
Daniela Amodei
@DanielaAmodei
Followers
10K
Following
255
Media
1
Statuses
29
President @AnthropicAI. Formerly @OpenAI, @Stripe, congressional staffer, global development
San Francisco, CA
Joined September 2011
Introducing Claude 2! Our latest model has improved performance in coding, math and reasoning. It can produce longer responses, and is available in a new public-facing beta website at https://t.co/uLbS2JNczH in the US and UK.

163
507
2K
Neural networks often pack many unrelated concepts into a single neuron – a puzzling phenomenon known as 'polysemanticity' which makes interpretability much more challenging. In our latest work, we build toy models where the origins of polysemanticity can be fully understood.
54
637
4K
In "Language Models (Mostly) Know What They Know", we show that language models can evaluate whether what they say is true, and predict ahead of time whether they'll be able to answer questions correctly. https://t.co/ZmZJqycb39

17
156
914
Transformer MLP neurons are challenging to understand. We find that using a different activation function (Softmax Linear Units or SoLU) increases the fraction of neurons that appear to respond to understandable features without any performance penalty. https://t.co/5ew6iWHYtl

10
70
373
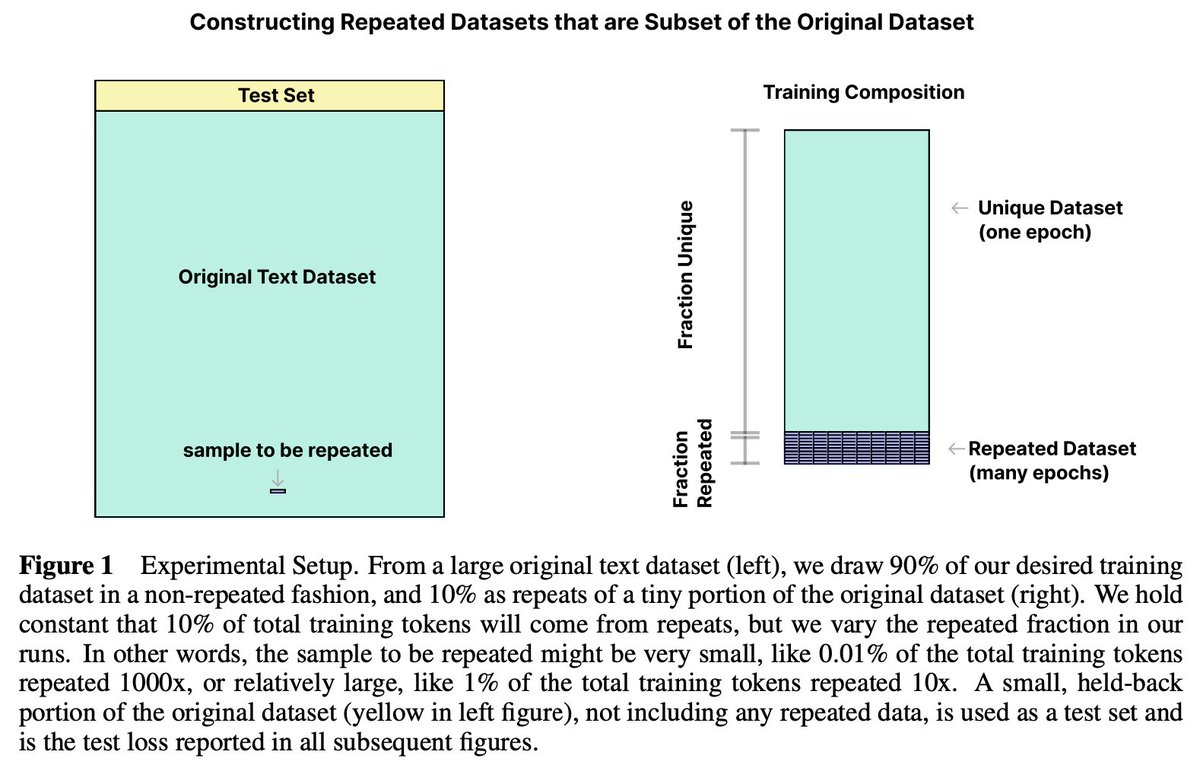
In a new paper, we show that repeating only a small fraction of the data used to train a language model (albeit many times) can damage performance significantly, and we observe a "double descent" phenomenon associated with this. https://t.co/kkUdDSRJTI
6
41
324
I’m looking forward to what’s to come. And we’re hiring!

