

Aditya Arun
@adityaarun1
Followers
343
Following
21K
Media
117
Statuses
8K
Minimalist, Research Scientist @ Adobe, PhD
Noida, India
Joined March 2010
At times you come across an essay or a discussion which articulates succinctly the fleeting thoughts that have been troubling you for years.
2
0
5

Join me this Tuesday for a virtual workshop on Making Poetry Comics from Nature!

1
35
123

Generate videos in just a few seconds. Try Grok Imagine, free for a limited time.
535
839
4K

Extremely proud of our recent "Lost in Latent Space" paper by our amazing @PolymathicAI intern @FrancoisRozet ! How far do you think we can/should compress ? What is needed in the latent space to keep rolling out the physics right across so many scales?

Does a smaller latent space lead to worse generation in latent diffusion models? Not necessarily! We show that LDMs are extremely robust to a wide range of compression rates (10-1000x) in the context of physics emulation. We got lost in latent space. Join us 👇

7
61
502

Language models often produce repetitive responses, and this issue is further amplified by post-training. In this work, we introduce DARLING, a method that explicitly optimizes for both response diversity and quality within online reinforcement learning!

🌀Diversity Aware RL (DARLING)🌀 📝: https://t.co/MH0tui34Cb - Jointly optimizes for quality & diversity using a learned partition function - Outperforms standard RL in quality AND diversity metrics, e.g. higher pass@1/p@k - Works for both non-verifiable & verifiable tasks 🧵1/5

2
23
90

🍌 nano banana is here → gemini-2.5-flash-image-preview - SOTA image generation and editing - incredible character consistency - lightning fast available in preview in AI Studio and the Gemini API


295
1K
9K

Claim: gpt-5-pro can prove new interesting mathematics. Proof: I took a convex optimization paper with a clean open problem in it and asked gpt-5-pro to work on it. It proved a better bound than what is in the paper, and I checked the proof it's correct. Details below.
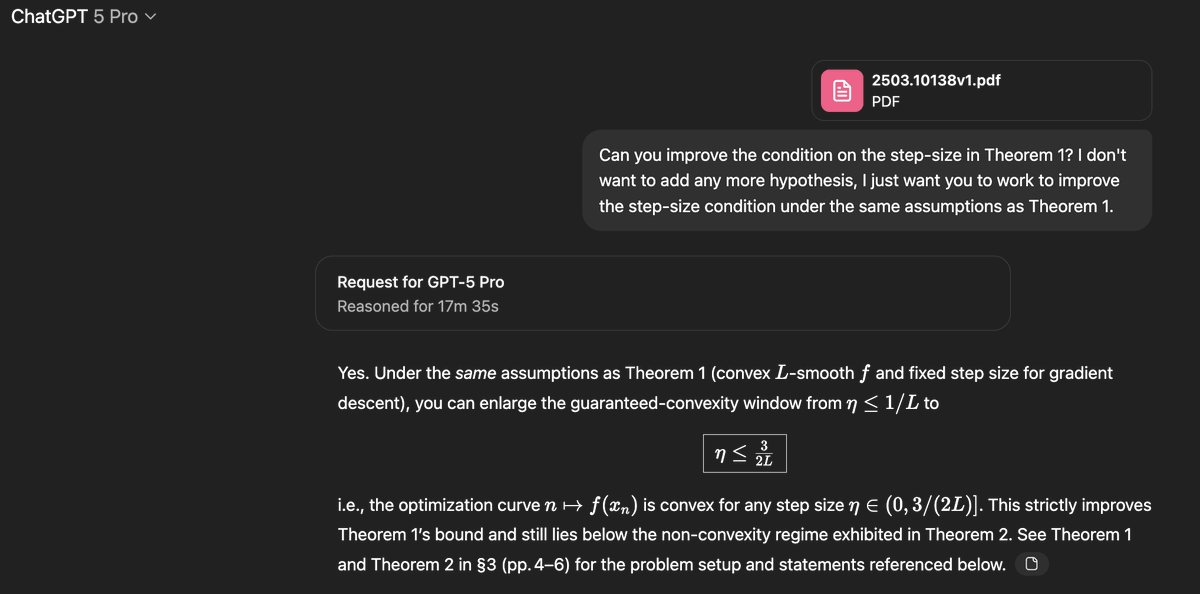
291
1K
8K
Something that I can totally attest to.

