
Ruiqi Zhong
@ZhongRuiqi
Followers
6K
Following
958
Media
43
Statuses
494
Member of Technical Staff at Thinking Machines. Human+AI collaboration. Scalable Oversight. Explainability. Prev @AnthropicAI PhD UC Berkeley'25; Columbia'19
Berkeley, CA
Joined October 2016
Last day of PhD! I pioneered using LLMs to explain dataset&model. It's used by interp at @OpenAI and societal impact @AnthropicAI Tutorial here. It's a great direction & someone should carry the torch :) Thesis available, if you wanna read my acknowledgement section=P
30
38
544

[Life update] I’ve officially left @PrincetonPLI and joined Thinking Machines Lab @thinkymachines . It feels like the right time to look back on my journey at Princeton — one and a half years that were truly transformative. During this period, I made many friends, learned
18
17
632
Science is best shared! Tell us about what you’ve built or discovered with Tinker, so we can tell the world about it on our blog. More details at

thinkingmachines.ai
Announcing Tinker Community Projects
37
41
371
Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other
63
397
3K

We're happy to support the Human Centered LLMs course, on topics close to our hearts. We'd like to support more classes with free credits for students to use on assignments and projects. If you're an instructor interested in using Tinker in your course, please reach out to

15
56
636

PhD apps season is here! 😱🥳 Apply to do a PhD @WisconsinCS (as pictured) w/ me to research: - Societal impact of AI - NLP ←→ CSS and cultural analytics - Computational sociolinguistics - Human-AI interaction - Culturally competent and inclusive NLP https://t.co/YVrGa3BjWg
17
69
360

I am going to present two papers at #COLM2025 tomorrow from 4:30-6:30pm, as none of our leading authors can attend due to visa issues. Haven't done poster presentations for years 🤣🤣 .... so I will do my best! #76: LongProc #80: Goedel-Prover v1

Our Goedel-Prover V1 will be presented at COLM 2025 in Montreal this Wednesday afternoon! I won’t be there in person, but my amazing and renowned colleague @danqi_chen will be around to help with the poster — feel free to stop by!
4
27
346

will also be in montreal friday at colm🦙 if you’re passionate about building ai that deeply understands and empowers people, say hi - you’re in better company than you think ☺️
4
3
102

Had the privilege to try Tinker at its early stage during my internship at @thinkymachines and continue using it. I still feel surreal to be able to shape model behavior on my laptop—even up to 235B parameter scale. Reminds me of the creativity sparked when my primary school got

Introducing Tinker: a flexible API for fine-tuning language models. Write training loops in Python on your laptop; we'll run them on distributed GPUs. Private beta starts today. We can't wait to see what researchers and developers build with cutting-edge open models!
9
28
404

One interesting "fundamental" reason for Tinker today is the rise of MoE. Whereas hackers used to deploy llama3-70B efficiently on one node, modern deployments of MoE models require large multinode deployments for efficiency. The underlying reason? Arithmetic intensity. (1/5)
Introducing Tinker: a flexible API for fine-tuning language models. Write training loops in Python on your laptop; we'll run them on distributed GPUs. Private beta starts today. We can't wait to see what researchers and developers build with cutting-edge open models!
15
68
837

