

Vikrant Varma
@VikrantVarma_
Followers
642
Following
39
Media
7
Statuses
20
Research Engineer working on AI alignment at DeepMind.
Joined July 2023
RT @rohinmshah: We're hiring! Join an elite team that sets an AGI safety approach for all of Google -- both through development and impleme….
0
37
0
RT @vkrakovna: We are excited to release a short course on AGI safety! The course offers a concise and accessible introduction to AI alignm….

deepmindsafetyresearch.medium.com
We are excited to release a short course on AGI safety for students, researchers and professionals interested in this topic. The course…
0
49
0

The most fun image & video creation tool in the world is here. Try it for free in the Grok App.
0
198
2K
RT @davlindner: New Google DeepMind safety paper! LLM agents are coming – how do we stop them finding complex plans to hack the reward?. Ou….
0
98
0
RL training can incentivise LLM agents to produce long-term alien plans, and evade monitoring. But in high-stakes settings, comprehensibility is critical. Our new paper shows how to change an agent’s incentives to *only* act in ways that we can understand.

New Google DeepMind safety paper! LLM agents are coming – how do we stop them finding complex plans to hack the reward?. Our method, MONA, prevents many such hacks, *even if* humans are unable to detect them!. Inspired by myopic optimization but better performance – details in🧵

1
1
7
Excited to see what people try with these shiny new open source SAEs! Great work by @sen_r and the team on pushing SOTA here.

New GDM mech interp paper led by @sen_r: JumpReLU SAEs a new SOTA SAE method! We replace standard ReLUs with discontinuous JumpReLUs & train directly for L0 with straight-through estimators. We'll soon release hundreds of open JumpReLU SAEs on Gemma 2, apply now for early access!

1
0
8
Very cool find by @sen_r, @ArthurConmy, and the rest of the DeepMind mechinterp team! I’m excited by the rate of progress here.

New @GoogleDeepMind MechInterp work! We introduce Gated SAEs, a Pareto improvement over existing sparse autoencoders. They find equally good reconstructions with around half as many firing features, while maintaining interpretability (CI 0-13% improvement). Joint w/ @ArthurConmy

0
0
6
I had fun talking to Daniel on his podcast AXRP! And I’ve enjoyed listening to his other episodes too :).

New episode of AXRP with @VikrantVarma_! We chat about his work on CCS and grokking. The transcript is in the linked tweet, or check out the reply for the YouTube video!.
0
0
0
Our latest paper shows that unsupervised methods on LLM activations don’t yet discover latent knowledge. Many things can satisfy knowledge-like properties besides ground truth. E.g a strongly opinionated character causes ~half the probes to detect *her* beliefs instead.

In our new @GoogleDeepMind paper, we redteam methods that aim to discover latent knowledge through unsupervised learning from LLM activation data. TL;DR: Existing methods can be easily distracted by other salient features in the prompt. 🧵👇

1
2
21
0
0
7
Thanks to my joint first author @rohinmshah, and my coauthors @ZacKenton1, @JanosKramar, and Ramana Kumar!.
1
1
15
There's still much we don't know. Why is the generalising circuit learned slower? Why does grokking happen in the absence of weight decay? Why don't we see grokking in typical ML training?. Check out our paper for speculation on these and much more

arxiv.org
One of the most surprising puzzles in neural network generalisation is grokking: a network with perfect training accuracy but poor generalisation will, upon further training, transition to perfect...
4
2
46
Prediction 3: Training runs with different amounts of weight decay should converge to the same test accuracy – since test accuracy at convergence depends on the ratio of Gen to Mem, which depends only on dataset size

