
Siddhant Arora
@Sid_Arora_18
Followers
723
Following
1K
Media
57
Statuses
199
PhD student @LTIatCMU; Silver Medalist @iitdelhi
Joined January 2021
🚀 New #ICLR2025 Paper Alert! 🚀. Can Audio Foundation Models like Moshi and GPT-4o truly engage in natural conversations? 🗣️🔊. We benchmark their turn-taking abilities and uncover major gaps in conversational AI. 🧵👇. 📜:

3
11
48
RT @ShikharSSU: Meows, music, murmurs and more! We train a general purpose audio encoder and open source the code, checkpoints and evaluati….
0
15
0
RT @chenwanch1: I’ll be presenting this Thursday 4:30pm at the West hall, poster 418. Drop by to learn more about our latest experience i….
0
5
0
RT @chenwanch1: Not advertised yet, but we figured out how to do this too. And we release how exactly you can do it 👀. With the right trai….

arxiv.org
This paper presents Open Unified Speech Language Models (OpusLMs), a family of open foundational speech language models (SpeechLMs) up to 7B. Initialized from decoder-only text language models,...
0
5
0
RT @orevaahia: 🎉 We’re excited to introduce BLAB: Brutally Long Audio Bench, the first benchmark for evaluating long-form reasoning in audi….
0
47
0
More results and analyses can be found in our full paper. This was joint work with my co-authors at.@LTIatCMU and Sony Japan(.@shinjiw_at_cmu @MXzBFhjFpS1jyMI @emonosuke @jjungjjee @jiatongshi @WavLab). Code & models coming soon! (5/5).
0
0
1
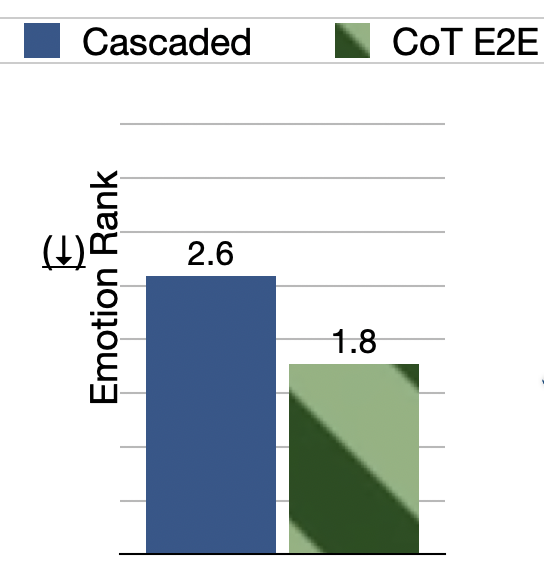
Compared to TTS in cascaded systems, our CoT approach enables more expressive speech synthesis by conditioning on the input speech—not just text—to generate the final spoken response. (4/5)
1
0
0
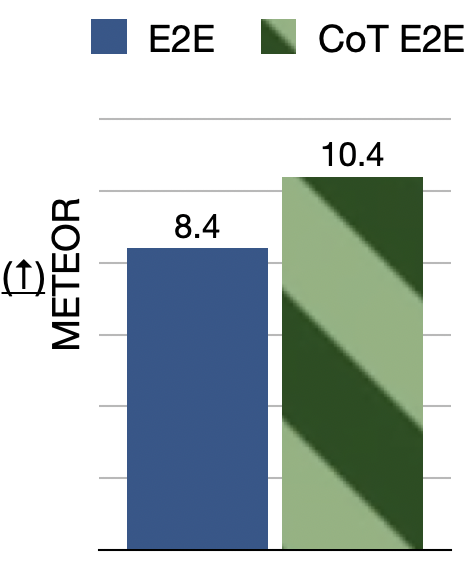
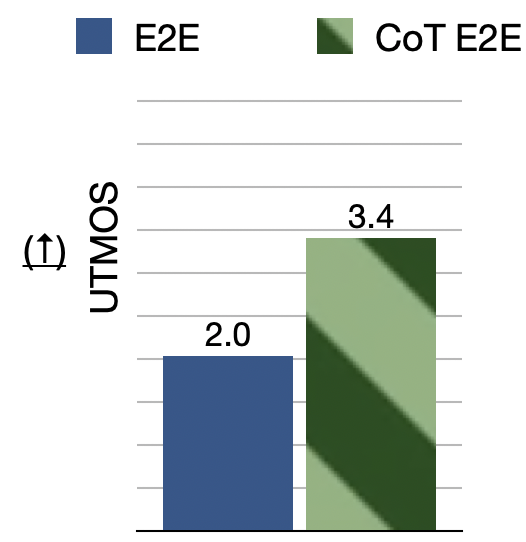
Compared to standard E2E systems, our CoT model improves both semantic coherence and speech quality via multi-stage reasoning. By aligning each stage with SpeechLM’s pretraining tasks (ASR, text LM, TTS), we get faster convergence and better data efficiency. (3/5)
1
0
0
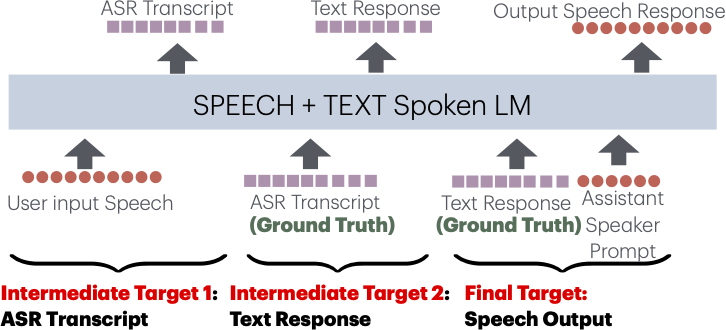
