

Andrei Bursuc
@abursuc
Followers
8K
Following
17K
Media
908
Statuses
9K
Research scientist @valeoai | Teaching @Polytechnique @ENS_ULM | Alumni @upb1818 @Mines_Paris @Inria @ENS_ULM | Feedback: https://t.co/MHAm0ClqFJ
Paris, France
Joined November 2008
Self-supervised learning is fantastic for pretraining, but can we use it for other tasks (kNN classification, in-context learning) & modalities, w/o training & by simply using its gradients as features?.Enter 🍄FUNGI - Features from UNsupervised GradIents #NeurIPS2024 🧵

9
49
333
RT @fenildoshi009: 🧵 What if two images have the same local parts but represent different global shapes purely through part arrangement? Hu….
0
107
0
Nice trick for fine-tuning with multi-token prediction without architecture changes: interleave learnable register tokens into the input sequence & discard them at inference. It works for supervised fine-tuning, PEFT, pretraining, on both language and vision domains 👇.

1/n Multi-token prediction boosts LLMs (DeepSeek-V3), tackling key limitations of the next-token setup:.• Short-term focus.• Struggles with long-range decisions.• Weaker supervision. Prior methods add complexity (extra layers).🔑 Our fix? Register tokens—elegant and powerful

0
3
12
🚨New doctor in the house!🚨 .Congrats to @TimDarcet for his tremendous work (DINOv2, registers, CAPI) & successful PhD defense followed by ~2 hrs of questions -- he's got stamina! Congrats to his incredible team of advisors from Inria & Meta: @julienmairal @p_bojanowski M. Oquab


6
4
80
Check out this awesome episode of @RoboPapers w/ our @fbartoc speaking about VaViM & VaVAM, video generative models for autonomous driving, future of world models and research landscape in this area. I recommend other episodes from @chris_j_paxton & @micoolcho w/ great questions.

Ep#12 with Florent Bartoccioni from @valeoai on VaViM and VaVAM: Autonomous Driving through Video Generative Modeling Co-hosted by @chris_j_paxton & @micoolcho
1
1
7
Brought this thing with me in the office today triggering some joy and nostalgia in the team during a break.
Update: So I eventually went for the Anbernic RG35XX H. - nice form factor & hardware specs (in mid range, didn't want it too fancy yet).- compatible w/ wide range of games from very early ones to PS1, some PS2.- multi-player mode across devices.- mini-HDMI output.- great price




0
0
0
Check out FLOSS🪥 a simple trick to boost open-vocabulary semantic segmentation. We saw that for most classes different individual prompt templates perform > vanilla averaging. We propose a way to identify them w/o training or supervision. Kudos @yasserbenigmim et al. #iccv2025.

🎉 Excited to share that our paper "FLOSS: Free Lunch in Open-vocabulary Semantic Segmentation" got accepted at #ICCV2025!.A collaborative effort with : Mohammad Fahes @tuan_hung_vu @abursuc and Raoul de Charette.

0
1
8

I tried nudging kids towards this simple game as there might be still some professional opportunities for them in solving it in the coming years 😅

0
0
0
Update: So I eventually went for the Anbernic RG35XX H. - nice form factor & hardware specs (in mid range, didn't want it too fancy yet).- compatible w/ wide range of games from very early ones to PS1, some PS2.- multi-player mode across devices.- mini-HDMI output.- great price
So I've just discovered retro handhelds (yes, very late to this party). Hello rabbit hole!.
1
0
3
13/13 Kudos to the entire team and in particular to @SpyrosGidaris for the relentless push and trust in this project 🚀. *photo: Spyros spotted in the server room during peak MOCA experiments

0
0
4

11/.- both @SpyrosGidaris & I had very short time between #eccv2022 & #cvpr2023 deadline.- we had main results ready & made a strong push for the submission and.….we’re in the 2020s: non-polished works w/o bold numbers across the board have little chance to pass through 😅.
1
0
1
10/ ☕ Now the story:.- this work dates from ancient times (~2022), when iBOT was crushing it & DINOv2 was a seed in the mind of @TimDarcet et al. - the paper had a non-linear path, but the ideas are still valuable. Recently, CAPI took a similar direction:

Want strong SSL, but not the complexity of DINOv2?. CAPI: Cluster and Predict Latents Patches for Improved Masked Image Modeling.

