

ABHILASH MAJUMDER
@abhilash1396
Followers
82
Following
984
Media
8
Statuses
65
Compilers & Frameworks @nvidia , ex @intel | formerly - @MSCI_Inc , @HSBC , Author @Apress @Udacity, @unity3d, contributor@google,NLP@huggingface
Mumbai, India
Joined April 2018
Have started a youtube series on algorithmic design and thinking for interviews and engineering. https://t.co/wck6TbZxMt
#compsci #algorithms #dsa #interviews #faang #Engineering
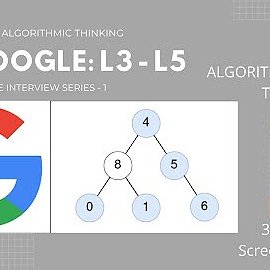
youtube.com
This playlist contains solutions to some of the most popular and difficult interview questions related to Graphs present in Leetcode
0
0
1
Run llama.cpp with Intel GPU with modern SYCL Backend. @IntelDevTools
#llama.cpp #sycl #compiler #llm #inference #llama #cuda
https://t.co/BFf3cDL8CH

linkedin.com
We have released a blog post summarizing how to run llama.cpp on SYCL backend (primarily targeted for Intel GPUs): https://lnkd.in/gVqwyAAi With the current adoption of bare metal runtime performance...
0
0
0
Thanks to @usingstdcpp for having me at uc3m Leganes, Madrid. It was great to present about #SYCL runtime to C++ WG members and developers. https://t.co/zh754t1u0K
#c++ #intel #sycl #deeplearning
0
0
0
I will be speaking at c++ Russia on Sycl language and it's features along with dpct compiler. Thanks to @cpp_russia for organizing. #sycl #cpp #c++Russia #intel

Abhilash Majumder в своем докладе на C++ Russia расскажет о SYCL — объединенном рантайме для работы с LLM- и генеративными моделями машинного обучения от Intel. Подробности и билеты: https://t.co/3SHzhbCr7x
0
0
0


Accelerate was just released with: 🔢4-bit quantization and QLora support with Transformers and peft 💻MPS support in big model inference 🏭Support for the new TPU runtime 🎛️Support for Intel XPU And more👇 https://t.co/6akiS1gD3n💻
0
0
3
Optimizing LLMs and diffusion models have become easier with #intel Cpu and GPU support for popular #huggingface frameworks for #pytorch ecosystem . Speed up training on multi CPU or GPUs with #accelerate to leverage efficient flops and compute performa… https://t.co/QXsI7AEOPd

linkedin.com
Optimizing LLMs and diffusion models have become easier with #intel Cpu and GPU support for popular #huggingface frameworks for #pytorch ecosystem . Speed up training on multi CPU or GPUs with...
0
2
4
Distributed deep learning is of paramount importance when it comes to scaling large models. TensorFlow XLA is a complex and efficient backend which helps in enabling better training and optimization of performance for large scale… https://t.co/znSatKWojs
lnkd.in
This link will take you to a page that’s not on LinkedIn
0
0
2
There has been a lot of hype regarding #gpt4 and #chatgpt regarding their ability to perform generative modelling of multimodal spaces. Although it is not inherently #AGI, but provides a strong foundation of merging on-policy acto… https://t.co/vEhBiStmJH
lnkd.in
This link will take you to a page that’s not on LinkedIn
0
0
0
PyTorch is one of the most used distributed deep learning framework .We at Intel Labs are striving to optimize PyTorch for Intel devices - from cpus to gpus. Stay tuned to understand how drastically we can speed up distributed training and inference of la… https://t.co/h05ODY9blx

linkedin.com
PyTorch is one of the most used distributed deep learning framework .We at Intel Labs are striving to optimize PyTorch for Intel devices - from cpus to gpus .The current framework is enabling...
0
0
0
Thanks @AnalyticsVidhya for having me, enjoyed delivering the session. PS: repo link : https://t.co/JFEpnZoOXN
#analyticsvidhya #datahour #diffusion #AI #AIart

github.com
Presentation of the session on Diffusion Principles on behalf of Analytics Vidhya datahour. Youtube: https://www.youtube.com/watch?v=DIdbsfzK7IUtube: - GitHub - abhilash1910/Datahour_Diffusion: Pr...

Tune in today at 7:00 PM and find out all about the building block of “Generative AI" which is taking the NFT world by storm: https://t.co/fIumaNZRJr
0
0
2
Excited to announce that our paper with collaboration from @imperialcollege has been accepted at @lrec2022 . The topic includes unsupervised knowledge discovery using graphs; pre-prints and recordings to be uploaded soon. #NLProc #lrec #graphs #Neuralnetworks
1
1
1

Today marks 5 years since the public release of PyTorch! We didn't expect to come this far, but here we're🙂- 2K Contributors, 90K Projects, 3.9M lines of "import torch" on GitHub. More importantly, we're still receiving lots of love and having a great ride. Here's to the future!
59
434
3K
A medium blog detailing the research behind CartoonGAN :

link.medium.com
GANs have been in instrumental in creating different artforms through different architectures. Cartoons are an artistic form which are…
0
0
0
Cartoonizing images is now easier with CartoonGAN : https://t.co/UYePqkvSF8 Based on CVPR 2018 ( https://t.co/o9aZrH0pGE)
#GANs #CartoonGAN #Tensorflow
1
6
25
Interested in creating "longer" versions of (any) Pegasus models? LongPegasus is a tf package which is used to incude Longformer self attention on Pegasus models - you can even finetune the "long" model from HF https://t.co/jNl4MrCR2e
@huggingface @TensorFlow #pegasus #longformer
0
0
0
Great work from @huggingface AutoNLP team which would allow users to train on their own tasks. Try it out by clicking on "Train" on these pages: https://t.co/XXzW7Mg65r
https://t.co/VQUIbojuBr
https://t.co/tNkQWPAcgS
https://t.co/l508CF47Mw
https://t.co/R9sxGcRCir
@huggingface

huggingface.co
0
5
19
Graph Attention Network Embeddings provide more node level details by neighborhood importance sampling.GraphAttentionNetworks is a package which extracts Multihead GAT embeddings from KGs along with trainable Layer. Repo: https://t.co/XgGvR3fe36 Made with @TensorFlow
#DL

github.com
This package is a Tensorflow2/Keras implementation for Graph Attention Network embeddings and also provides a Trainable layer for Multihead Graph Attention. - abhilash1910/GraphAttentionNetworks
0
0
0

SpectralEmbeddings an embedding generator library used for creating Graph Convolution Network and Graph AutoEncoder Embeddings from Knowledge Graphs This allows projection of higher order network dependencies for creating the node embeddings https://t.co/NjUgbkpuqm
1
13
46
My notebook on Quantum TRPO/PPO for memory optimized quantum control in Deep RL is live on #Pennylane (1st one): https://t.co/P0r8jsvtwe Special thanks to @XanaduAI @pennylaneai .
0
0
8