
Ryan Sullivan
@RyanSullyvan
Followers
431
Following
1K
Media
15
Statuses
316
Postdoc @UBC_CS with @jeffclune (RL, Curriculum Learning, Open-Endedness) | PhD from @UofMaryland | Previously RL @SonyAI_global and RLHF @Google
Joined March 2013

This was a fun collaboration! Tdlr: ReAct is not all you need -- priming LMs to reason/plan intermittently in agentic tasks can improve the sample efficiency of multi-step RL Bonus: LM agents trained with this recipe can be steered with human-written plans at test-time

Almost all agentic pipelines prompt LLMs to explicitly plan before every action (ReAct), but turns out this isn't optimal for Multi-Step RL 🤔 Why? In our new work we highlight a crucial issue with ReAct and show that we should make and follow plans instead🧵

0
5
35

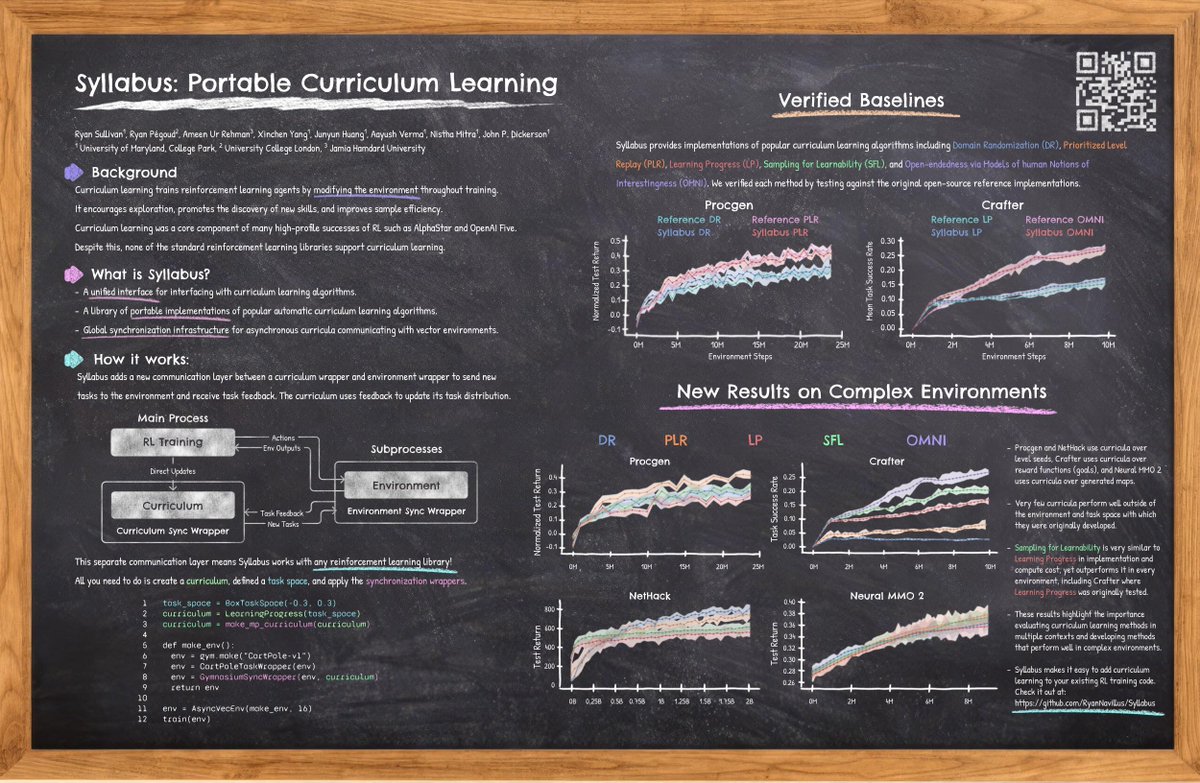
Finally there’s an efficient library for UED algs which doesn’t require Jax-accelerated environments. Great to have more options for UED researchers to supliment minimax and jaxUED. Also includes Robust PLR, SFL, and OMNI
We just released a new version of Syllabus! We have a demo notebook to help you get started, usability improvements, an implementation of Robust PLR, new versions of learning progress, and more! Check out this thread to learn how to get started with curriculum learning (CL)! 🧵
0
3
25
GitHub: https://t.co/K1AbUfZiXo Paper: https://t.co/5Pn6zKoOdC And Syllabus wouldn't exist without the original methods! PLR: https://t.co/w0Dw5cznFf Robust PLR: https://t.co/oWzwlPFMIx LP: https://t.co/Z9YgIsSHhI SFL: https://t.co/B0ocCrbIJA OMNI:
1
1
6
It's easier than ever experiment with CL, so try it out and tell me what you think! I'm happy to chat if you need help implementing your ideas with Syllabus. I plan to keep improving Syllabus, starting with more algorithms. If you're interested in contributing, please reach out!
1
0
6
We provide tools for sequentially playing tasks, stratified sampling, and automatically tracking your agent's progress. Or you can use one of the many state-of-the-art automatic CL methods implemented in Syllabus. Each method is fully tested and verified. https://t.co/TsQmq8ZHXI
Syllabus now includes tested and verified implementations of Prioritized Level Replay (+ Robust PLR), Learning Progress, OMNI, Sampling for Learnability, and Prioritized Fictitious Self Play. We also have tools for manually designing curricula from expert feedback.

