
Filip Graliński
@FilipGralinski
Followers
110
Following
60
Media
45
Statuses
203
6502 and Haskell hacker, machine learner, hypopolyglot (many languages, all poor), opposite Pole, skeptical forteanist
Joined September 2021

Day 2 of #SnowflakeSummit flew by but not before a mountain of announcements from our Platform Keynote! We announced: Adaptive Compute, Snowflake Openflow, Cortex AISQL, Semantic Model Sharing, Snowflake Intelligence, and much more. See what's new: https://t.co/XMRU4FdlU8
3
3
14

How can the most accurate SQL be generated for a given question? We propose a method to significantly boost text-to-SQL accuracy while drastically cutting costs.👇 #NLProc #AI #TextToSQL #LLMs

2
3
56

Our Snowflake AI Research team just released Arctic Embed’s core training code into the open source ArcticTraining project — making it easier for developers and researchers to reproduce, fine-tune, and build on our embedding models. Arctic Embed is the leading small embedding
4
5
15

Connor Shorten was kind enough to give me the mic for a lot of hot takes on text embedding models in the latest Weaviate podcast.

Arctic Embed ❄️ has been one of the most impactful open-source text embedding models! In addition to the open model, which has helped a lot of companies kick off their own inference and fine-tuning services (including us), the Snowflake team has also published incredible research

1
4
11

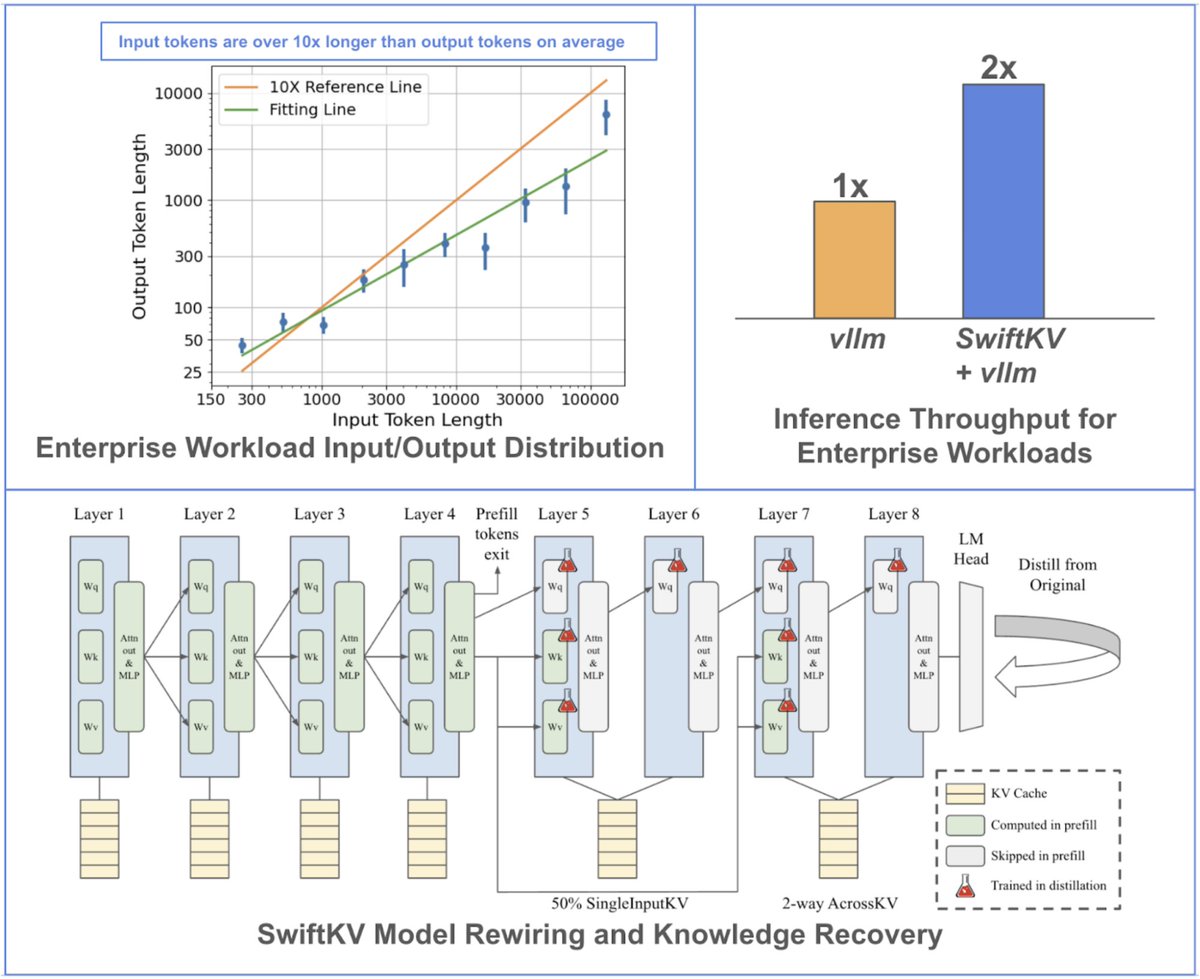
We are excited to share SwiftKV, our recent work at @SnowflakeDB AI Research! SwiftKV reduces the pre-fill compute for enterprise LLM inference by up to 2x, resulting in higher serving throughput for input-heavy workloads. 🧵
4
16
43

