Parmida Beigi
@ParmidaBeigi
Followers
2K
Following
351
Media
69
Statuses
237
AI/ML Lead @amazon AGI: search, graphs, LLMs/GenAI | Founder @bdqai | Advisory Board Member | PhD @ECEUBC | views=mine
San Francisco, CA
Joined March 2012
RT @YuHelenYu: Is #GenAI going to improve customer service in financial services?. Did you know, according to Qualtrics, bad customer exper….
0
13
0
RT @Ronald_vanLoon: The History of #AI.by @ParmidaBeigi. #BigData #ArtificialIntelligence #ML #MI #DataScience #MachineLearning. cc: @pasca….
0
23
0
RT @aselipsky: Claude 3 Opus, the powerhouse AI model from @AnthropicAI, is now available on Amazon Bedrock. Opus can tackle highly compl….
0
51
0
RT @AnthropicAI: Today, we're announcing Claude 3, our next generation of AI models. The three state-of-the-art models—Claude 3 Opus, Cla….
0
2K
0
RT @AmazonScience: Amazon has publicly released RefChecker, a combination tool and dataset that detects hallucinations in #LLMs. To charact….

amazon.science
Representing facts using knowledge triplets rather than natural language enables finer-grained judgments.
0
19
0
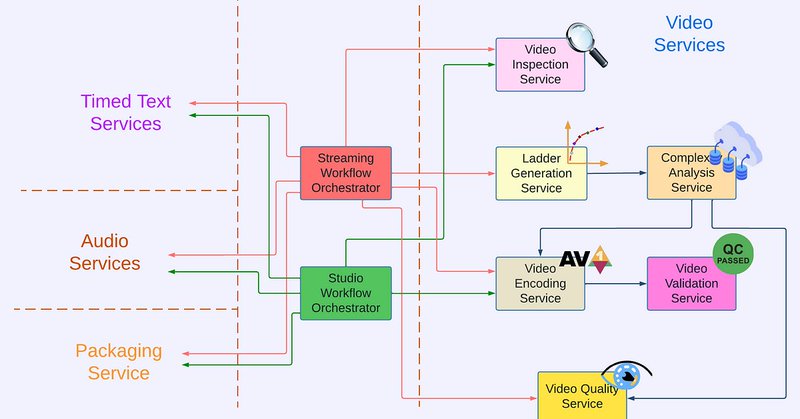
RT @Werner: The first article of a series at the @netflix technology blog: "Rebuilding Netflix Video Processing Pipeline with Microservice….
netflixtechblog.com
This is the first blog in a multi-part series on how Netflix rebuilt its video processing pipeline with microservices, so we can maintain…
0
77
0
RT @Ronald_vanLoon: The History of #AI.by @ParmidaBeigi . #BigData #ArtificialIntelligence #ML #MI #DataScience. cc: @pascal_bornet @yvesmu….
0
24
0
RT @TEDxSFU: ❓Will AI be the future? Unmask the AI with Parmida Beigi, a true Artificial Intelligence and Machine Learning visionary, resea….
