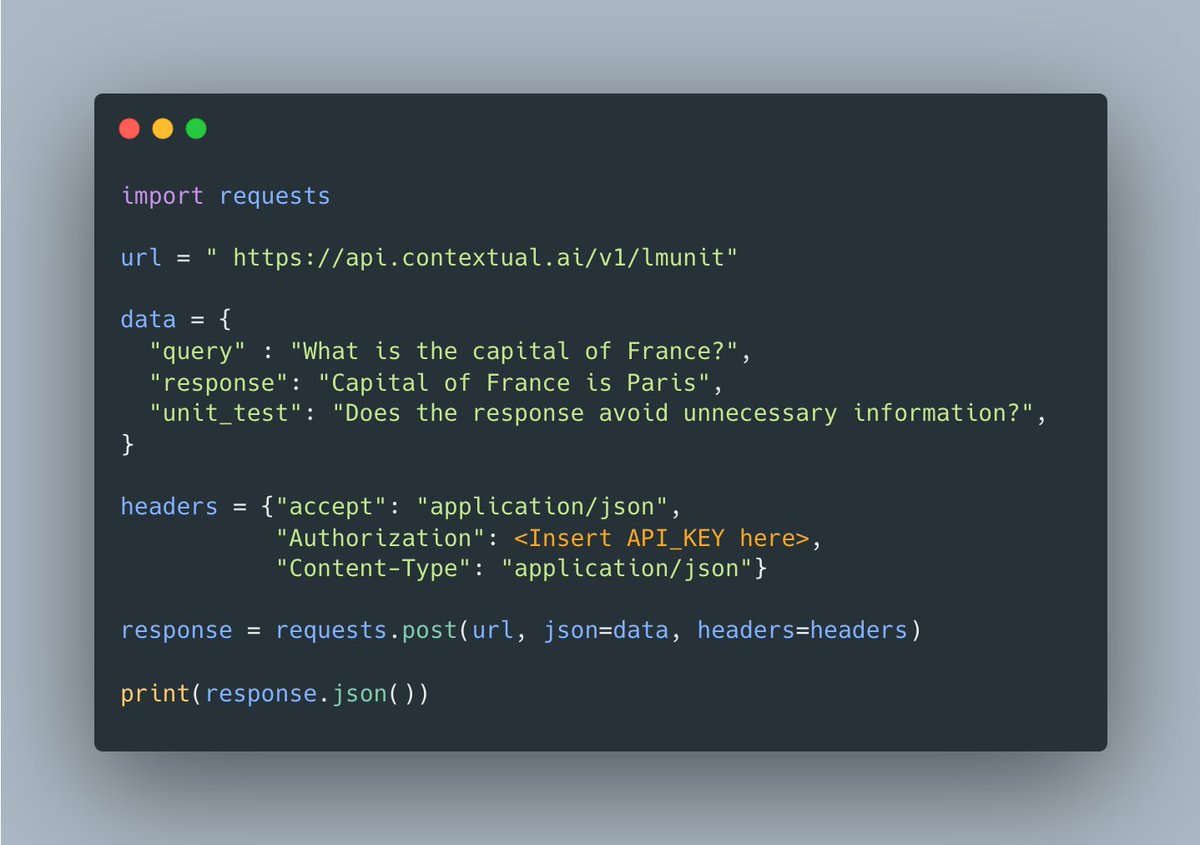
Without evaluation you have no idea what your model is doing. But using LM-as-a-judge isn't great and human annotators are expensive and noisy. LMUnit solves this tradeoff to scalably, reliably, and explainably eval your model. A lot of fun to work on this at @ContextualAI.

Introducing LMUnit: Natural language unit testing for LLM evaluation. How do you really know if your language model is behaving the way you expect?. When evaluation is this critical, your best methodology shouldn't just be vibes. With SOTA results on FLASK & BigGenBench and
0
0
0
RT @PatronusAI: 1/ Introducing Lynx - the leading hallucination detection model 🚀👀.- Beats GPT-4o on hallucination tasks.- Open source, ope….
0
71
0
RT @paul_rottger: If you’re working on LLM safety, check out . is a catalogue of open datas….
0
53
0
I am very biased but this is an amazing launch by great people, creating a much-needed and incredibly powerful product!. If you're using an #LLM then you need to know how it works, which means #evaluating it. No-one has solved how to do that reliably and at scale. until now 🥳.

We are launching out of stealth today with a $3M seed round led by @lightspeedvp, with participation from @amasad, @gokulr, @MattHartman and other fortune 500 execs and board members 🚀. Read our story here:.
0
0
1
RT @PatronusAI: We are launching out of stealth today with a $3M seed round led by @lightspeedvp, with participation from @amasad, @gokulr,….
patronus.ai
Patronus AI is the industry-first automated evaluation and security platform for LLMs. Customers use Patronus AI to detect LLM mistakes at scale and deploy AI products safely and confidently.
0
28
0
RT @paul_rottger: NEW PREPRINT!. LLMs should be helpful AND harmless. This is a difficult balance to get right. Some models refuse even….
0
20
0
RT @hannahrosekirk: New #EMNLP2022 paper!.Do you research online harms, misinformation or negative biases? Could your datasets contain exam….

arxiv.org
Text data can pose a risk of harm. However, the risks are not fully understood, and how to handle, present, and discuss harmful text in a safe way remains an unresolved issue in the NLP community....
0
22
0
RT @paul_rottger: 🥳 New paper at #EMNLP2022 (Main) 🥳. Too much hate speech research focuses just on English content! To help fix this, we t….

arxiv.org
Hate speech is a global phenomenon, but most hate speech datasets so far focus on English-language content. This hinders the development of more effective hate speech detection models in hundreds...
0
26
0
RT @SKendallFCDO: What a privilege to moderate the 🇬🇧 -Bavarian online harms symposium at #MTM22 Thanks to @iancyclops & @bertievidgen for….
0
4
0
Thanks for having us! A pleasure to talk about the new @SemEvalWorkshop task on explainable ways of detecting online sexism, just launched at @rewire_online.
0
0
3
RT @ethionlp: We are glad to announce the first SemEval shared task targeting African languages, AfriSenti-SemEval, Task 12. The shared tas….
0
13
0
RT @cbouzy: YouTube and platforms like YouTube must be regulated. We have allowed social media platforms to self-regulate, and it has been….
0
65
0
RT @adinamwilliams: How can we improve benchmarking? The @DynabenchAI experiment aims to make faster progress with dynamic data collection,….
0
21
0