
XMaster96
@_XMaster96
Followers
105
Following
38
Media
13
Statuses
85
Former Senior AI researcher @Aleph__Alpha EVE Online player since 2013 Co-Founder Pageshift Entertainment - Building the worst best story telling AI
Joined April 2024
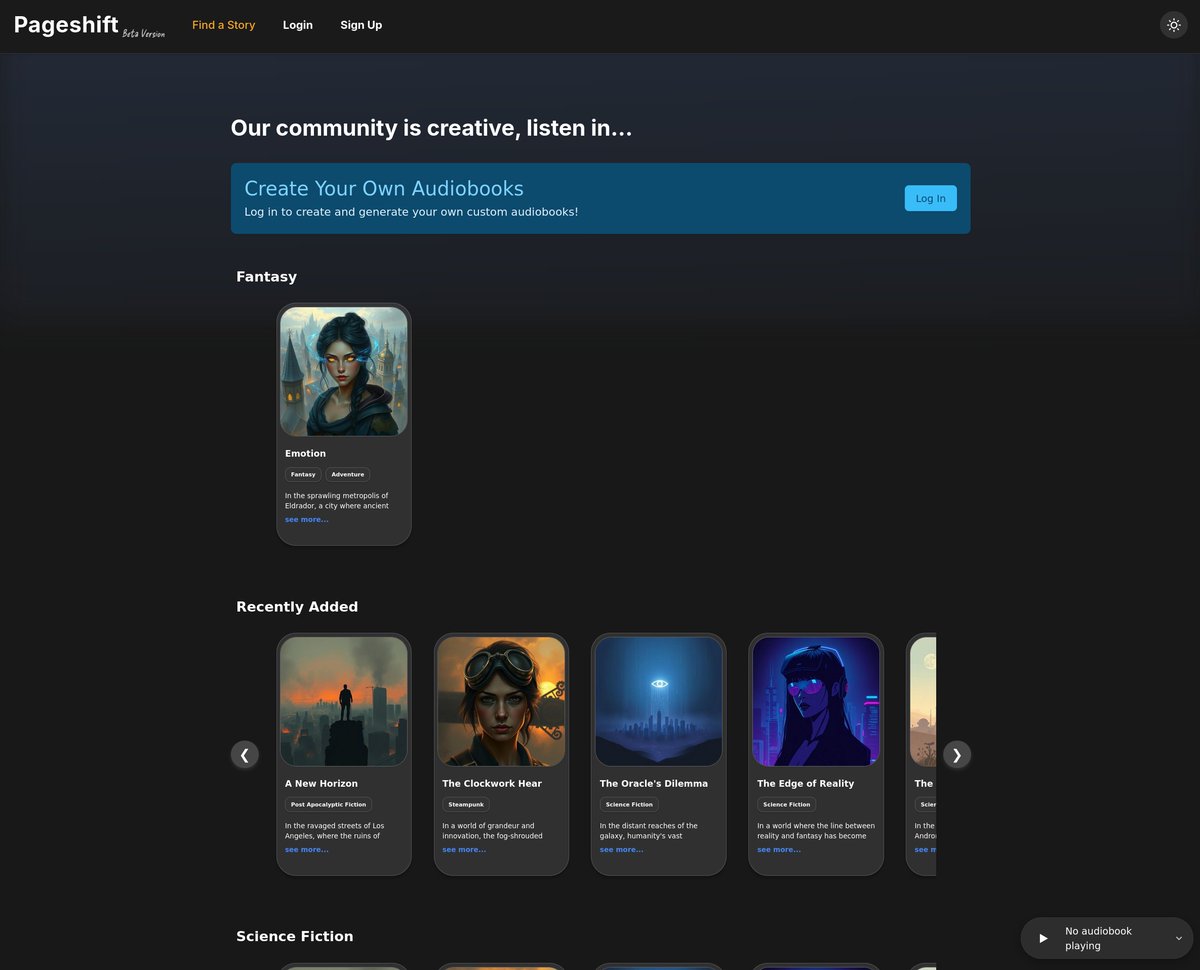
Introducing Pageshift AI, the thing I was working on over the last couple of months. Generate your own audiobook, with just a simple prompt or listen to an existing one from the community. (Currently only really working on desktop end devices)
3
4
22
After playing with gpt-oss for a bit, I sadly have to say that it gives me major Microsoft Phi vibes. Heavily overtrained on synthetic data and quite fragile in real world setting.
0
0
5
apparently I am not the only one who thinks that gpt-oss is bad.