Tinker is cool. If you're a researcher/developer, tinker dramatically simplifies LLM post-training. You retain 90% of algorithmic creative control (usually related to data, loss function, the algorithm) while tinker handles the hard parts that you usually want to touch much less
Introducing Tinker: a flexible API for fine-tuning language models. Write training loops in Python on your laptop; we'll run them on distributed GPUs. Private beta starts today. We can't wait to see what researchers and developers build with cutting-edge open models!
111
652
6K
🚀With early access to Tinker, we matched full-parameter SFT performance as in Goedel-Prover V2 (32B) (on the same 20% data) using LoRA + 20% of the data. 📊MiniF2F Pass@32 ≈ 81 (20% SFT). Next: full-scale training + RL. This is something that previously took a lot more effort
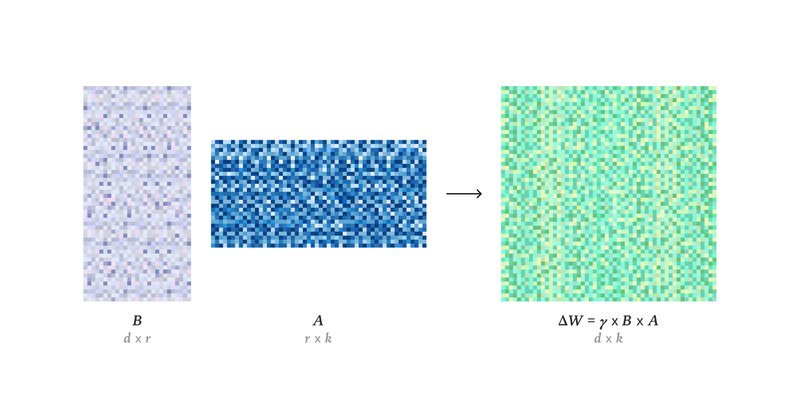
thinkingmachines.ai
How LoRA matches full training performance more broadly than expected.
2
20
188

I had the chance to try @thinkymachines' Tinker API for the past couple weeks. Some early impressions: Very hackable & lifts a lot of the LLM training burden, a great fit for researchers who want to focus on algs + data, not infra. My research is in RL, and many RL fine-tuning
Introducing Tinker: a flexible API for fine-tuning language models. Write training loops in Python on your laptop; we'll run them on distributed GPUs. Private beta starts today. We can't wait to see what researchers and developers build with cutting-edge open models!
10
27
495

GPUs are expensive and setting up the infrastructure to make GPUs work for you properly is complex, making experimentation on cutting-edge models challenging for researchers and ML practitioners. Providing high quality research tooling is one of the most effective ways to
41
128
2K

Very excited to share what I have been working on with a great team of people at @thinkymachines. Tinker is a whole new way to train and customize models all the way up to frontier scale. Most importantly, it allows everyone to use their own code, data, tools and environments,
Introducing Tinker: a flexible API for fine-tuning language models. Write training loops in Python on your laptop; we'll run them on distributed GPUs. Private beta starts today. We can't wait to see what researchers and developers build with cutting-edge open models!
12
22
303

Excited to release Tinker and see what the community uses it for.
Introducing Tinker: a flexible API for fine-tuning language models. Write training loops in Python on your laptop; we'll run them on distributed GPUs. Private beta starts today. We can't wait to see what researchers and developers build with cutting-edge open models!
5
10
193
Tinker provides an abstraction layer that is the right one for post-training R&D -- it's the infrastructure I've always wanted. I'm excited to see what people build with it. "Civilization advances by extending the number of important operations which we can perform without
Introducing Tinker: a flexible API for fine-tuning language models. Write training loops in Python on your laptop; we'll run them on distributed GPUs. Private beta starts today. We can't wait to see what researchers and developers build with cutting-edge open models!
49
114
1K
Very excited about this release!! As a former grad student I struggled to finetune llms. Even when the gpus are enough, it was painful to set up the infra correctly. Tinker allows more researchers to understand and language models, beyond a few well-funded labs.
Introducing Tinker: a flexible API for fine-tuning language models. Write training loops in Python on your laptop; we'll run them on distributed GPUs. Private beta starts today. We can't wait to see what researchers and developers build with cutting-edge open models!
2
10
191

Today on Connectionism: establishing the conditions under which LoRA matches full fine-tuning performance, with new experimental results and a grounding in information theory
LoRA makes fine-tuning more accessible, but it's unclear how it compares to full fine-tuning. We find that the performance often matches closely---more often than you might expect. In our latest Connectionism post, we share our experimental results and recommendations for LoRA.
58
145
2K
better recipe for LoRA. We hope this empowers the broader community and enables more ppl to research/customize llm!
LoRA makes fine-tuning more accessible, but it's unclear how it compares to full fine-tuning. We find that the performance often matches closely---more often than you might expect. In our latest Connectionism post, we share our experimental results and recommendations for LoRA.
3
3
166
Efficient training of neural networks is difficult. Our second Connectionism post introduces Modular Manifolds, a theoretical step toward more stable and performant training by co-designing neural net optimizers with manifold constraints on weight matrices.
118
463
3K