

Zhaozhuo Xu
@ZhaozhuoX
Followers
242
Following
596
Media
3
Statuses
102
Assistant Professor, @FollowStevens. Ph.D. @RiceCompSci
Houston, TX
Joined September 2017
🚀 Join us at #AAAI2025 for our tutorial: TQ08: KV Cache Compression for Efficient Long Context LLM Inference 📍 Room 116 ⏰ 4:15 PM - 6:00 PM Learn how to compress KV cache for faster, scalable LLM inference! Don't miss it! #AI #LLM #Efficiency #AAAI25
3
21
64

Grateful for everyone’s support and encouragement throughout this journey — family, colleagues, mentors, friends. A special shoutout to all my Ph.D. students — the real heroes behind the scenes (watch out for them, they’re headed for big things)

Congrats to Rice CS' @Anshumali_ Shrivastava, who has been promoted to full professor. Shrivastava is well on his way to revolutionizing how LLMs & other deep learning models are trained & stored, using new algorithms to make AI scalable & more accessible. https://t.co/8VpFk371gp
0
1
15

We’re grateful that our recent work on the Theory-of-Mind of LLMs was featured by MIT Technology Review China 🙏 🔗 https://t.co/Evg7wwoDRy In two new preprints, we explore: Sparsity and ToM: How extremely sparse patterns in LLMs shape their ability to infer others’ beliefs and
1
6
14

📣📣📣Excited to meet @Anshumali_ at ICML 2025! I want to promote their work on parameter-efficient fine-tuning (PEFT) for LLMs using sketches. This method offers great results with fewer parameters. @ZhaozhuoX @Tianyi_zha @Apd10Desai
0
2
4

🚨 Call for Papers: VISTA Workshop @ ICDM 2025 🚨 📅 Nov 12, 2025 | 📍 Washington, DC Explore GenAI standards, legal constraints, copyright risks, & compliance. Submit by Sep 5! 🔗 https://t.co/MjmZx8UunI Speakers: V. Braverman, D. Atkinson, A. Li #ICDM2025 #GenAI #AIStandards
1
2
5

🔥 We introduce Multiverse, a new generative modeling framework for adaptive and lossless parallel generation. 🚀 Multiverse is the first open-source non-AR model to achieve AIME24 and AIME25 scores of 54% and 46% 🌐 Website: https://t.co/J9osByhWUf 🧵 1/n
6
85
223

Attending #CVPR2025? Please check out our paper on TopoCellGen. We propose the first diffusion network for cell topology generation, based on topological data analysis (TDA). The paper was selected for an oral presentation, an honor awarded to only about 0.7% of submissions.
0
1
9
🥳 Happy to share our new work – Kinetics: Rethinking Test-Time Scaling Laws 🤔How to effectively build a powerful reasoning agent? Existing compute-optimal scaling laws suggest 64K thinking tokens + 1.7B model > 32B model. But, It only shows half of the picture! 🚨 The O(N²)
7
73
245
If you are starting at Rice, you can choose to be an AIist. I am very excited by this "uniquely designed" AI curriculum offered by @RiceCompSci. I have penned down my thoughts in here. Feedback welcome. https://t.co/VUp0vGjvuO
@RiceEngineering @RiceUniversity

medium.com
I am sharing an exciting update — I’m part of the core design team that is launching one of the handful first few Bachelor of Science…
0
5
18

Why does autoregressive (AR) image generation still suck — even in the era of LLMs? The core issue might be the Visual Tokenizer (VT). We introduce VTBench, a comprehensive benchmark designed to evaluate 20+ state-of-the-art VTs in the context of AR image generation. Our
1
3
4

