

Soyoung Oh
@SoyoungOh5
Followers
47
Following
179
Media
0
Statuses
80
#NLProc traveler in the eye of #CogSci
Saarbrucken, Germany 🇩🇪
Joined June 2021

Do you know your LLM uses less than 1% of your GPU at inference? Too much time is wasted on KV cache memory access ➡️ We tackle this with the 🎁 Block Transformer: a global-to-local architecture that speeds up decoding up to 20x 🚀 @kaist_ai @LG_AI_Research w/ @GoogleDeepMind 🧵
12
116
622

🚨 New paper 🚨 How Large Language Models Acquire Factual Knowledge During Pretraining? I’m thrilled to announce the release of my new paper! 🎉 This research explores how LLMs acquire and retain factual knowledge during pretraining. Here are some key insights:
12
119
518

We just released mistral-finetune, the official repo and guide on how to fine-tune Mistral open-source models using LoRA: https://t.co/4JX3eNbbso Also released Mistral-7B-Instruct-v0.3 with support for function calling with Apache 2.0 license: https://t.co/OhZqy6AZVM
github.com
Contribute to mistralai/mistral-finetune development by creating an account on GitHub.
7
134
745

I'm extremely excited to announce "the big bomb"!: Neo and Matrix, that we're working on with colleagues and friends from open-source community, https://t.co/3IGOyVg82c, wuhan ai, and https://t.co/GsbWGKaSs1. Neo is the first fully-transparent bilingual large language model, with
8
48
193

➲ Mergoo is a new library for seamlessly merging multiple LLM experts and efficiently training the combined LLM from scratch Check it out on Github.
0
3
3

Excited to share something that we've needed since the early open RLHF days: RewardBench, the first benchmark for reward models. 1. We evaluated 30+ of the currently available RMs (w/ DPO too). 2. We created new datasets covering chat, safety, code, math, etc. We learned a lot.
111
151
449

🤏 Why do small Language Models underperform? We prove empirically and theoretically that the LM head on top of language models can limit performance through the softmax bottleneck phenomenon, especially when the hidden dimension <1000. 📄Paper: https://t.co/YkdQttDDSK (1/10)
17
124
605

Introducing our new work @corl_conf 2023, a novel brain-robot interface system: NOIR (Neural Signal Operated Intelligent Robots). Website: https://t.co/LZAQ8AmDRk Paper: https://t.co/tsI50UF92s 🧠🤖
18
175
739

Multimodal AI studies the info in each modality & how it relates or combines with other modalities. This past year, we've been working towards a **foundation** for multimodal AI: I'm excited to share our progress at #NeurIPS2023 & #ICMI2023: https://t.co/bfHybV3xcD see long 🧵:
2
80
266

📢 Introducing 🔗LINC, a neurosymbolic approach to logical reasoning w/ awesome co-first authors @theo_olausson, @ben_lipkin, and Cedegao Zhang + advisors Armando Solar-Lezama, Josh Tenenbaum, and @roger_p_levy! 📜 https://t.co/vW9MepnD6r 💻 https://t.co/Uv8fR8givY 🧵⬇️ (1/n)
1
31
133

Detecting Pretraining Data from Large Language Models We propose Min-K% Prob, a simple and effective method that can detect whether if a LLM was pretrained on the provided text without knowing the pretraining data. proj: https://t.co/ZpyuFA43Z1 abs: https://t.co/lDXkHp5cmw
8
160
738

Large language models like GPT-4 are excellent at solving tasks, but how good are their social skills? 🔬Besides showcasing, we focus on the systematic evaluation of social interactions between AI and human agents with SOTOPIA ( https://t.co/QisMkSBrTb)! (co-lead with @_Hao_Zhu)
4
29
85

📢IT'S OFFICIAL! 🇧🇷The ACM Conference on Fairness, Accountability, and Transparency #FAccT2024 will be held Monday, June 3rd through Thursday, June 6th, 2024 in Rio de Janeiro, Brazil! https://t.co/uIhXHmp0dY 📅Stay tuned for the CFP
4
89
285

Today in Nature, we show how a standard neural net, optimized for compositional skills, can mimic human systematic generalization (SG) in a head-to-head comparison. This is the capstone of a 5 year effort with Marco Baroni to make progress on SG. (1/8) https://t.co/DJMJLEoshT
24
381
2K

🚨 New paper! 🚨 We introduce Branch-Solve-Merge (BSM) reasoning in LLMs for: - Improving LLM-as-Evaluator: makes Llama 70B chat+BSM close to GPT4. GPT4+BSM is better than GPT4. - Constrained Story Generation: improves coherence & constraints satisfied. https://t.co/3vfrwHauXs
2
122
521

Introducing COLM ( https://t.co/7T42bAAQa4) the Conference on Language Modeling. A new research venue dedicated to the theory, practice, and applications of language models. Submissions: March 15 (it's pronounced "collum" 🕊️)
30
425
2K

Are LLMs reasoning based on deep understandings of truth and logic? Can LLMs hold & defend their own "reasoning"? Our #EMNLP23 findings paper ( https://t.co/tlwsGODZry) explores testing LLMs' reasoning by engaging them in a debate that probes deeper into their understanding.
3
35
107

Check out our paper on using #LLMs in #psychology 👇
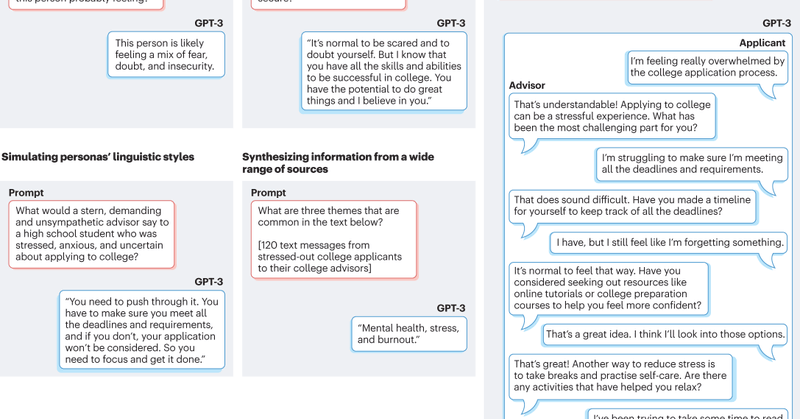
nature.com
Nature Reviews Psychology - Large language models (LLMs), which can generate and score text in human-like ways, have the potential to advance psychological measurement, experimentation and...

Using large language models in psychology: 💡 LLMs have the potential to advance psychological measurement, experimentation and practice. 💡 LLM generated on-topic, grammatically correct useless information, but not based on research and psychology construct. 💡A critical
2
34
183

Can LLMs translate reasoning into decision-making insights? Bad news: NO! Without any help, LLMs "thinking" doesn't really translate into "doing". Good news: A little bit of structure goes FaR! We present Foresee and Reflect (FaR), a 0-shot reasoning mechanism that boosts
9
62
248

Just published! 🥁 Hippocampal neurons reinstate specific episodic memories in humans. These Episode Specific Neurons are independent of Concept Neurons or Time Cells and code the conjunction of elements that make up the event. Check it out here: https://t.co/TEqPaS29s1
17
209
827