

Aaron Havens
@aaronjhavens
Followers
294
Following
4K
Media
9
Statuses
52
PhD student at @ECEILLINOIS. Control theory, ML and Autonomy. Previously @AIatMeta, @PreferredNet and @TuSimpleAI
Champaign, IL
Joined April 2011
New paper out with FAIR(+FAIR-Chemistry):. Adjoint Sampling: Highly Scalable Diffusion Samplers via Adjoint Matching. We present a scalable method for sampling from unnormalized densities beyond classical force fields. 📄:
1
18
110
RT @guanhorng_liu: Adjoint-based diffusion samplers have simple & scalable objectives w/o impt weight complication. Like many, though, they….
0
39
0
RT @auhcheng: Excited to share Quetzal, a simple but scalable model for building 3D molecules atom-by-atom. 🐉 Named after Quetzalcoatl, th….
0
31
0
RT @RickyTQChen: Reward-driven algorithms for training dynamical generative models significantly lag behind their data-driven counterparts….
0
6
0
RT @RickyTQChen: We are presenting 3 orals and 1 spotlight at #ICLR2025 on two primary topics:. On generalizing the data-driven flow match….
0
28
0
This work was done during a PhD internship at FAIR NYC, thanks to my amazing supervisors @brandondamos ,.@RickyTQChen and Brian Karrer. Special thanks to our core contributors: @bkmi13.@bingyan4science @xiangfu_ml.@guanhorng_liu (and of course @cdomingoenrich).
0
1
7
Our evaluation offers a new challenging sampling benchmark for molecular conformer generation. The benchmark features real, drug-like molecules from the SPICE dataset, and we hope it drives direct and tangible progress in sampling for computational chemistry (coming soon).
1
0
4
This lets us train conditional diffusion samplers directly from expensive energy functions, namely, state-of-art molecular foundation models, amortizing sampling across thousands of molecules—unlike traditional samplers, which require heavy energy access per new molecule sample.
1
0
4
We specialize Adjoint Matching—originally designed for reward fine-tuning—to the sampling setting. By exploiting a factorization of the optimal transition density (a Schrödinger bridge), our new loss enables heavy reuse of simulations and energy evaluations.
1
0
4
RT @RickyTQChen: Want to learn continuous & discrete Flow Matching? We've just released:. 📙 A guide covering Flow Matching basics & advance….
0
160
0
Hi friends. I will be at the NYC FAIR office for the next 6 months as a research scientist intern. I’ll be working on all things control theory x generative modeling under the amazing @brandondamos. Please feel free to reach out if you’re around NYC!.
0
0
28
A virtual session on the intersection of optimization, control and RL happening now (9am-12pm CT) for the annual CSL student conference! Find the schedule and zoom link here:

0
2
3
RT @angelaschoellig: Our review paper on **Safe Learning in Robotics** is out, including open-source code. Wondering how model-driven and d….
0
25
0
(6/6) encapsulated the key perspectives I would like to attempt to bridge going forward: Control, Learning and Optimization. Thanks to my great PhD advisor Prof. Bin Hu who shares these same curiosities.

0
0
0
(5/6) unstable and unconstrained methods will likely fail without a large data set and alternative LQR-based constraint methods will be too biased to solutions with better margins. This was a rather straight-forward project to start my PhD, but I felt that it really.
1
0
0
(4/6) state-space model and small gain theorem from robust control. You can even model against time-varying polytopic bounded uncertainties just by adding a few more LMI constraints to your problem. This formulation can be especially useful when your system is nearly.
1
0
0
(3/6) I think one the coolest aspects of this work is that it lets you design your imitation learning problem almost as if you were a control engineer. Not only can you guarantee stability but you can also bias your controller against all kinds of uncertainties using the extended

1
0
0
(2/6) We consider the problem of learning a controller of a known LTI system from demonstrations while constraining the solutions to be robustly stabilizing using some classic LMI conditions. You can efficiently obtain a stationary point to this problem using an ADMM formulation.
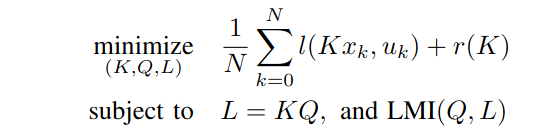
1
0
0
(1/6) Happy to share one of the first papers of my PhD which was done last fall: "On Imitation Learning of Linear Control Policies: Enforcing Stability and Robustness Constraints via LMI Conditions" :

arxiv.org
When applying imitation learning techniques to fit a policy from expert demonstrations, one can take advantage of prior stability/robustness assumptions on the expert's policy and incorporate such...
2
1
6