1
0
4
Syllabus makes it easy to add CL to your RL training script in just a couple lines of code. You can see a full working example of how to create a curriculum to train CartPole agents in our demo notebook. Plus many more examples and baselines on GitHub! https://t.co/UvD3P8UymV
colab.research.google.com
Colab notebook
1
1
6
We just released a new version of Syllabus! We have a demo notebook to help you get started, usability improvements, an implementation of Robust PLR, new versions of learning progress, and more! Check out this thread to learn how to get started with curriculum learning (CL)! 🧵
2
12
59

E69: Outstanding Paper Award Winners 1/2 @RL_Conference 2025 @AlexDGoldie : How Should We Meta-Learn Reinforcement Learning Algorithms? @RyanSullyvan : Syllabus: Portable Curricula for Reinforcement Learning Agents @jsuarez5341 : PufferLib 2.0: Reinforcement Learning at 1M
1
2
38

PufferLib has won a best paper award for resourcefulness in reinforcement learning! Thank you to our entire open-source community + of course Spencer @spenccheng, who has built more of the environments than anyone else! Come chat with us in person today/tomorrow!

57
52
751
It was an honor to receive the Outstanding Paper Award on Tooling, Environments, and Evaluation in Reinforcement Learning for Syllabus! Come see my talk today at 10:20am in room CCIS 1-140 or check out our poster (#29) at 3pm!


5
3
88
If you want to try curriculum learning on your RL problem, check Syllabus out at https://t.co/K1AbUfZiXo and let us know what you think! Paper:

arxiv.org
Curriculum learning has been a quiet, yet crucial component of many high-profile successes of reinforcement learning. Despite this, it is still a niche topic that is not directly supported by any...
2
1
5
Curriculum learning is incredibly helpful in many standard RL benchmarks, However, naively applying these methods to complex envs is ineffective even with extensive tuning. We hope that these results will encourage future CL research to test on more diverse and complex tasks.
1
0
3
We compare each method on Procgen, Crafter, Nethack, and Neural MMO 2, and find that no single method performs the best on more than one environment. In fact, none of the curricula outperform domain randomization on NetHack and Neural MMO, the two most challenging environments.

1
0
4
Syllabus now includes tested and verified implementations of Prioritized Level Replay (+ Robust PLR), Learning Progress, OMNI, Sampling for Learnability, and Prioritized Fictitious Self Play. We also have tools for manually designing curricula from expert feedback.
1
0
2
Ive talked about Syllabus before here: https://t.co/fwVC60LjcV Since then we’ve added more algorithms, made it easier to use, and completed extensive baselines on several benchmarks to test how well CL algorithms generalize to new settings.
Have you ever wanted to add curriculum learning (CL) to an RL project but decided it wasn't worth the effort? I'm happy to announce the release of Syllabus, a library of portable curriculum learning methods that work with any RL code! https://t.co/K1AbUfYL7Q
1
0
2
I’m at @RL_Conference to present our work on Syllabus this week! Syllabus is a portable curriculum learning library that makes it easy for researchers to add CL to their RL projects. Using Syllabus, we found that many automatic CL baselines don't generalize to complex envs 🧵
1
0
38

Are you a strong builder - of software, of community, of the future of open source AI? We're hiring software engineers, DevRel, & more @MozillaAI! Join a growing, well-funded, mission-driven team 🦊 building a sustainable open source future. Link:
1
2
8





✨Introducing SENSEI✨ We bring semantically meaningful exploration to model-based RL using VLMs. With intrinsic rewards for novel yet useful behaviors, SENSEI showcases strong exploration in MiniHack, Pokémon Red & Robodesk. Accepted at ICML 2025🎉 Joint work with @cgumbsch 🧵
2
36
150

I'm happy to share that our Time-Aware World Model (TAWM) has been accepted to #ICML2025! 🎆 By conditioning world model on time steps, we can train a policy that adapts to varying observation frequencies as shown below 👇 (note that TAWM-based policy successfully closes the box
I will be presenting our work on Time-Aware World Model (TAWM) at #ICML2025 next Tuesday (Jul 15) at West Exhibition Hall B2-B3 W-703! ✍️Authors: @anh_n_nhu , @SanghyunSon , Ming Lin. 📄 Arxiv: https://t.co/HSVTcxsLDr 🖥️Page: https://t.co/cWhDhXmVAf 👇 More details below:
0
3
14