

Aditya Yedetore
@AdityaYedetore
Followers
126
Following
60
Media
10
Statuses
24
Graduate Student at Boston University in the Linguistics Department. Studying language acqusition, syntax, and semantics
Joined September 2015
RT @yulu_qin: Does vision training change how language is represented and used in meaningful ways?🤔 The answer is a nuanced yes! Comparing….
0
23
0
RT @najoungkim: Here's work where we try to take analogies quite seriously, plus our takes about LLM experiments serving to raise the bar f….
0
5
0

I will be at #EMNLP2024 with some awesome tinlab people. Contact me if you would like to chat (esp. about 1. the similarities and differences between Connectionist/neural and Classical/symbolic computation, and 2. what compositionality, productivity, and systematicity are).

tinlab will be at #EMNLP2024! A few highlights:. * Presentations from @AdityaYedetore and @HayleyRossLing on neural network generalizations!.* I'm giving a keynote at @GenBench & organizing @BlackboxNLP .* Ask me about our faculty hiring & PhD/postdoc positions!. Details👇🧵.
0
1
6
RT @najoungkim: tinlab at Boston University (with a new logo! 🪄) is recruiting PhD students for F25 and/or a postdoc! Our interests include….
0
21
0
These results suggest that statistical learners can use semantic training signals to achieve hierarchical generalization. Here is a link to the preprint!
0
0
5
We also find that grokking of hierarchical generalization from form alone depends on the presence of agreement in the training data (sheding light on the source of hierarchical grokking), while models trained on form and meaning are robust to this.

1
0
4
Why do some Transformers not generalize hierarchically? Maybe we aren't training them long enough! Recent work shows that (form only) models trained for longer generalize better (this is called 'grokking': see . We find that yes, longer training helps!

1
1
7
We find that Transformers trained on mapping form to meaning do show a stronger preference for hierarchical generalization than models trained on form alone.

1
0
2
Caveat: though children do not directly get such logical representations, we take these representations to be a conservative upper bound to what children can recover from context (see our paper for more discussion).

1
0
2
Would learners without a hierarchical bias (e.g., Transformers) generalize hierarchically when trained to map form to meaning?. We take meaning to be logical representations of the sort used by semanticists (linguists who study meaning)

1
0
5
But these works focus training on form alone (words and their order), while children presumably also get signals about the meaning of the sentences they hear that help them map the form onto the corresponding mental representations of meaning.

1
0
2
We found that various neural networks generalize linearly when trained on form alone, unlike children.

1
0
2
Prior (and also my computational work with @RTomMcCoy @tallinzen and @bob_frank !) suggests that hierarchical generalization requires stronger inductive biases than modern neural networks have (e.g., a hierarchical bias).

aclanthology.org
Aditya Yedetore, Tal Linzen, Robert Frank, R. Thomas McCoy. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023.
1
0
4
What is hierarchical gen and why is it an important/interesting problem?. Though kids often don't get direct evidence ruling out linear rules (e.g., for English yes/no questions), they always choose hierarchical rules. This generalization might need an innate hierarchical bias

1
0
4
NEW PAPER! We (@najoungkim and I) find that training on mapping from form to meaning leads to improved hierarchical generalization.
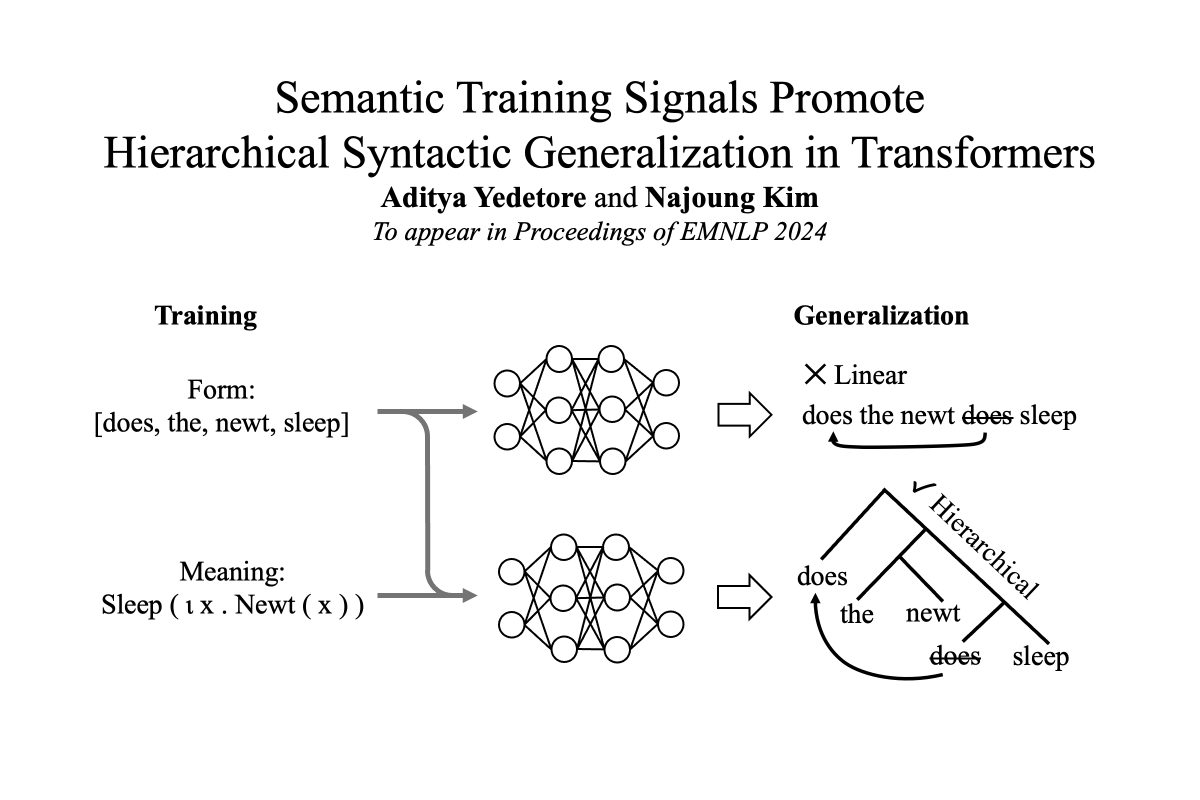
2
20
84
I am helping organize BUCLD this year! Please consider submitting your abstracts and symposium ideas.
2
3
7
I’ll be at the LSA annual meeting this week, and happy to chat! Message me if you would like to.
0
2
7
RT @RTomMcCoy: 🌲Interested in language acquisition and/or neural networks? Check out our poster today at #acl2023nlp! Session 4 posters, 11….
0
5
0
NEW PREPRINT. Excited to release my first first-author paper! We investigate if neural network learners (LSTMs and Transformers) generalize to the hierarchical structure of language when trained on the amount of data children receive. Paper:

2
20
90