
Somnath Basu Roy Chowdhury
@SomnathBrc
Followers
98
Following
192
Media
27
Statuses
52
Research Scientist at Google Research
Joined January 2024
𝐇𝐨𝐰 𝐜𝐚𝐧 𝐰𝐞 𝐩𝐞𝐫𝐟𝐞𝐜𝐭𝐥𝐲 𝐞𝐫𝐚𝐬𝐞 𝐜𝐨𝐧𝐜𝐞𝐩𝐭𝐬 𝐟𝐫𝐨𝐦 𝐋𝐋𝐌𝐬?. Our method, Perfect Erasure Functions (PEF), erases concepts from LLM representations w/o parameter estimation, achieving pareto optimal erasure-utility tradeoff w/ guarantees. #AISTATS2025 🧵

2
35
153
0
2
0
@snigdhac25 (9/n) I’m attending ICLR in person and presenting our poster on 25th April in Poster session 3 between 10AM-1230PM. Please feel free to stop by our poster if you’re interested. I’m also happy to chat about unlearning or AI safety in general. cc: @uncnlp @unccs.
0
0
1
(8/n) Finally, I would like to thank all my amazing co-authors: Krzysztof, Arijit, Avinava, and @snigdhac25. Code: Paper link:
1
0
1
(7/n) Empirically, we observe that S³T can handle around 2.5x more deletion requests while achieving superior task performance compared to baselines

1
0
1
(6/n) Theoretically, we show that S³T achieves a better deletion rate than the existing SOTA exact unlearning technique, SISA. More interestingly, we observe that training the model only on B=L different permutations can achieve the best deletion performance.

1
0
1
(5/n) When we have access to deletion prior, we generate diverse permutations using the bipartite matching algorithm that considers the prior probabilities.

1
0
1
(4/n) To prevent this, we propose training the model on multiple sequences (or permutations) of the same data. While functioning within a budget, we generate diverse permutations using cyclic rotation when no prior deletion information is available.
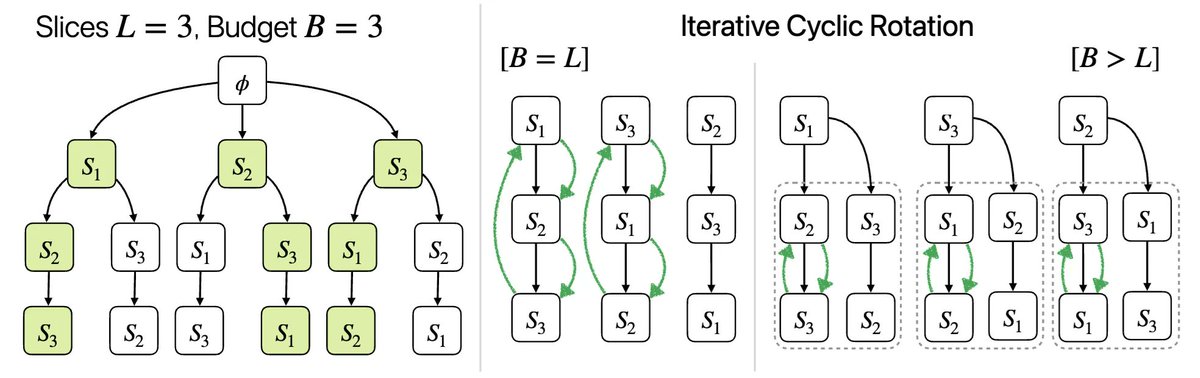
1
0
1
(3/n) We can easily unlearn data using S³T by switching off LoRA layers below the affected module. However, when the topmost module is affected in the rare scenario, we may need to retrain from scratch.

