

Aidan Kelly
@aidan_s_kelly
Followers
51
Following
321
Media
4
Statuses
107
Junior Data Scientist at @nesta_uk in the Sustainable Future mission | Views are my own. MSc @UvA_Amsterdam, PhD in particle physics @ucl.
London, United Kingdom
Joined August 2023

This is exciting; I expect we are going to see a lot more things like this and it will be one of the most important impacts of AI. Congrats to the Future House team. https://t.co/Cxeh8UlWdk
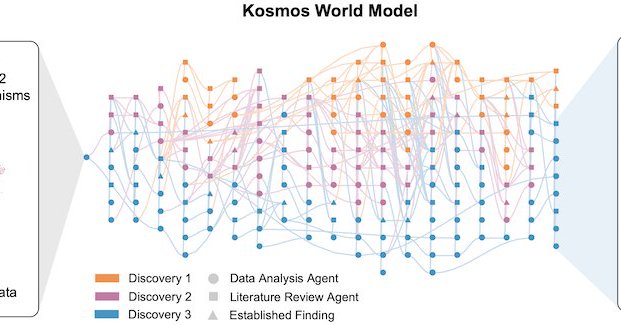
edisonscientific.com
Today, we are announcing Kosmos, our next-generation AI Scientist. Kosmos is a major upgrade on Robin, our previous AI Scientist. You can read about it in our technical report, here. Kosmos is...
841
1K
9K

most people haven’t updated on this add greg’s “any task that frontier ai can sort of do today, it’ll likely be able to do reliably one year from now” and your ability to trust the work is about to go up a lot as ilya said, reliability is the biggest bottleneck to usefulness

Am I the only one wondering how come the models hallucinate so little in 2025?
20
57
904

We’ve developed a new way to train small AI models with internal mechanisms that are easier for humans to understand. Language models like the ones behind ChatGPT have complex, sometimes surprising structures, and we don’t yet fully understand how they work. This approach

openai.com
We trained models to think in simpler, more traceable steps—so we can better understand how they work.
221
713
6K

6 months ago @Sentry acquired our company & since then I've been experimenting a lot with AI I wrote up some of my thoughts on vibe coding & dealing with "AiDHD" https://t.co/PvIVKp5esD

josh.ing
Reflecting on six months of vibe coding: building 8 projects, discovering AiDHD, and learning what AI tools can (and can't) do.
15
29
364

A common mistake that AI companies make nowadays is to not give their engineers enough time and mental calm to do their best work. Constant deadlines, pressure and distractions from daily AI news are poison for writing good code and systems that scale well. That’s why most AI
133
172
3K


The first fantastic paper on scaling RL with LLMs just dropped. I strongly recommend taking a look and will be sharing more thoughts on the blog soon. The Art of Scaling Reinforcement Learning Compute for LLMs Khatri & Madaan et al.
19
195
1K
Here's my talk on the year in open models from The Curve. This felt like one of my better talks -- uncovering a ton of information that way more people should be familiar with. I feel like I'm just scratching the surface and I'm seen as the "leading expert" here. We need more
2
27
160

This memory lane tour reminded me of a few anecdotes. Here is a quirkier, somewhat nostalgic, alternative path through the history of AI. We held a CIFAR workshop at @UofT to learn about how to use GPUs for Deep Learning. We learned a lot from @npinto. Soon after we had the

This is an excellent history of LLMs, doesn't miss seminal papers I know. Reminds you we're standing on the shoulders of giants, and giants are still being born today.
14
14
134

Karpathy’s thinking is sublime it goes without saying Yes, ghosts in the machine and from the machine. They are missing billions of years of evolution. Will robots help ground them? Maybe I am very bullish on what LLMs are and will become by 2030 even if they “need several

Hah judging by mentions overnight people seem to find the ghost analogy provocative. I swear I don't wake up just trying to come with new memes but to elaborate briefly why I thought it was a fun comparison: 1) It captures the idea that LLMs are purely digital artifacts that
0
7
76
Tinker is cool. If you're a researcher/developer, tinker dramatically simplifies LLM post-training. You retain 90% of algorithmic creative control (usually related to data, loss function, the algorithm) while tinker handles the hard parts that you usually want to touch much less

Introducing Tinker: a flexible API for fine-tuning language models. Write training loops in Python on your laptop; we'll run them on distributed GPUs. Private beta starts today. We can't wait to see what researchers and developers build with cutting-edge open models!
110
654
6K
Finally had a chance to listen through this pod with Sutton, which was interesting and amusing. As background, Sutton's "The Bitter Lesson" has become a bit of biblical text in frontier LLM circles. Researchers routinely talk about and ask whether this or that approach or idea

.@RichardSSutton, father of reinforcement learning, doesn’t think LLMs are bitter-lesson-pilled. My steel man of Richard’s position: we need some new architecture to enable continual (on-the-job) learning. And if we have continual learning, we don't need a special training
430
1K
10K
LoRA makes fine-tuning more accessible, but it's unclear how it compares to full fine-tuning. We find that the performance often matches closely---more often than you might expect. In our latest Connectionism post, we share our experimental results and recommendations for LoRA.
82
566
3K


Another impressive paper by Google DeepMind. It takes a closer look at the limits of embedding-based retrieval. If you work with vector embeddings, bookmark this one. Let's break down the technical details:
36
231
2K

I was using Claude Code wrong... Here’s what I learnt and how I maximise Claude Code performance + Best tips that ACTUALLY useful 👇 Thread below
61
260
3K

few underrated yt channels (or rather super niche rn) i have been watching on/off to understand gpu programming basics cuda mode - various lectures including inference optimisation 0mean1sigma - nice animation tunadorable - triton kernel focused simon oz - nice explanations
8
29
314
Here you go — 1. Transformers - Visual intro to Transformers (3b1b) [YouTube] -nanoGPT & tokenization (Karpathy) [YouTube] -Decoding strategies in LLMs (Maxime Labonne) [GitHub] 2. Pre training -Distributed training techniques (Duan et al.) [Paper] -nanotron: Minimal

I’ve seen a ton of devs struggling to pivot to AI lately and here’s what you can try to get more theoretical especially in LLMs: 1. Transformers Architecture, tokenization, attention mechanisms, sampling techniques 2. Pretraining Data prep, distributed training, optimization
16
138
1K

Noticing myself adopting a certain rhythm in AI-assisted coding (i.e. code I actually and professionally care about, contrast to vibe code). 1. Stuff everything relevant into context (this can take a while in big projects. If the project is small enough just stuff everything
462
1K
12K