

Jiacheng Zhu
@JiachengZhu_ML
Followers
1K
Following
2K
Media
5
Statuses
136
Research Scientist at @AIatMeta GenAI, Postdoc at @MIT_CSAIL and PhD from @CarnegieMellon | Prev. @Apple AI/ML @MITIBMLab | Working on Llama post-training
Joined October 2019
RT @RickardGabriels: 💡 Our new work at @ICML2025:.Serve thousands of LoRA adapters with minimal overhead—a step towards enabling LLM person….
0
7
0
RT @balesni: A simple AGI safety technique: AI’s thoughts are in plain English, just read them. We know it works, with OK (not perfect) tra….
0
108
0
RT @karpathy: Scaling up RL is all the rage right now, I had a chat with a friend about it yesterday. I'm fairly certain RL will continue t….
0
858
0
RT @Hongyu_Lii: We interact with dogs through touch -- a simple pat can communicate trust or instruction. Shouldn't interacting with robot….
0
26
0
RT @_vztu: 🤨Ever dream of a tool that can magically restore and upscale any (low-res) photo to crystal-clear 4K? . 🔥Introducing "4KAgent: A….
0
43
0
RT @Happylemon56775: Excited to share what I worked on during my time at Meta. - We introduce a Triton-accelerated Transformer with *2-sim….
0
96
0
RT @hardmaru: Reinforcement Learning Teachers of Test Time Scaling. In this new paper, we introduce a new way to teach LLMs how to reason b….
0
123
0
RT @YiqingLiang2: Heading to Nashville for @CVPR ! 🎸.I’ll be presenting the @nvidia internship project —. “Zero-Shot Monocular Scene Flow E….
0
6
0
This is an amazing joint-force with @_Jason_Q , @wenhaoding95 @LiuZuxin @jtompkin @mengdixu_ @xiamengzhou @_vztu @ShiLaixi , lead by @YiqingLiang2 !.
🚀 New preprint: “MoDoMoDo — Multi-Domain Data Mixtures for Multimodal LLM RL” is live!. 🔗 Paper + project: (project page . 💻 Code: coming soon. Highlights. * Multimodal RLVR framework that post-trains an MLLM on 5 vision-language.
0
3
14
🚀 New preprint: “MoDoMoDo — Multi-Domain Data Mixtures for Multimodal LLM RL” is live!. 🔗 Paper + project: (project page . 💻 Code: coming soon. Highlights. * Multimodal RLVR framework that post-trains an MLLM on 5 vision-language.
lnkd.in
This link will take you to a page that’s not on LinkedIn

🧵 MoDoMoDo: smarter data mixing → stronger reasoning for multimodal LLMs.🚀 New preprint! We show how right mixing of multi-domain data can super‑charge multimodal LLM RL reasoning. 🌐 Site: 📄 Paper: details in thread. 👇

1
3
15
RT @YiqingLiang2: 🔬 I am super excited to announce our @ICCVConference 2025 Workshop: End‑to‑End 3D Learning (E2E3D) 🔬.& 📢 Call for Papers….
0
10
0
RT @ICL_at_CMU: 🎉 Congrats to Prof Changliu Liu @ChangliuL on IEEE RAS Early Academic Career Award in Robotics and Automation "for signific….
0
4
0
RT @angelaqdai: What an amazing start to our #Eurographics2025 keynotes from @JustinMSolomon on optimization for geometry processing - lots….
0
10
0
RT @ShiLaixi: 🚀We have two exciting works at ICLR!.1) Oral: Behavioral Economics in Decision Making within Robust Multi-Agent Systems — Com….
0
13
0
RT @ShunyuYao12: I finally wrote another blogpost: AI just keeps getting better over time, but NOW is a special mo….
0
188
0
Our first batch of Llama 4 models are out! 🦙🦙🦙🦙Please give them a try! 🚀. Proud to be part of team that baked these amazing models! . P.S. LLM post-training is a magic yet not magic. Excited about future Llama models!.

Today is the start of a new era of natively multimodal AI innovation. Today, we’re introducing the first Llama 4 models: Llama 4 Scout and Llama 4 Maverick — our most advanced models yet and the best in their class for multimodality. Llama 4 Scout.• 17B-active-parameter model
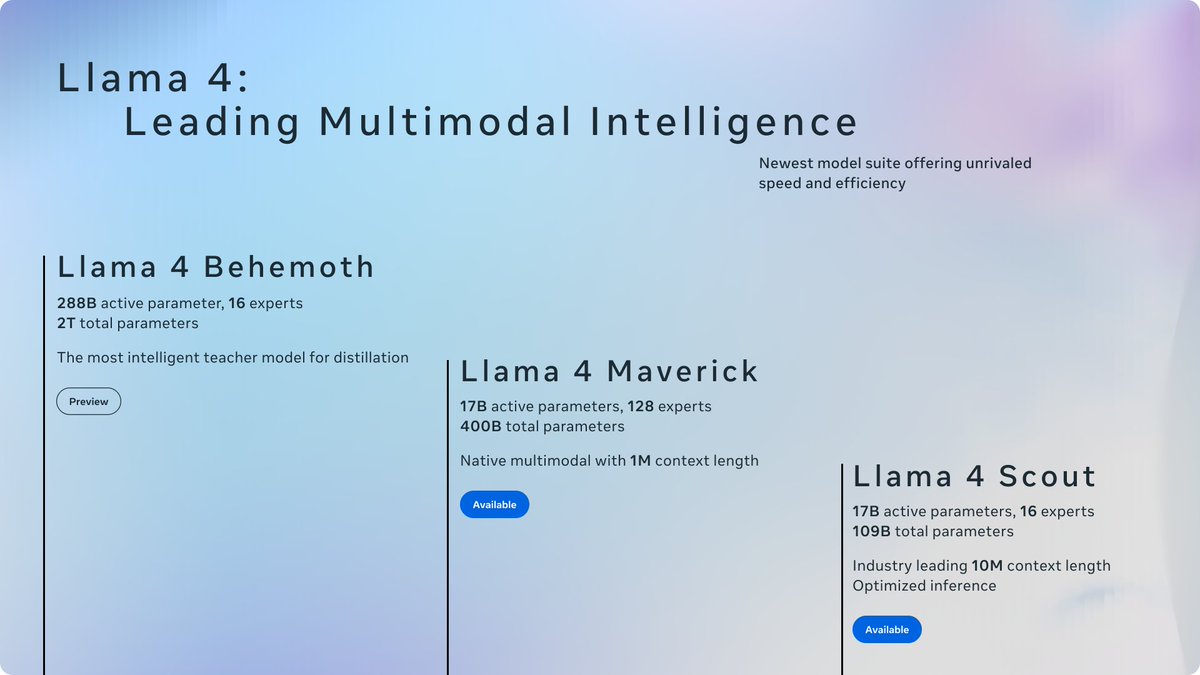
1
0
26
RT @AIatMeta: Today is the start of a new era of natively multimodal AI innovation. Today, we’re introducing the first Llama 4 models: Lla….
0
2K
0
RT @tw_killian: I’m talking to my church youth group this week about how to discern what and what not to trust on the internet + genAI cont….
0
2
0
RT @StockMKTNewz: Apple and Meta are both now reportedly planning to ramp up development on Humanoid Robots joining Magnificent 7 names lik….
0
458
0