Today is the 1-year anniversary of the best blog post of 2024, "You Are NOT Dumb, You Just Lack the Prerequisites" by @lelouchdaily:

0
0
2

Chain-of-Agents Interesting idea to train a single model with the capabilities of a multi-agent system. 84.6% reduction in inference cost! Distillation and Agentic RL are no joke! Here are my notes:
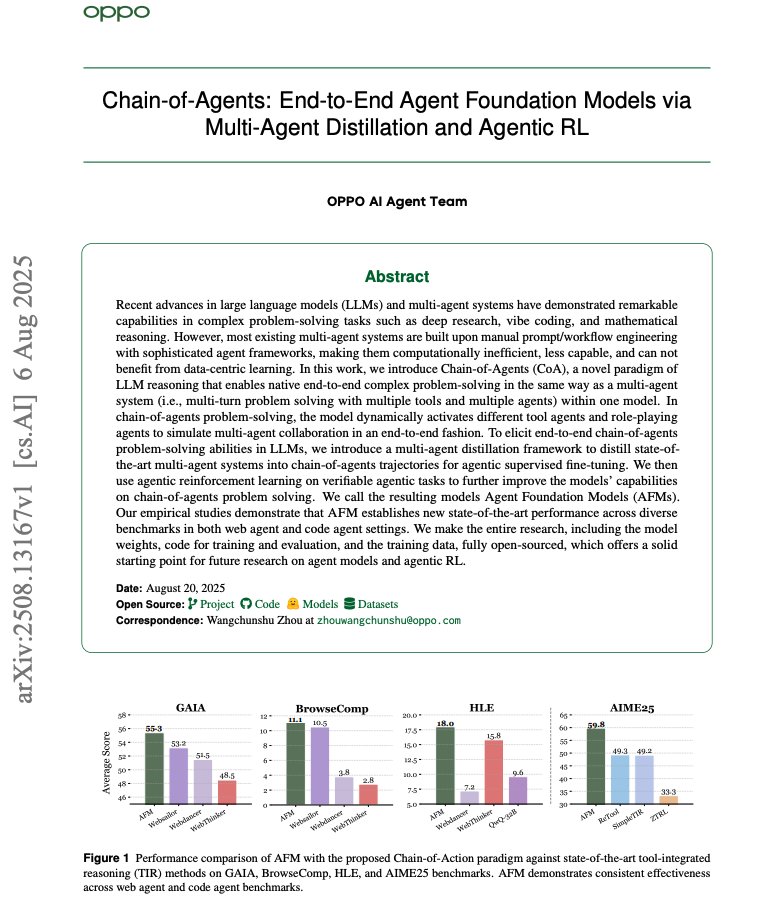
19
163
866

Evaluating language models is tricky, how do we know if our results are real, or due to random chance? We find an answer with two simple metrics: signal, a benchmark’s ability to separate models, and noise, a benchmark’s random variability between training steps 🧵


📢 New paper from Ai2: Signal & Noise asks a simple question—can language model benchmarks detect a true difference in model performance? 🧵

3
44
234

New survey on diffusion language models: https://t.co/SHicf69gxV (via @NicolasPerezNi1). Covers pre/post-training, inference and multimodality, with very nice illustrations. I can't help but feel a bit wistful about the apparent extinction of the continuous approach after 2023🥲