llama fine tuning is great but have you tried it on https://t.co/DjeYB9EMqI with just a couple of clicks?
2
2
2
Any approximation of LLMs—or loss in reliability—for efficiency gains simply isn’t worth the risk. Introducing "perfect compression of LLMs" Blog: https://t.co/qgs2xSpe3c arxiv:
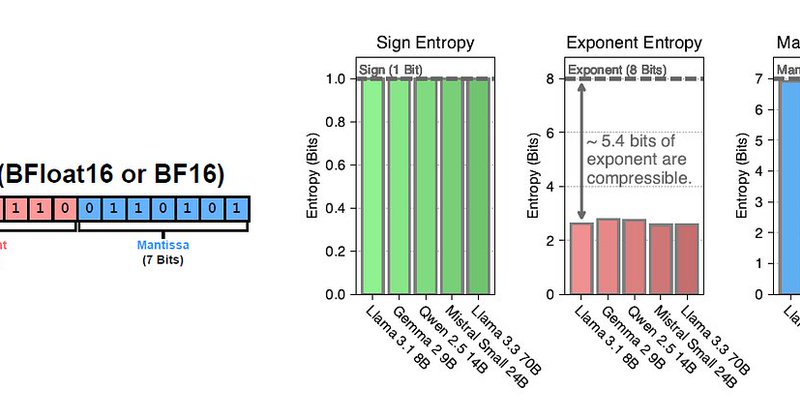
medium.com
BFloat16 is 5-bits larger than needed!
1
9
31
Excited to give my New Faculty Highlight Talk at AAAI 2025 tomorrow! 🎤 📌 Compression-Aware Computing for Scalable & Sustainable ML 🗓 March 2, 10:00 AM | 📍 Room 121B If you’re at #AAAI2025, let’s connect! 🚀
2
5
43

We really appreciate the great turnout and engagement during our AAAI 25 tutorial! Given that it was a highly technical talk, we’re genuinely glad that the audience received our message well and asked so many great questions. https://t.co/CRUUbZfBs3 Here's the slides as promised,

github.com
Official implementation for Yuan & Liu & Zhong et al., KV Cache Compression, But What Must We Give in Return? A Comprehensive Benchmark of Long Context Capable Approaches. EMNLP Fin...
🚀 Join us at #AAAI2025 for our tutorial: TQ08: KV Cache Compression for Efficient Long Context LLM Inference 📍 Room 116 ⏰ 4:15 PM - 6:00 PM Learn how to compress KV cache for faster, scalable LLM inference! Don't miss it! #AI #LLM #Efficiency #AAAI25
0
2
6
Join us at #AAAI2025 for TQ05: LLMs and Copyright Risks: Benchmarks and Mitigation Approaches! Discover how LLMs intersect with copyright challenges, learn benchmark evaluations, and explore effective mitigation strategies. See you in Room 117, 2:00–3:45 pm!
0
7
14
🚀 RAG vs. Long-Context LLMs: The Real Battle ⚔️ 🤯Turns out, simple-to-build RAG can match million-dollar long-context LLMs (LC LLMs) on most existing benchmarks. 🤡So, do we even need long-context models? YES. Because today’s benchmarks are flawed: ⛳ Too Simple –
6
39
189

Lemur: A Single-Cell Foundation Model with Fine-Tuning-Free Hierarchical Cell-Type Generation for Drosophila melanogaster 1/ Lemur is a novel single-cell foundation model designed for Drosophila melanogaster, offering a fine-tuning-free approach for accurate cell-type
0
4
8
How do LLMs work? What is it about the recently-announced DeepSeek technology that has changed the way people think about building large AI models? Join us for the answers to these questions and more. Co-sponsored by Rice CS & @ricekenkennedy. RSVP: https://t.co/jVovSorinR
0
4
8

A bit late to mention this work led by the amazing Prof. Denghui Zhang @denghui_zhang - invented a novel approach to steer LLM’s internal states to prevent unsafe output. https://t.co/YpxnfUF2KL
https://t.co/ezGwn89aGu
0
17
109
Rice CS' @Anshumali_ Shrivastava & team have developed algorithms to make AI models more efficient & customizable. Their work is critical to how AI could be integrated into solving societal problems while meeting growing energy & computing demands. https://t.co/s0whUDaxDS
0
3
8