E2E spoken dialogue systems avoid error propagation & model non-phonemic cues But they lack structured reasoning & need huge training compute due to mismatch with pretaining setup. We tackle this with CoT training, predicting ASR & text response as intermediate targets. (2/5)

1
0
0
New #INTERSPEECH2025, we propose a Chain-of-Thought post-training method to build spoken dialogue systems—generating intelligent responses with good audio quality while preserving speaking styles with just 300h of public conversational data! (1/5).📜:
2
6
38

RT @mmiagshatoy: 🚀 Happy to share our #INTERSPEECH2025 paper:. Using speaker & acoustic context, we dynamically adjust model paths, resulti….
arxiv.org
Speech foundation models achieve strong generalization across languages and acoustic conditions, but require significant computational resources for inference. In the context of speech foundation...
0
11
0
RT @jiatongshi: 7/7 paper accepted to #Interspeech. Topic ranging from speech evaluation, data annotation/collection, SVC, multlinguality….
0
4
0
RT @chenwanch1: 7/7 papers accepted to #Interspeech2025 🎉. Lots of interesting work from my fantastic co-authors on long-form processing, m….
0
7
0
RT @emonosuke: Interspeech accepted🎉. Looking forward to going to netherland and talking about speech LLMs!.
0
3
0
RT @danish037: Our study highlighting plagiarism concerns in AI-generated research is now accepted to ACL (main conference): .
arxiv.org
Automating scientific research is considered the final frontier of science. Recently, several papers claim autonomous research agents can generate novel research ideas. Amidst the prevailing...
0
11
0
RT @chenwanch1: What happens if you scale Whisper to billions of parameters?. Our #ICML2025 paper develops scaling laws for ASR/ST models,….
0
33
0
RT @juice500ml: Can self-supervised models 🤖 understand allophony 🗣? Excited to share my new #NAACL2025 paper: Leveraging Allophony in Self….
0
18
0
Hi all, I will be in New Mexico for #NAACL2025! I'll present this work as poster on May 2 at the 9am session. Would love to catch up with folks working on speech processing and spoken dialogue systems!.