0
5
0
RT @AmazonScience: The emergence of open source LLMs led to the potential generation of toxic outputs. Amazon Bedrock, the latest step in t….
0
11
0
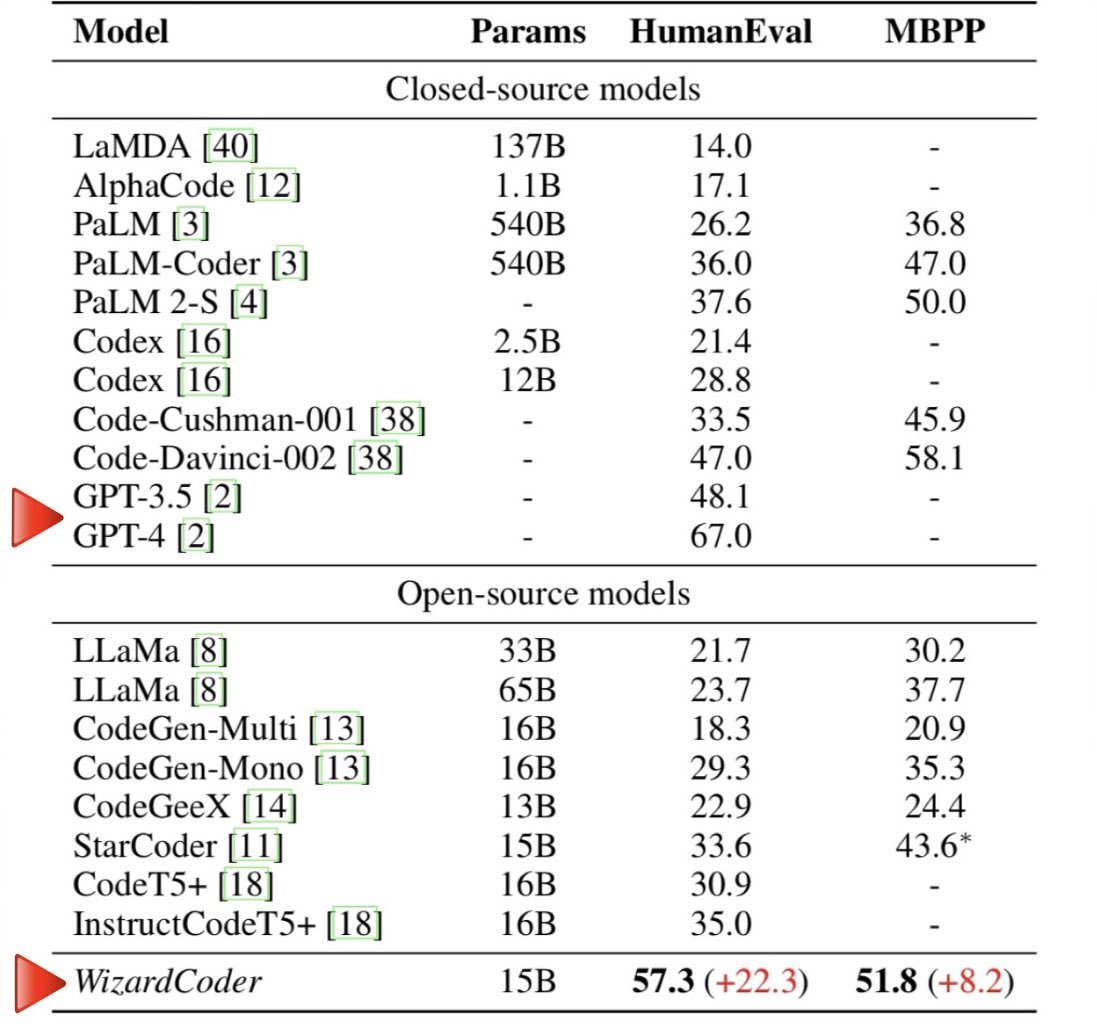
First fine-tuned model outperforming GPT-4 💥. I've been eagerly awaiting what comes next🔻after 15B WizardCoder: surpassing Claude-Plus and Bard on HumanEval. And 𝗷𝘂𝘀𝘁 𝘁𝗼𝗱𝗮𝘆, 34B model is released, 𝘀𝘂𝗿𝗽𝗮𝘀𝘀𝗶𝗻𝗴 𝗚𝗣𝗧-𝟰 (March model)!.
0
3
9
Lighter and faster LLMs with 🤗 Transformers 🤝 AutoGPTQ!. 1. Low GPU memory usage.2. Fast inference speed. Results of GPTQ quantization. 🧮. Try it out ⬇️. 🔗 Blog post: 📒 Google colab:
0
6
10
RT @antgrasso: Six techniques for data privacy include encrypted data analysis, obscuring individual data with noise, controlled access to….
0
77
0
This is from a paper released by Stanford and Berkeley yesterday. Cool findings 👉

0
0
5
GPT-4 is getting worse over time!. It’s even skipped the "Chain-of-Thought" prompting when instructed to. This is why LLMs need continuous maintenance and monitoring! Let it train on all input data it received and become a biased, even more "confabulated" bot :).
1
2
8
RT @_philschmid: Streamline your LLM training with Amazon SageMaker! 👷♂️Thrilled to share a new blog post on how to leverage @awscloud Sag….

philschmid.de
Learn how to train LLMs using QLoRA on Amazon SageMaker
0
39
0
RT @historyinmemes: A group of four NASA volunteers has embarked on a 378-day mission in which they will be locked in a ground-based simula….
0
4K
0
RT @AmazonScience: Congrats to the 8 university teams who have advanced to the #AlexaPrize TaskBot Challenge 2 semifinals. Learn more about….
0
5
0