

Tianjian Li
@tli104
Followers
277
Following
1K
Media
7
Statuses
175
PhD student @jhuclsp, research scientist intern @AIatMeta FAIR. I work on data curation for language models. Previously @nyuniversity.
Baltimore, MD
Joined November 2022
I have written a blogpost offering an explanation of why both the chosen and the rejected log-probability decreases during DPO, and more interestingly, why it is a desired phenomenon to some extent. Link:
0
5
12
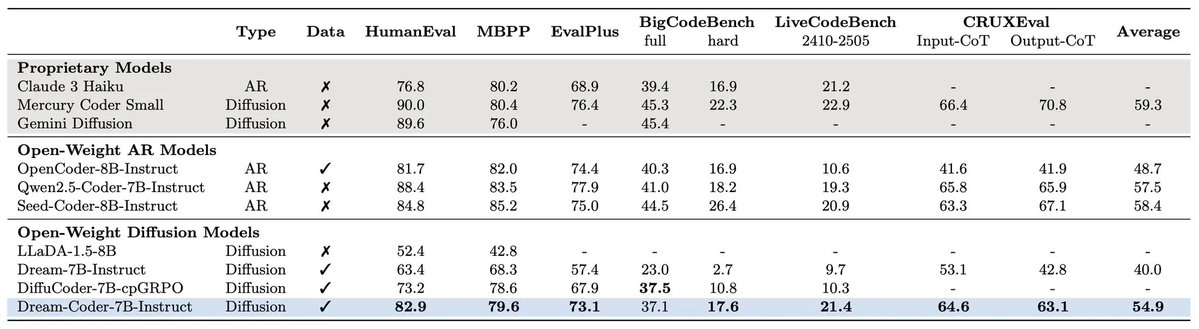
RT @_zhihuixie: 🚀 Thrilled to announce Dream-Coder 7B — the most powerful open diffusion code LLM to date.
0
33
0
RT @PranjalAggarw16: Super excited to see L1 accepted to #COLM2025!. We are further open-sourcing 5 new models & a dataset:.1. L1-7B & L1-….
0
3
0
RT @DanielKhashabi: What’s really going on inside LLMs when they handle non-English queries?. @BafnaNiyati's recent work introduces the **t….
0
4
0
RT @Happylemon56775: Excited to share what I worked on during my time at Meta. - We introduce a Triton-accelerated Transformer with *2-sim….
0
96
0
RT @BafnaNiyati: 📢When LLMs solve tasks with a mid-to-low resource input/target language, their output quality is poor. We know that. But c….
0
9
0
RT @gui_penedo: We have finally released the 📝paper for 🥂FineWeb2, our large multilingual pre-training dataset. Along with general (and ex….
0
96
0
RT @arnal_charles: ❓How to balance negative and positive rewards in off-policy RL❓. In Asymmetric REINFORCE for off-Policy RL, we show that….
0
28
0
RT @nouhadziri: 📢 Can LLMs really reason outside the box in math? Or are they just remixing familiar strategies? . Remember DeepSeek R1, o1….
0
159
0
RT @YLiiiYLiii: 🧠🤖Can LLMs outperform online therapists in single-turn counseling? Meet CounselBench - 100 mental-health professionals rate….
0
6
0
RT @natolambert: A common trend across recent research in using reinforcement learning to train reasoning models is that the clipping opera….
0
54
0
RT @aviral_kumar2: Our view on test-time scaling has been to train models to discover algos that enable them to solve harder problems. @se….
0
30
0
RT @alexdmartin314: Talk to me at #CVPR2025 about Multimodal RAG topics! I'll be presenting two papers on video retrieval: Video-ColBERT (l….
0
7
0
RT @jaehunjung_com: Data curation is crucial for LLM reasoning, but how do we know if our dataset is not overfit to one benchmark and gener….
0
33
0
RT @_vaishnavh: 📢 New paper on creativity & multi-token prediction! We design minimal open-ended tasks to argue:. → LLMs are limited in cre….
0
40
0
RT @Mengyue_Yang_: Curious how training data order impacts LLMs without retraining?. Introducing FUT:. 🔍Estimate the effects of any sample….
0
44
0