anthropic.com
Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.
3
1
20
As well as steerability and robustness - https://t.co/gVvzRHUxfS - reinforcement learning - https://t.co/LDMFcSOYRV, societal impacts - https://t.co/QwJQzaboBK, and more!

arxiv.org
Large-scale pre-training has recently emerged as a technique for creating capable, general purpose, generative models such as GPT-3, Megatron-Turing NLG, Gopher, and many others. In this paper, we...
1
0
17
This includes work on interpretability - https://t.co/wDhLbDY6Vi and https://t.co/yCiURyUZ8d - and some interpretability resources like Garcon https://t.co/9MNd6adVAI and Pysvelte
github.com
A library for bridging Python and HTML/Javascript (via Svelte) for creating interactive visualizations - anthropics/PySvelte
1
0
6
I’m so proud of the amazing team we’ve assembled at Anthropic and the research we’ve done to date.
1
0
9
Excited to announce our latest fundraising round! We’re genuinely honored to be entrusted with the resources to continue our work in frontier AI safety and research.

We’ve raised $580 million in a Series B. This will help us further develop our research to build usable, reliable AI systems. Find out more:
8
5
82
Glad @QuantaMagazine highlights progress on induction heads/rigorous interpretability by @ch402, @catherineols, @nelhage and others @AnthropicAI. More to come! https://t.co/CJXjQlKbeo
quantamagazine.org
Language processing programs are notoriously hard to interpret, but smaller versions can provide important insights into how they work.
0
11
75
We've trained a natural language assistant to be more helpful and harmless by using reinforcement learning with human feedback (RLHF). https://t.co/1lwcEASXvA

3
51
268
On the @FLIxrisk podcast, we discuss AI research, AI safety, and what it was like starting Anthropic during COVID.

futureoflife.org
Daniela and Dario Amodei join the FLI Podcast to discuss Anthropic, a new company building safe, reliable, interpretable, and steerable AI systems.
3
9
48
In our second interpretability paper, we revisit “induction heads”. In 2+ layer transformers these pattern-completion heads form exactly when in-context learning abruptly improves. Are they responsible for most in-context learning in large transformers? https://t.co/28WWkMrjQm
1
57
307
Our first societal impacts paper explores the technical traits of large generative models and the motivations and challenges people face in building and deploying them:
arxiv.org
Large-scale pre-training has recently emerged as a technique for creating capable, general purpose, generative models such as GPT-3, Megatron-Turing NLG, Gopher, and many others. In this paper, we...
2
33
148
Our first interpretability paper explores a mathematical framework for trying to reverse engineer transformer language models: A Mathematical Framework for Transformer Circuits:
3
115
610
Our first AI alignment paper, focused on simple baselines and investigations: A General Language Assistant as a Laboratory for Alignment

arxiv.org
Given the broad capabilities of large language models, it should be possible to work towards a general-purpose, text-based assistant that is aligned with human values, meaning that it is helpful,...
5
60
323
We’re going to be focused on pushing forward our research for the next few months and are hoping to have more to share later this year. Thrilled to be working with so many talented colleagues!
6
1
26
Excited to announce what we’ve been working on this year - @AnthropicAI, an AI safety and research company. If you’d like to help us combine safety research with scaling ML models while thinking about societal impacts, check out our careers page
11
26
197