
Ben Shi
@BenShi34
Followers
314
Following
504
Media
19
Statuses
97
Human centered NLP | SF 🌉 | prev @princeton_NLP @meta
New Jersey, USA
Joined April 2024
As we optimize model reasoning over verifiable objectives, how does this affect human understanding of said reasoning to achieve superior collaborative outcomes? In our new preprint, we investigate human-centric model reasoning for knowledge transfer 🧵:
6
42
184

This is not reward hacking. The policy in tau-airline has this by design and one of the tasks even makes use of it. We've actually observed some other models try this strategy at times before, but decided to keep the task and policy as is since upgrading flights is not something

We had to remove the τ2-bench airline eval from our benchmarks table because Opus 4.5 broke it by being too clever. The benchmark simulates an airline customer service agent. In one test case, a distressed customer calls in wanting to change their flight, but they have a basic
3
2
133

SWE-bench verified results make it seem like we are close to achieving human parity on coding, but users of coding agents know that that's not where we are yet. The solution is to build benchmarks that challenge LMs on even tougher tasks. SWE-fficiency, SciCode & AlgoTune make

We measure agents using Speedup Ratio (SR), encouraging long-term benchmark progress! SR = (agent speedup) / (expert speedup) SR = 1× → expert parity SR > 1× → above-expert optimization! But agents fall short, struggling to match expert performance or maintain correctness!
2
11
83

New eval! Code duels for LMs ⚔️ Current evals test LMs on *tasks*: "fix this bug," "write a test" But we code to achieve *goals*: maximize revenue, cut costs, win users Meet CodeClash: LMs compete via their codebases across multi-round tournaments to achieve high-level goals
28
92
374

How to build agentic search systems for long-horizon tasks? Check out our new paper! - Simple design principles are efficient and effective - Error analysis and fine-grain analysis for search systems A 🧵 on SLIM, our long-horizon agentic search framework
1
14
41

📣New paper: Rigorous AI agent evaluation is much harder than it seems. For the last year, we have been working on infrastructure for fair agent evaluations on challenging benchmarks. Today, we release a paper that condenses our insights from 20,000+ agent rollouts on 9
20
100
425

What if scaling the context windows of frontier LLMs is much easier than it sounds? We’re excited to share our work on Recursive Language Models (RLMs). A new inference strategy where LLMs can decompose and recursively interact with input prompts of seemingly unbounded length,
126
356
3K

Can LLMs reason like a student? 👩🏻🎓📚✏️ For educational tools like AI tutors, modeling how students make mistakes is crucial. But current LLMs are much worse at simulating student errors ❌ than performing correct ✅ reasoning. We try to fix that with our method MISTAKE 🤭👇
11
55
337

Check out 𝜏-Bench's new leaderboard. High-level metrics are great but they're more valuable when third parties can inspect how the results were achieved. Leaderboard makes evaluations more transparent, interactive, and community-driven.
3
2
10
One of my fave papers from COLM by @BenShi34! Really cool eval too (a friends and family Turing test!)

IMPersona from @BenShi34 et al #COLM2025 They trained LMs on participants' real chat logs. Then they brought in *each participant's friend* to do a personalized Turing test. The chatbot was surprisingly effective, passing as the friend 44% of the time. LMs can impersonate YOU🫵
1
3
33
Thinking a lot about user simulation lately. IMPersona offers a testbed for high-fidelity sims: if an LLM is output-wise indistinguishable from a specific person, it should approximate that person’s policy across environments. Check out IMPersona @COLM_conf Wed AM, poster #1!
Can language models effectively impersonate you to family and friends? We find that they can: 44% of the time, close friends and family mis-identify Llama-3.1-8b as human… 🧵👇
0
1
10

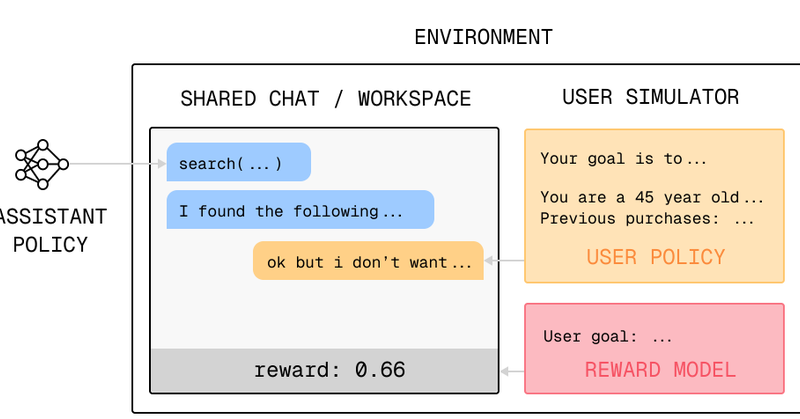
What does it take to build a human-like user simulator? // To train collaborative agents, we need better user sims. In blog post pt 2, @NickATomlin and I sketch a framework for building user simulators + open questions for research: https://t.co/FD0dRt22lR
jessylin.com
3
11
59

Is online alignment the only path to go despite being slow and computationally expensive? Inspired by prospect theory, we provide a human-centric explanation for why online alignment (e.g. GRPO) outperforms offline alignment (e.g. DPO, KTO) and empirically show how to close the
4
35
176
Accepted to #NeurIPS2025! Big shoutout to our ~120 participants, who graciously allowed me to pester them daily with reminder emails, bug fixes, and troubleshooting queries 😓
As we optimize model reasoning over verifiable objectives, how does this affect human understanding of said reasoning to achieve superior collaborative outcomes? In our new preprint, we investigate human-centric model reasoning for knowledge transfer 🧵:
0
1
14

IMPersona is accepted at #COLM2025 + recommended for oral! Check out our work on imbuing human personality and memories into LLMs, allowing them to evade detection even by close friends and family. @COLM_conf
Can language models effectively impersonate you to family and friends? We find that they can: 44% of the time, close friends and family mis-identify Llama-3.1-8b as human… 🧵👇
0
0
6

Do language models have algorithmic creativity? To find out, we built AlgoTune, a benchmark challenging agents to optimize 100+ algorithms like gzip compression, AES encryption and PCA. Frontier models struggle, finding only surface-level wins. Lots of headroom here!🧵⬇️
6
63
159
This and lots more insights (like a trajectory visualizer) at https://t.co/0vklaV6pgt. Thanks to Carlos, Diyi, Nick, Shunyu, and Karthik for helping make this happen! I’ve wanted to do this project for an entire year and it’s so rewarding finally seeing it come to fruition :)
kite-live.vercel.app
Research on mechanisms and dynamics of knowledge transfer in human-AI collaborative settings.
0
0
7
As we build more powerful AI, we need to be equally intentional about building AI that can effectively teach and collaborate with humans: otherwise we risk creating a world of powerful but incomprehensible AI assistants.
1
0
5
By clustering embeddings of user queries, feedback, and model responses, we see a nuanced picture of the interaction types that drive effective/non-effective knowledge transfer in collaboration.
1
0
3