1
0
2
9/ ⌨️ Find more results in the paper. We release code and pre-trained models publicly. - paper: - code:
1
0
2
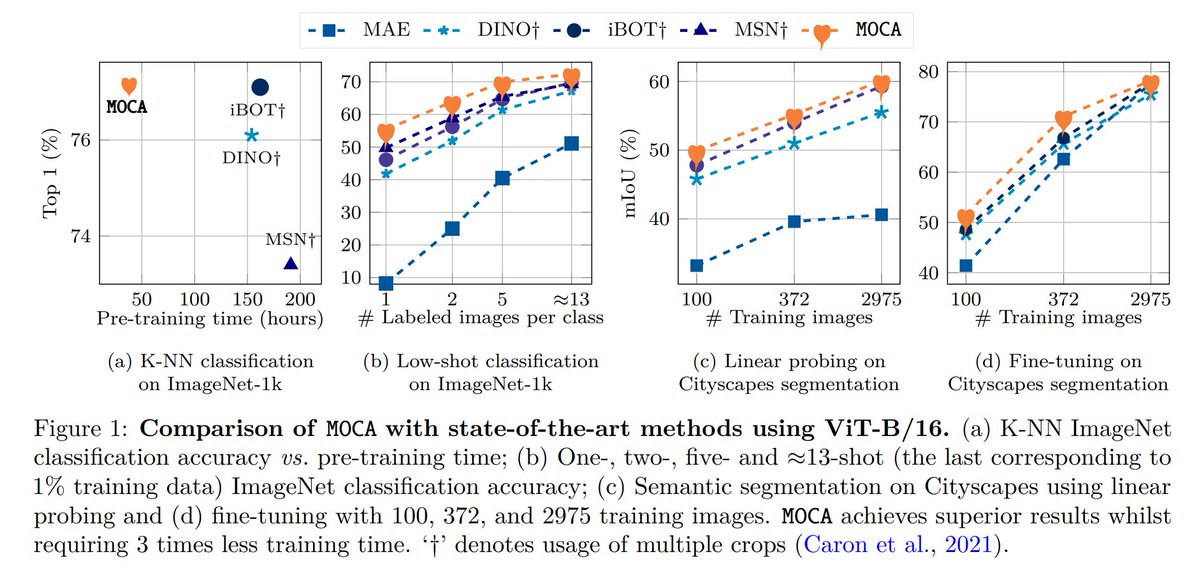
8/ 🏎️ Our results on ViT-B/16 show:.- MOCA is 3x more training efficient than prior methods.- MOCA gets strong gains in low-shot classification (1,2,5,13 shots).- on urban segmentation, MOCA performs better in both full-data and low-data settings (linear probe or fine-tuning)
1
0
1
7/ ⚙️The 2 objectives aim to: (i) promote invariance to perturbations; (ii) encourage detailed feature generation. Interestingly, balancing the two losses shows that the objectives are complementary & synergistic; switching off any of them seriously deteriorates performance

1
0
1
6/ 🔬 Let’s dive in:.- teacher (EMA) generates dense token-wise code assignments from 2 unmasked views.- student optimizes for 2 objectives:.(i) image-level (cross-view average assignment prediction).(ii) patch-level (masked same view token assignment prediction)


1
0
1
5/❓ Can we get the best of the two worlds?.🙉 Spoiler: Yes!.Enter MOCA: unify the learning principles of both discriminative and MIM paradigms. Instead of predicting pixels, MOCA predicts patch-wise codebook assignments that encode high-level and perturbation invariant features

1
0
1
4/ 🧲 Discriminative SSL (contrastive, clustering-based, teacher-student):.🫶 focus on high-level visual concepts.🫶 ignore useless image details.🙈 image-wise loss -> coarse features.🙈 less contextual reasoning

1
0
1