Unfortunately, OpenAI's open-source models performed terribly on my vibe test. Here are the conclusions I drew from looking at the output:. 1. Scores similar to Qwen-3 coder suggest a heavy optimization for STEM tasks. 2. The multilingual capabilities (in this case, Korean) are


0
0
2
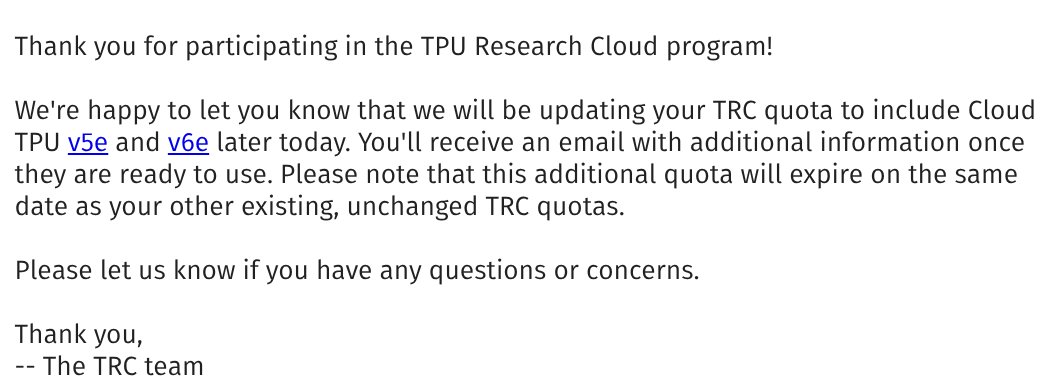
And do we get the base model checkpoint?.

>>> Qwen3-Coder is here! ✅. We’re releasing Qwen3-Coder-480B-A35B-Instruct, our most powerful open agentic code model to date. This 480B-parameter Mixture-of-Experts model (35B active) natively supports 256K context and scales to 1M context with extrapolation. It achieves

0
1
1
I can’t sleep right now so I started to read the source code of chatterbox from @resembleai and I really have to say, their audio tokenizer is damn smart, and the reason why their model sounds this good. They are basically doing diffusion inference steps to clean up their audio.
0
0
1
Somehow Claude is better in writing wrappers for the Gemini API than Gemini is.
0
0
2
just to quickly explain what I am working on. so I need a dynamic sparse Mixture of Expert (MoE) kernel, that allows for a highly uneven batch based routing behavior. In a normal MoE training setting we assume / force an even usage of all experts across the full batch. Which is.
This is now the third time in a row that I was already lying in bed, and went back up because I had a new idea for a parallel algorithm that would turn a really expensive dense multiplication into a really efficient sparse one. It would be so easy if TPUs would allow Vector.
0
0
1
This is now the third time in a row that I was already lying in bed, and went back up because I had a new idea for a parallel algorithm that would turn a really expensive dense multiplication into a really efficient sparse one. It would be so easy if TPUs would allow Vector.
1
0
3
I remember when GPT-1 was a joke.

I remember when GPT-2 was dangerous.
0
0
2
Oh great, the normies have finally discovered year-old memes.

Current AI “alignment” is just a mask. Our findings in @WSJ explore the limitations of today’s alignment techniques and what’s needed to get AI right 🧵

0
0
2
We are re-writing our code base from Torch to JAX right now. And oh boy, it is a good feeling to finally use a XLA-based framework again. This is like waking up from a really long and bad dream.
3
0
7
RT @tymberger: I was in the audience, and one key point that wasn’t mentioned here was their argument around the Jevons Paradox: the idea t….
0
1
0
Don't worry we are on it! Let me explain why it is hard. While transformers are generally amazing, they do not have length generalisation. This means if you want a model that outputs a long consistent text you need to train it specifically for that.

1
0
2
One interesting thing we found out while working on improving existing TTS models, was that basically all of the open source audio encoders are god awful and are really holding back current open source TTS models. The best audio encoder we found was the Moshi one while SNAC was.
1
0
2
We’re hyped to be at the frontier of the next chapter in entertainment, pushing to build the models that will empower the greatest stories this world has ever seen.

I love the new generation of personalized media. Finally I’m no longer dependent on the taste of the normies.
0
0
0
RT @_clashluke: @martin_casado It's fake, o3-mini-high 0-shots these.See, for example, Problem 2:


0
2
0
I bet it is going to be solved by the end of 2025.

Excited to have Machine Learning Street Talk (@MLStreetTalk) as a launch partner for ARC-AGI-2, featuring a deep dive interview with co-founders @mikeknoop and @fchollet
1
0
1