

Shaden
@Sa_9810
Followers
137
Following
200
Media
14
Statuses
36
graduate student @MIT | doing representation learning and math
Cambridge, MA
Joined April 2021
Excited to share our ICLR 2025 paper, I-Con, a unifying framework that ties together 23 methods across representation learning, from self-supervised learning to dimensionality reduction and clustering. Website: A thread 🧵 1/n
1
24
88
RT @MasonKamb: I'm at ICML presenting this work! Come by on Tuesday to hear about/chat about combinatorial generalization and creativity in….
0
28
0
RT @ema_marconato: 🧵Why are linear properties so ubiquitous in LLM representations?. We explore this question through the lens of 𝗶𝗱𝗲𝗻𝘁𝗶𝗳𝗶𝗮….
0
61
0
RT @_AmilDravid: Artifacts in your attention maps? Forgot to train with registers? Use 𝙩𝙚𝙨𝙩-𝙩𝙞𝙢𝙚 𝙧𝙚𝙜𝙞𝙨𝙩𝙚𝙧𝙨! We find a sparse set of activat….
0
62
0
RT @KumailAlhamoud: We've seen hilarious fails from generative models struggling with "NO" (e.g., asking for "a clear sky with no planes",….
0
1
0
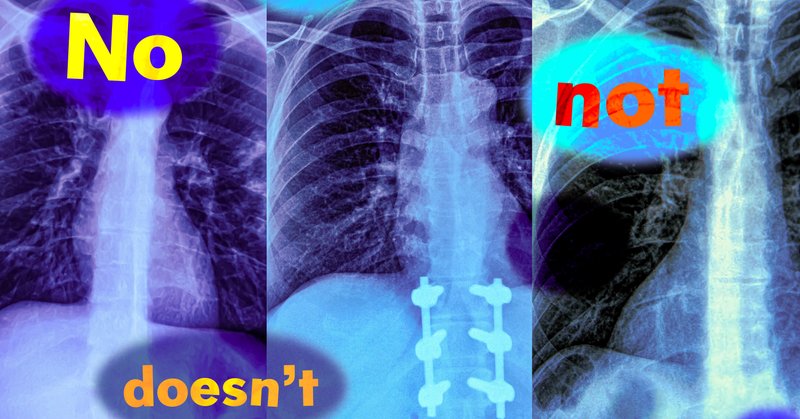
RT @AIHealthMIT: Does an AI model understand "no(t)"? 🚫@KumailAlhamoud, Shaden Alshammari, @YonglongT, @guohao_li, Philip Torr, Yoon Kim, a….
news.mit.edu
MIT researchers found that vision-language models, widely used to analyze medical images, do not understand negation words like “no” and “not.” This could cause them to fail unexpectedly when asked...
0
4
0
RT @ShivamDuggal4: Drop by our poster at Hall 3 + Hall 2B, #99 at 10 AM SGT!.Unfortunately none of us could travel, but our amazing friends….
0
5
0
RT @juliachae_: My first first-authored (w/ @shobsund) paper of my phd is finally out! 🚀 . Check out our thread to see how general-purpose….
0
7
0
n/n. Huge thanks to my amazing collaborators and advisors: @mhamilton723, John Hershey, Axel Feldmann, and William T. Freeman! . • Website: • Full Paper:

arxiv.org
As the field of representation learning grows, there has been a proliferation of different loss functions to solve different classes of problems. We introduce a single information-theoretic...
3
0
4
7/n . There are still many open questions from these insights:. (1) What new methods emerge by filling more gaps or even adding new rows or columns?.(2) How does using divergences beyond KL reshape things?.(3) What makes methods outside the framework fundamentally different?.