1
0
1
(2/n) We propose a sequential fine-tuning strategy that trains individual PEFT layers using different data subsets. This helps convert LLMs into a modular system that is helpful in executing exact unlearning.
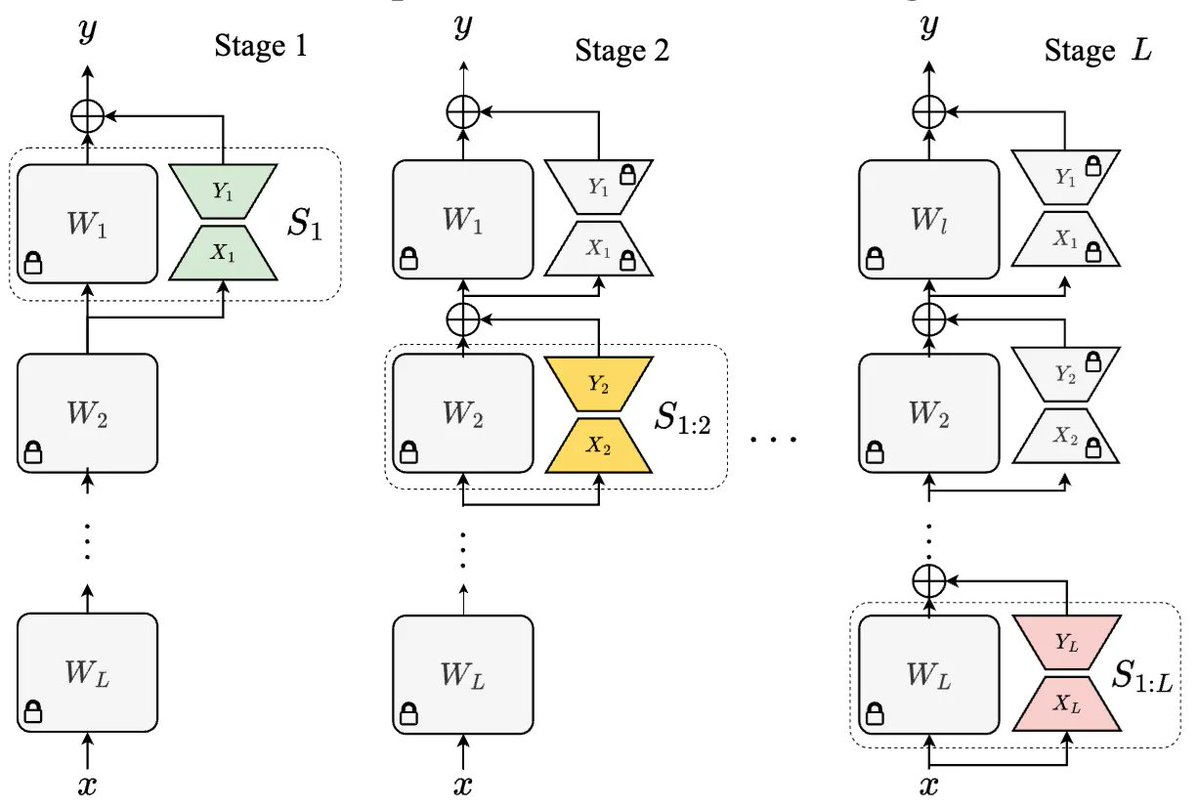
1
0
1
𝐇𝐨𝐰 𝐜𝐚𝐧 𝐰𝐞 𝐩𝐞𝐫𝐟𝐞𝐜𝐭𝐥𝐲 𝐮𝐧𝐥𝐞𝐚𝐫𝐧 𝐝𝐚𝐭𝐚 𝐟𝐫𝐨𝐦 𝐋𝐋𝐌𝐬 𝐰𝐡𝐢𝐥𝐞 𝐩𝐫𝐨𝐯𝐢𝐝𝐢𝐧𝐠 𝐠𝐮𝐚𝐫𝐚𝐧𝐭𝐞𝐞𝐬?. We present S³T, a scalable unlearning framework that guarantees data deletion from LLMs by leveraging parameter-efficient fine-tuning. #ICLR2025 🧵
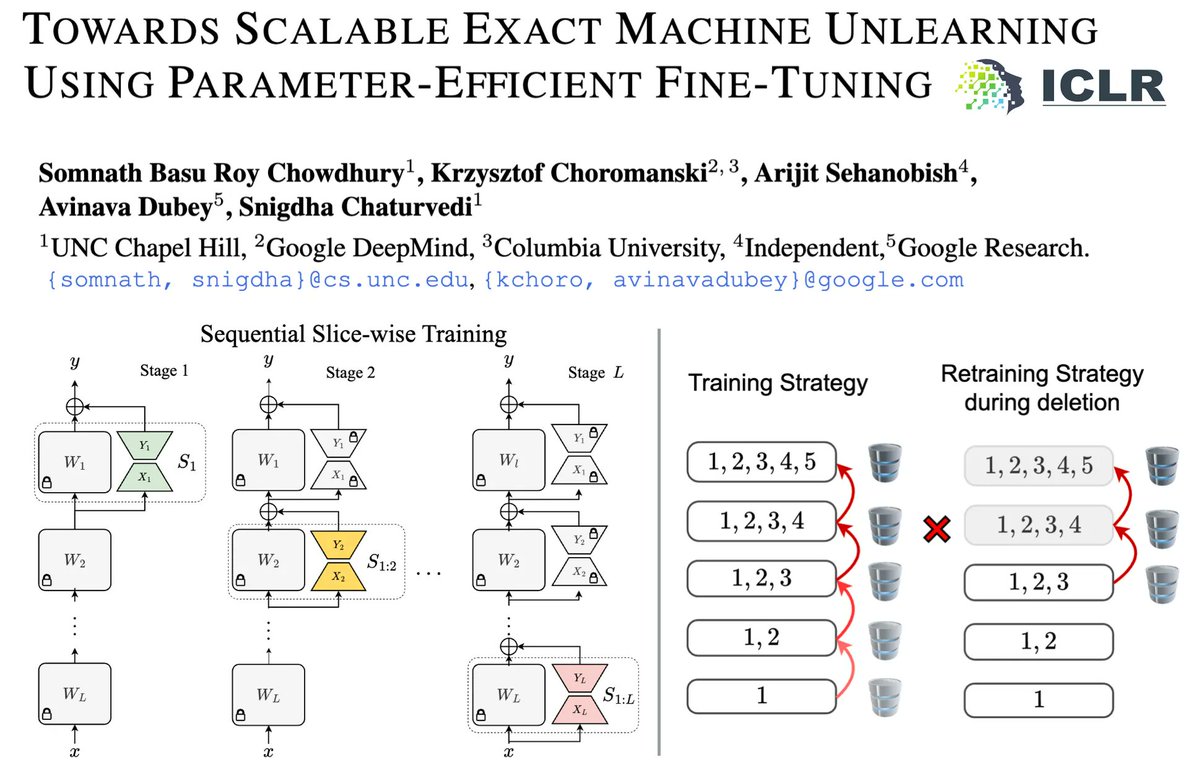
1
9
32
RT @abeirami: Finally, if you are also going to #AISTATS2025, @SomnathBrc will be presenting 𝐩𝐞𝐫𝐟𝐞𝐜𝐭 𝐜𝐨𝐧𝐜𝐞𝐩𝐭 𝐞𝐫𝐚𝐬𝐮𝐫𝐞. Somnath will be at I….
0
1
0
(9/n) Finally, I would like to thank all my amazing co-authors: Avinava, @abeirami, Rahul, @nicholasmonath, Amr, @snigdhac25. cc: @uncnlp @unccs.
0
0
3
(8/n) Here is a blog post with a simplified overview of our work: Code: Paper link:
1
0
2
(7/n) We would like to highlight previous great works, like LEACE, that perfectly erase concepts to protect against linear adversaries. In our work, we improve upon this method and present a technique that can protect against any adversary.


Ever wanted to mindwipe an LLM?. Our method, LEAst-squares Concept Erasure (LEACE), provably erases all linearly-encoded information about a concept from neural net activations. It does so surgically, inflicting minimal damage to other concepts. 🧵.
1
0
2
(6/n) We also visualize the learned representations from different erasure methods. We observe that PEF perfectly erasure group (or concept) information without losing other information (collapsing the representation space).

1
0
2
(5/n) Empirically, we observe that PEF reaches the theoretical limits of erasure even in challenging settings where other methods struggle, including both linear (INLP, LEACE) and non-linear techniques (FaRM, KRaM).

1
0
2
(4/n) When the distributions are unequal, we still achieve perfect erasure but with a slightly reduced utility. The erasure function in this setting is shown below.

1
0
2
(3/n) From the above limits, we show that optimally perfect concept erasure is only feasible when the underlying distributions are equal up to permutations. In such scenarios, the erasure function is shown in the diagram.

1
0
2
(2/n) We study the fundamental limits of concept erasure. Borrowing from the work of @FlavioCalmon et al. in information theory literature, we characterize the erasure capacity and maximum utility that can be retained during concept erasure.

1
0
3