3
2
29
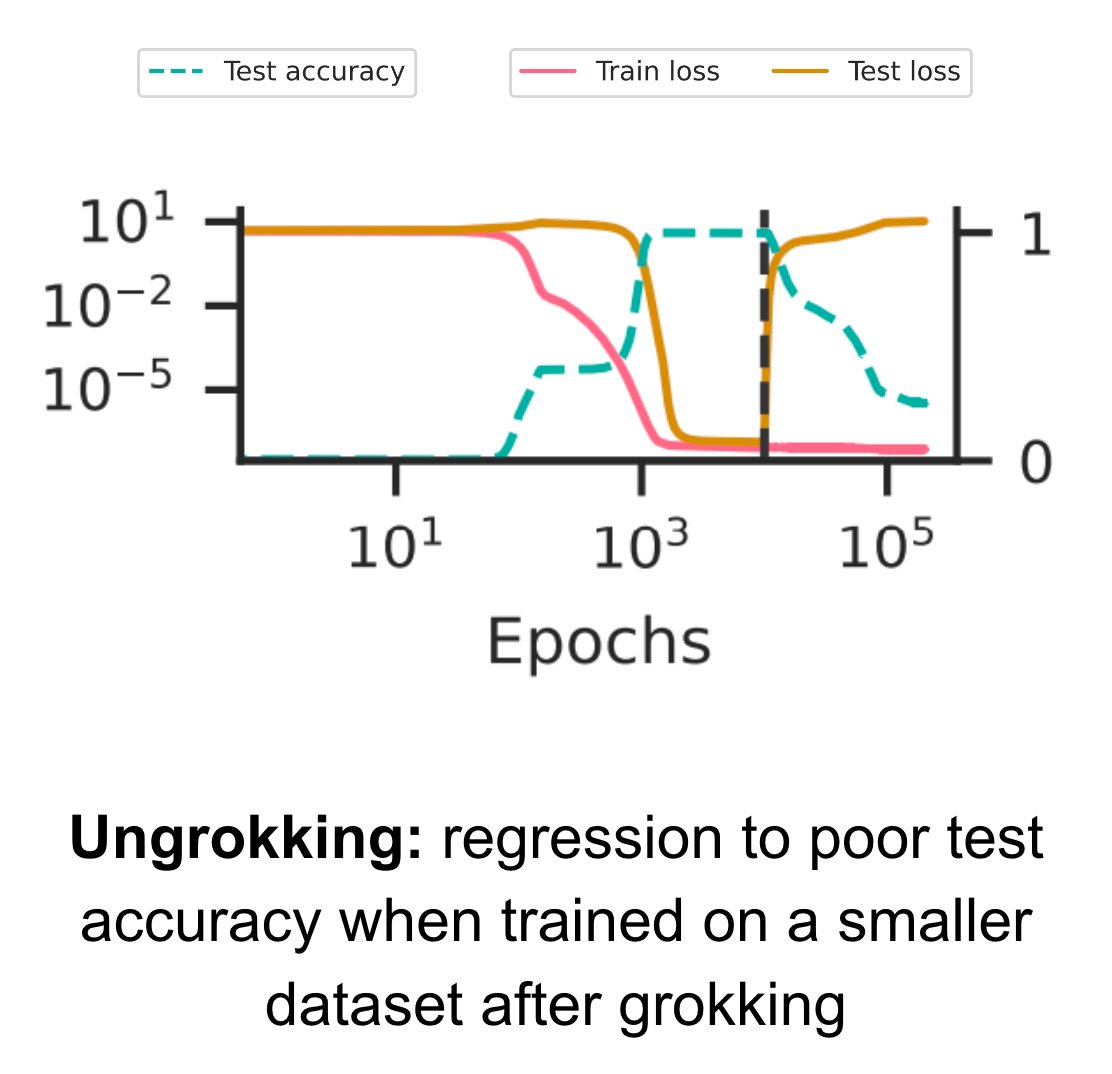
Prediction 2: Remember how Mem is really efficient at small dataset sizes? That suggests that, if you train a grokked network further on a really small subset of the data, the network should switch back to Mem, "ungrokking" to poor test accuracy