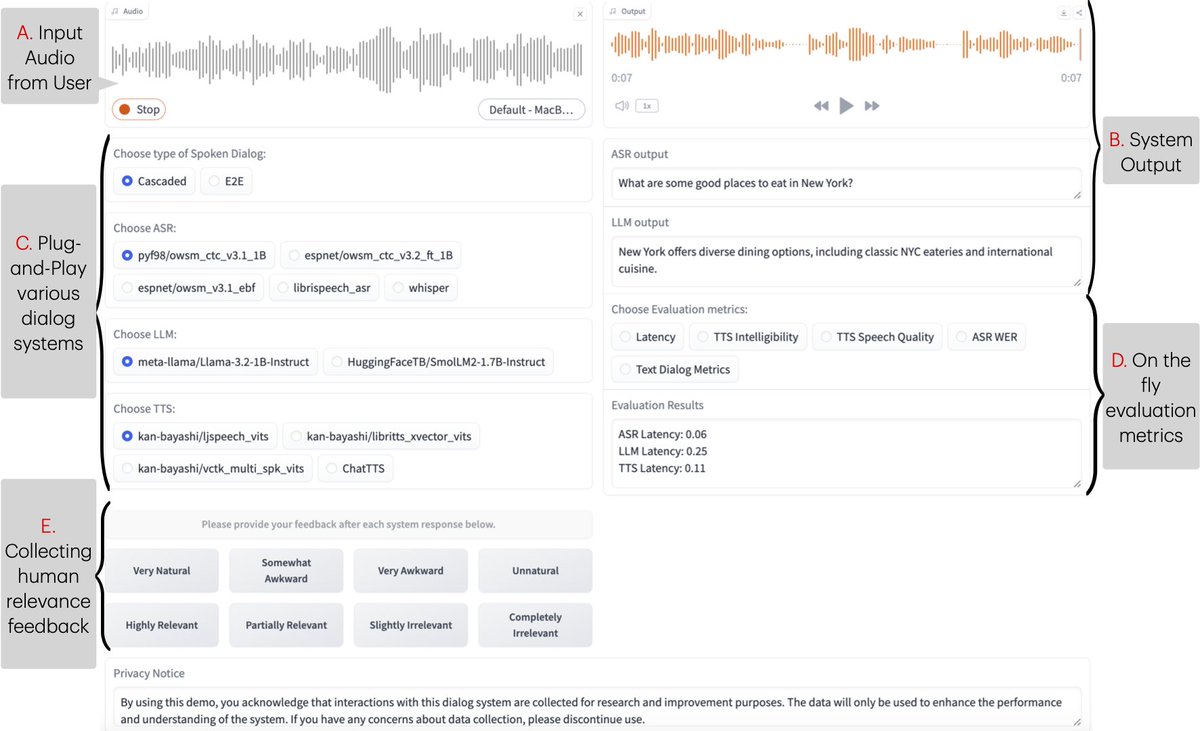
New #NAACL2025 demo, Excited to introduce ESPnet-SDS, a new open-source toolkit for building unified web interfaces for both cascaded & end-to-end spoken dialogue system, providing real-time evaluation, and more!.📜: Live Demo:
0
0
13
RT @jiatongshi: 📢 Introducing VERSA: our open-source toolkit for speech & audio evaluation! . 🧩 80+ metrics in one interface .🔧 Built with….
0
7
0
Hi all, I will be in Singapore for #ICLR2025! I'll present this work as poster on April 26 at the 10am session. Would love to catch up with folks working on speech processing and spoken dialogue systems!.
🚀 New #ICLR2025 Paper Alert! 🚀. Can Audio Foundation Models like Moshi and GPT-4o truly engage in natural conversations? 🗣️🔊. We benchmark their turn-taking abilities and uncover major gaps in conversational AI. 🧵👇. 📜:
3
3
25