1
0
4
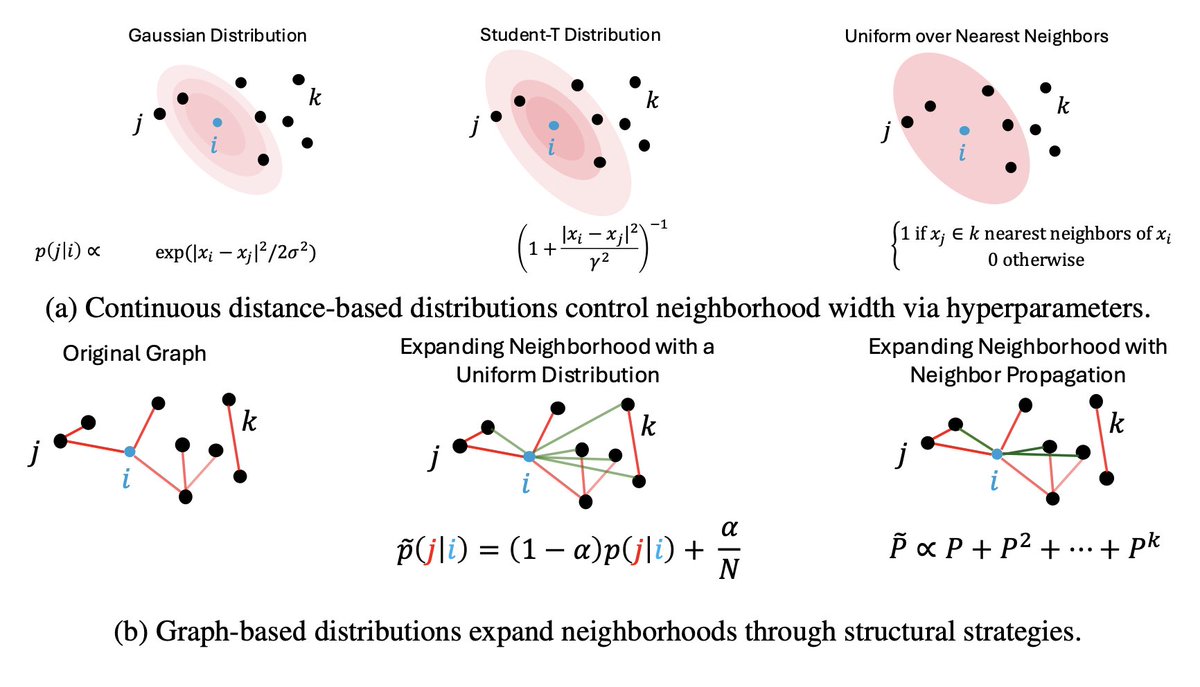
6/n . Our use of neighborhood expansion was inspired by the heavy-tailed distributions such as Student-T in t-SNE for dimensionality reduction, so we adapted the idea to discrete settings like neighbor propagation.
1
0
3
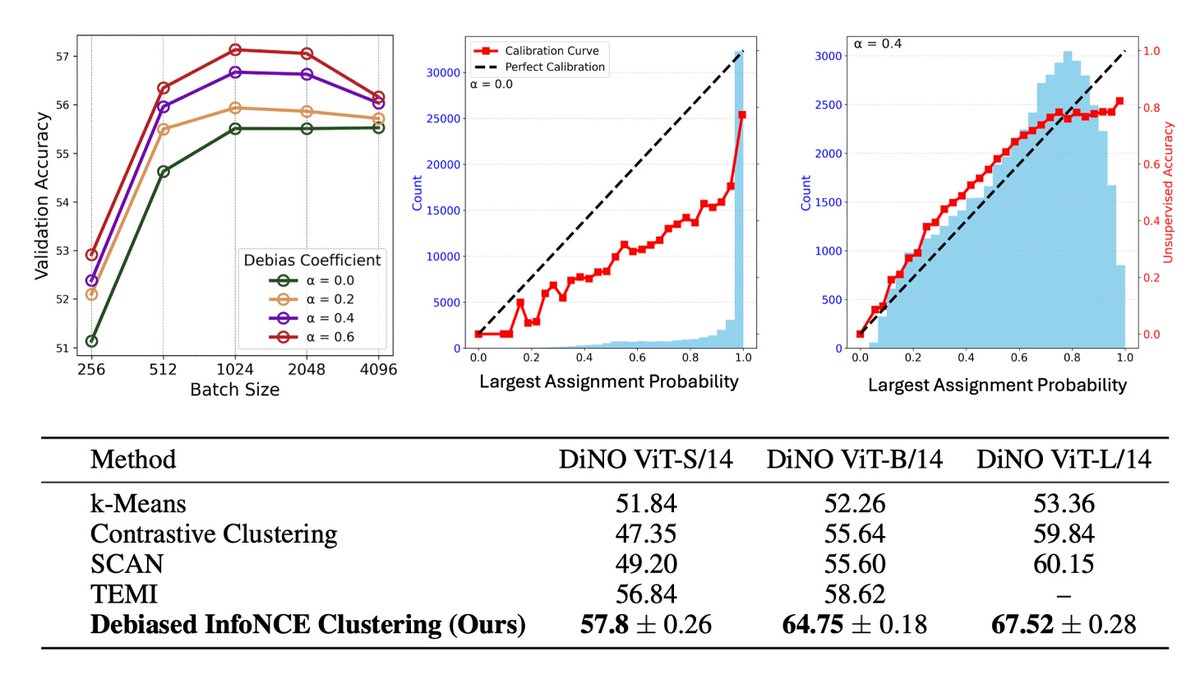
5/n . How does I-Con yield practical gains?.(1) Enables principled design over heuristics.(2) Transfers ideas across domains. We applied neighborhood expansion for debiasing, achieving:.✅ +8% & SOTA on clustering ImageNet1K.✅ Better probabilities calibration
1
0
4
4/n. We provide a codebase that enables one-line implementation and training for many of these methods to make it easy to explore and compare different choices of P and Q
1
1
4
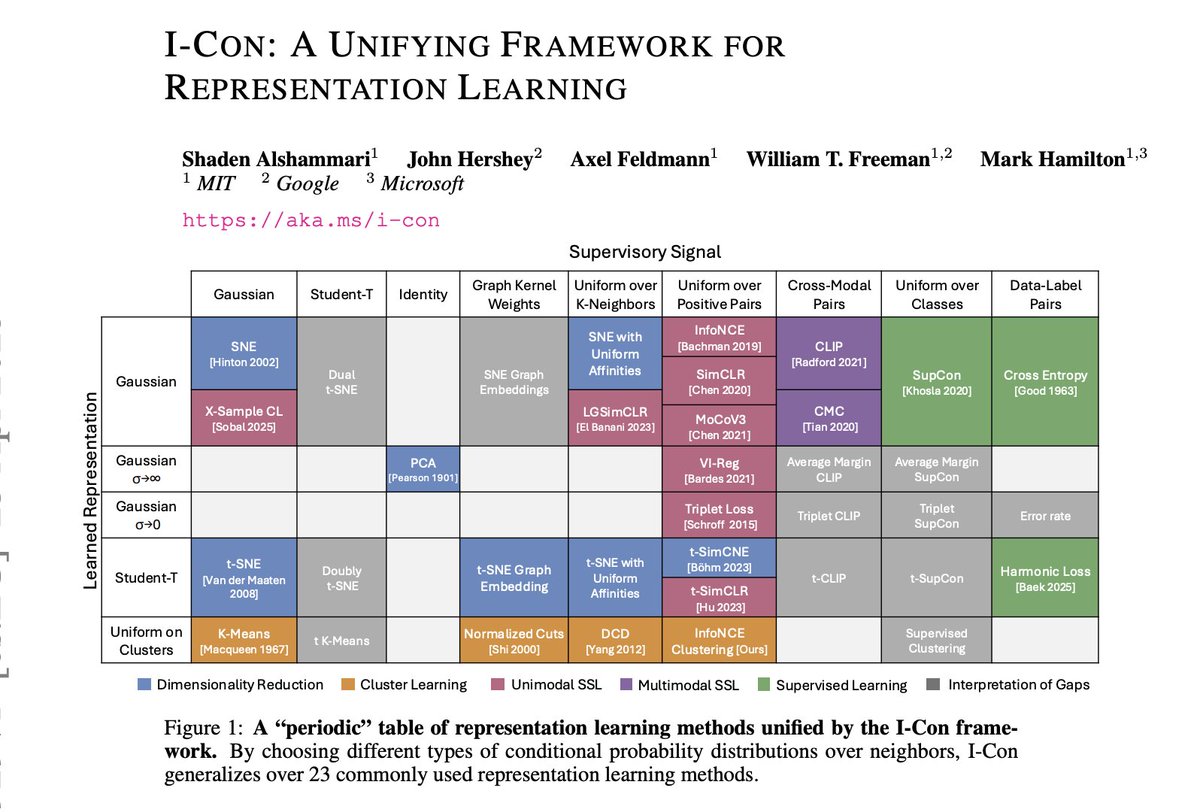
3/n. Varying the definitions of P and Q recovers a wide range of existing methods! Here's an illustration using specific choices of P and Q that recover t-SNE, SimCLR, K-Means, and supervised cross-entropy.
1
0
4
2/n. I-Con is built on a simple but general principle: define two conditional distributions — a supervisory signal P and a learned signal Q, where Q is parameterized by the learned representations. Learning proceeds by minimizing the KL divergence.
1
0
3
RT @mhamilton723: Excited to share our new discovery of an equation that generalizes over 23 different machine learning algorithms. We use….
0
4
0
RT @ShivamDuggal4: Current vision systems use fixed-length representations for all images. In contrast, human intelligence or LLMs (eg: Ope….
0
67
0