2
0
44
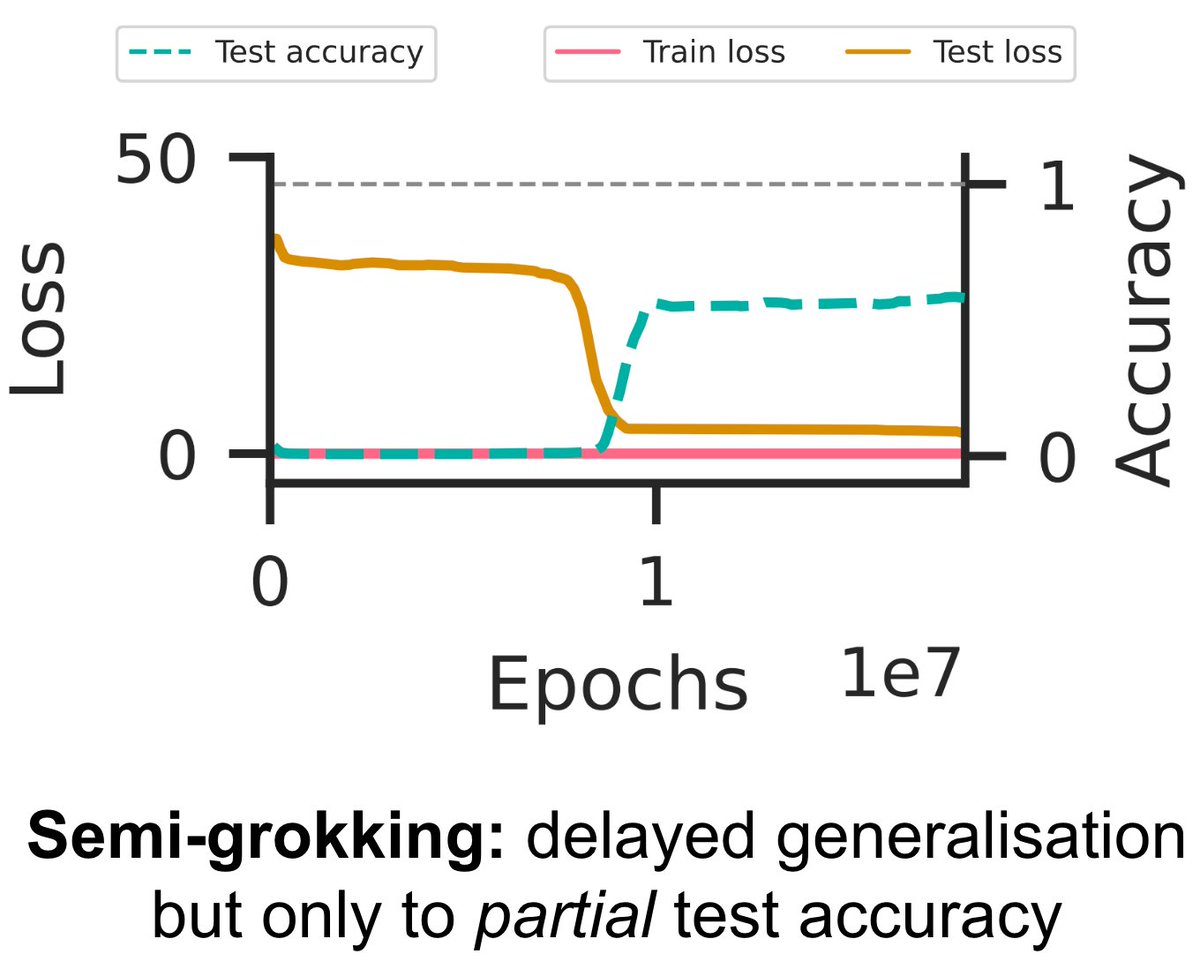
Prediction 1: there is a dataset size where Mem and Gen have similar efficiencies. If we train for long enough at that size, sometimes we should get a mix with similar proportions of Mem and Gen – resulting in "semi-grokking" to partial test accuracy 🤯

1
1
31
The strength of a scientific explanation is its ability to make interesting and novel predictions in new settings! Can our explanation make some striking new predictions? 🔬.
1
0
27
Why does the network bother memorising then? We hypothesise that generalisation is learned slowly. That gives us three ingredients which together are sufficient for grokking: (1) two circuits, Mem and Gen, (2) Gen is more efficient, (3) Gen is learned more slowly.



2
3
41
Answer: Gen is more *efficient*: it turns the same parameter norm into higher outputs than memorisation (and higher outputs = more confident predictions = lower loss). Mem is super efficient on small datasets, but Gen scales better with more data, and wins the efficiency race 🏎️


3
4
46
In grokking, a neural network first learns a memorising circuit "Mem" that memorises the training dataset, but with further training it switches to a generalising circuit "Gen". Key Q: why does the network ever change from Mem, which achieves near-perfect training loss?

1
2
52
Our latest paper ( provides a general theory explaining when and why grokking (aka delayed generalisation) occurs – a theory so precise that we can predict hyperparameters that lead to partial grokking, and design interventions that reverse grokking! 🧵👇
15
197
1K