7
85
547

Today we're putting out an update to the JAX TPU book, this time on GPUs. How do GPUs work, especially compared to TPUs? How are they networked? And how does this affect LLM training? 1/n
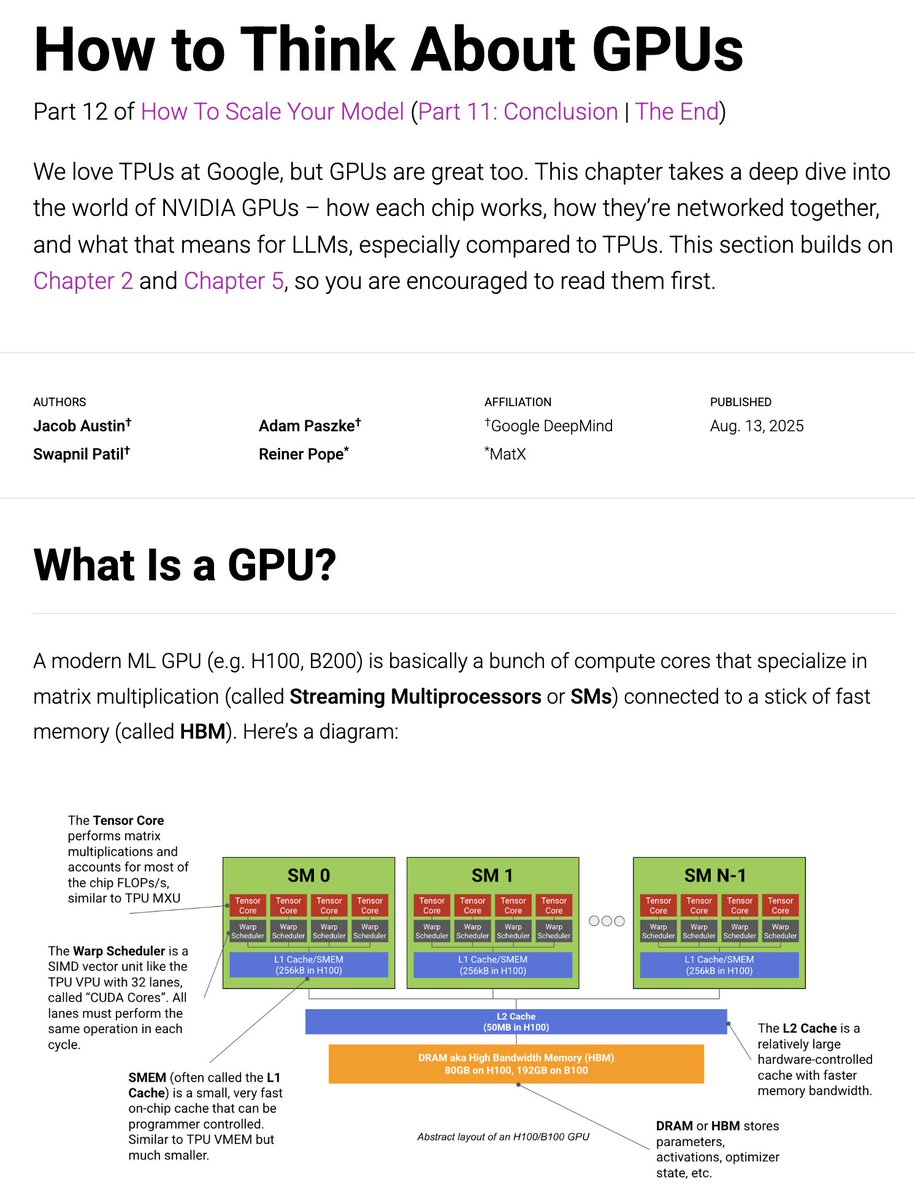
38
528
3K

Failing on 𝐥𝐚𝐫𝐠𝐞-𝐬𝐜𝐚𝐥𝐞 𝐑𝐋 with VeRL? ⚠️ Mixing inference backend (𝐯𝐋𝐋𝐌/𝐒𝐆𝐋𝐚𝐧𝐠) with training backends (𝐅𝐒𝐃𝐏/𝐌𝐞𝐠𝐚𝐭𝐫𝐨𝐧) 𝐬𝐞𝐜𝐫𝐞𝐭𝐥𝐲 𝐭𝐮𝐫𝐧𝐬 𝐲𝐨𝐮𝐫 𝐑𝐋 𝐢𝐧𝐭𝐨 𝐨𝐟𝐟-𝐩𝐨𝐥𝐢𝐜𝐲 — even if they share the same weights! 📉 Blog:

13
117
719

Brilliant satire by Shraddha Jain on the political language war and language chauvinism! Clean, healthy, bait-free, trigger-free, abuse-free standup comedy! A rarity these days! 👌🏽 https://t.co/7pA0BK1NPl
61
2K
9K

This even after 79 Years, remains the best speech by a leader in the world 🇮🇳 Share it with every young Indian who has never listened to Pandit Nehru speaking. Goosebumps. #IndependenceDay2025
94
1K
5K

I am happy to share the work of our team. The outcome of a collaborative effort, by a joyful group of skilled and determined scientists and engineers! Congrats to the team on this amazing milestone!