🚀 I am thrilled to introduce @SnowflakeDB 's Arctic Embed 2.0 embedding models! 2.0 offers high-quality multilingual performance with all the greatness of our prior embedding models (MRL, Apache-2 license, great English retrieval, inference efficiency) https://t.co/hEcd0niVyr🌍
snowflake.com
8
27
79


Can AI models help us create better models? 🧵 1/ It's a question that stands at the boundaries of what's possible in data science. We explored how Large Language Models (LLMs) perform as data scientists, especially in the art of feature engineering.

1
1
3

A joint study by @poznanAI researchers and Samsung Electronics Polska engineers was presented at @FedCSIS 2024. The paper investigates the impact of augmenting spoken language corpora with domain-specific synthetic samples. https://t.co/NhkDOc7xI2

0
3
4
Good people out there, please make your Python script more command-line friendly: 1. put this as the first line: #!/usr/bin/env python3 2. set x permission: chmod u+x your_script.py (and commit that to git) Now you I can run your script with ./your_script.py. Thank you!
0
0
1
It's fall which means it's intern recruitment time! @SnowflakeDB is widely recruiting research interns to work on all kinds of problems around AI/LLM/Search. If you are interested or know any students who are looking for summer 2025 internships hit me up!
1
9
31

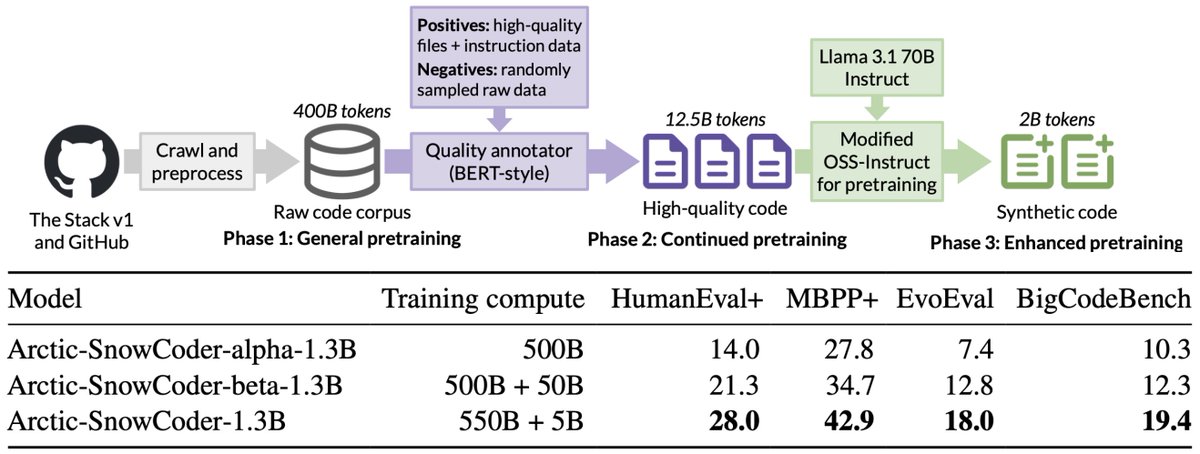
Code LLMs involve multiple stages of training. At Snowflake, we did extensive training ablations across general repo data, high quality filtered data, and synthetic instruction data so you don’t have to. 🧵
1
6
32



LLM Bielik v2 on our internal benchmark, based on Polish educational and professional tests, achieves an accuracy score of 58.03%. This is a noticeable improvement over the 41,51% in v.0.1. Congratulations to the entire @Speak_Leash team. More extensive results coming 🔜
0
1
2
This new LLM for Polish looks really interesting, congrats to the team!

The wait is over - Bielik v2 is here!🦅 Here’s what it offers: 💪11B parameters 📈32,768 token context window 🚝Enhanced training data ⌨Improved NLP 🤝Flexible deployment Made possible through our collaboration with @Cyfronet Check it out here:
0
0
1

Some lessons (I) learnt preparing the data mixture for Snowflake Arctic LLM 👨🍳

1
2
9