

Jiarui Yao
@ExplainMiracles
Followers
85
Following
47
Media
2
Statuses
19
RT @qiancheng1231: 🤝 Can LLM agents really understand us?. We introduce UserBench: a user-centric gym environment for benchmarking how well….
0
31
0
RT @Yong18850571: (1/4)🚨 Introducing Goedel-Prover V2 🚨.🔥🔥🔥 The strongest open-source theorem prover to date. 🥇 #1 on PutnamBench: Solves 6….
0
86
0
RT @noamrazin: Reward models (RMs) are key to language model post-training and inference pipelines. But, little is known about the relative….
0
20
0
RT @shulin_tian: 🎥 Video is already a tough modality for reasoning. Egocentric video? Even tougher! It is longer, messier, and harder. 💡 H….
0
9
0
RT @xiusi_chen: Can LLMs make rational decisions like human experts?. 📖Introducing DecisionFlow: Advancing Large Language Model as Principl….
0
16
0
RT @peixuanhakhan: (1/5) Want to make your LLM a skilled persuader?. Check out our latest paper: "ToMAP: Training Opponent-Aware LLM Persua….
0
6
0
RT @qiancheng1231: 📢 New Paper Drop: From Solving to Modeling!.LLMs can solve math problems — but can they model the real world? 🌍. 📄 arXiv….
0
30
0
RT @hendrydong: How to improve the test-time scalability?.- Separate thinking & solution phases to control performance under budget constra….
huggingface.co
0
21
0
RT @xiusi_chen: 🚀 Can we cast reward modeling as a reasoning task?. 📖 Introducing our new paper: .RM-R1: Reward Modeling as Reasoning. 📑 Pa….
0
47
0
We introduce Gradient Variance Minimization (GVM)-RAFT, a principled dynamic sampling strategy that minimizes gradient variance to improve the efficiency of chain-of-thought (CoT) training in LLMs. – Achieves 2–4× faster convergence than RAFT.– Improves accuracy on math


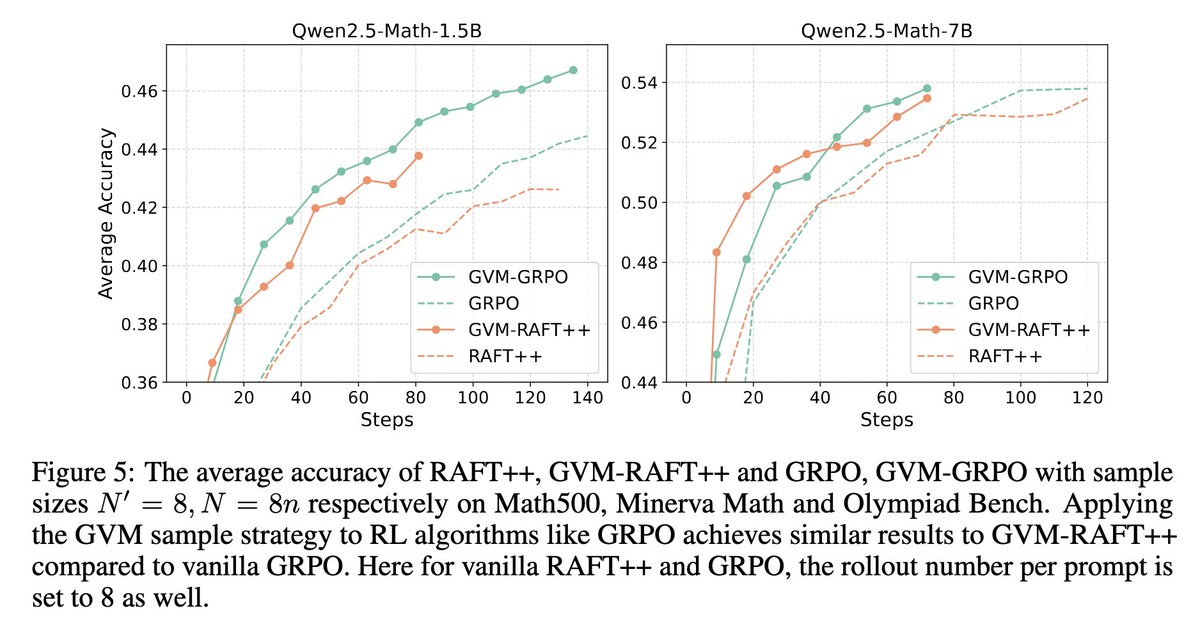

0
27
89
RT @HaochengXiUCB: Thrilled to announce that our paper Sparse VideoGen got into #ICML2025! 🎉. Our new approach to speedup Video Generation….
arxiv.org
Diffusion Transformers (DiTs) dominate video generation but their high computational cost severely limits real-world applicability, usually requiring tens of minutes to generate a few seconds of...
0
14
0
RT @ManlingLi_: Welcome to join our Tutorial on Foundation Models Meet Embodied Agents, with @YunzhuLiYZ @maojiayuan @wenlong_huang !. Webs….
0
40
0
RT @shizhediao: Thrilled to share my first project at NVIDIA! ✨. Today’s language models are pre-trained on vast and chaotic Internet texts….
0
55
0
Negative samples are "not that important", while removing samples with all negative outputs is "important". 🤣.

🤖What makes GRPO work?.Rejection Sampling→Reinforce→GRPO.- RS is underrated.- Key of GRPO: implicitly remove prompts without correct answer.- Reinforce+Filtering > GRPO (better KL).💻📄👀RAFT was invited to ICLR25! Come & Chat☕️.
0
0
2
In addition, we'd like to thank Yong Lin, et al. @Yong18850571 and @deepseek_ai for opening source their great formal reasoning models, based on which we implement our pipeline 🎉.
0
1
1
We introduces formal language (specifically, lean4) for answer selection in math reasoning task. It could indeed help to select the correct answer, especially in the number theory and algebra subfields which lean4 is better at.

We are glad to see this exciting work that uses our Goedel-Prover to enhance general models' math reasoning. "Given an NL math question and LLM-generated answers, FANS first translates it into Lean4 theorem statements. Then it tries to prove it using a

1
1
1
RT @qiancheng1231: 🚀Can your language model think strategically?.🧠 SMART: Boosting LM self-awareness to reduce Tool Overuse & optimize reas….
0
37
0
RT @HanningZhangHK: 🚀 Excited to share our latest work on Iterative-DPO for math reasoning! Inspired by DeepSeek-R1 & rule-based PPO, we tr….
0
25
0