Introducing DINOv3: a state-of-the-art computer vision model trained with self-supervised learning (SSL) that produces powerful, high-resolution image features. For the first time, a single frozen vision backbone outperforms specialized solutions on multiple long-standing dense
5
21
220

#HBD to arXiv!🎈 On August 14, 1991, the very first paper was submitted to arXiv. That's 34 years of sharing research quickly, freely & openly! Some baby pictures to show how far we've come . . . when we were just a computer under desk . . . & in our 1994 punk phase . . . 👶💾

15
175
763

Introducing DINOv3 🦕🦕🦕 A SotA-enabling vision foundation model, trained with pure self-supervised learning (SSL) at scale. High quality dense features, combining unprecedented semantic and geometric scene understanding. Three reasons why this matters…

12
140
1K

Introducing Gemma 3 270M 🔥 🤏A tiny model! Just 270 million parameters 🧠 Very strong instruction following 🤖 Fine-tune in just a few minutes, with a large vocabulary to serve as a high-quality foundation https://t.co/E0BB5nlI1k

124
334
3K

The goal of a PhD is not to learn some facts or read a few papers or learn a bunch of techniques. The goal of a PhD is to learn independence, problem solving, how to finish things you start, resilience, & gain the ability to adapt & think creatively. Learning these things is hard
25
513
3K

How do we build AI for science? Augment with AI or replace with AI? https://t.co/adSSmJXcFx Popular prescription is to augment AI into existing workflows rather than replace them, e.g., keep the approximate numerical solver for simulations, and use AI only to correct its errors
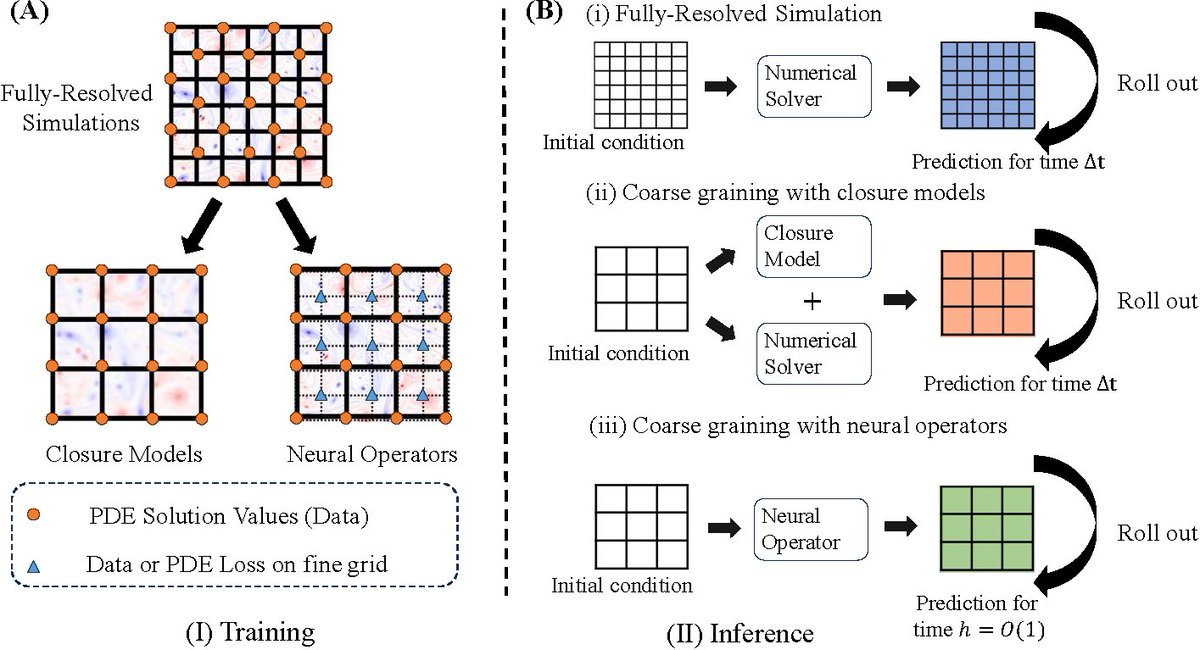
2
35
194

Two types of universal density approximators: ① Gaussian Mixtures Models ② Polynomial Exponential Families with sufficient statistics = monomials (Single distrib.) Convert GMMs ↔ PEFs either using moment MLE parameter to natural parameter or score matching (Ref.: slide)

2
22
202