
Abdel-rahman Mohamed
@AbdoMohamedML
Followers
244
Following
14
Media
0
Statuses
7
Research Scientist, Speech Processing/Machine Learning/Deep Learning
Seattle, WA
Joined August 2018
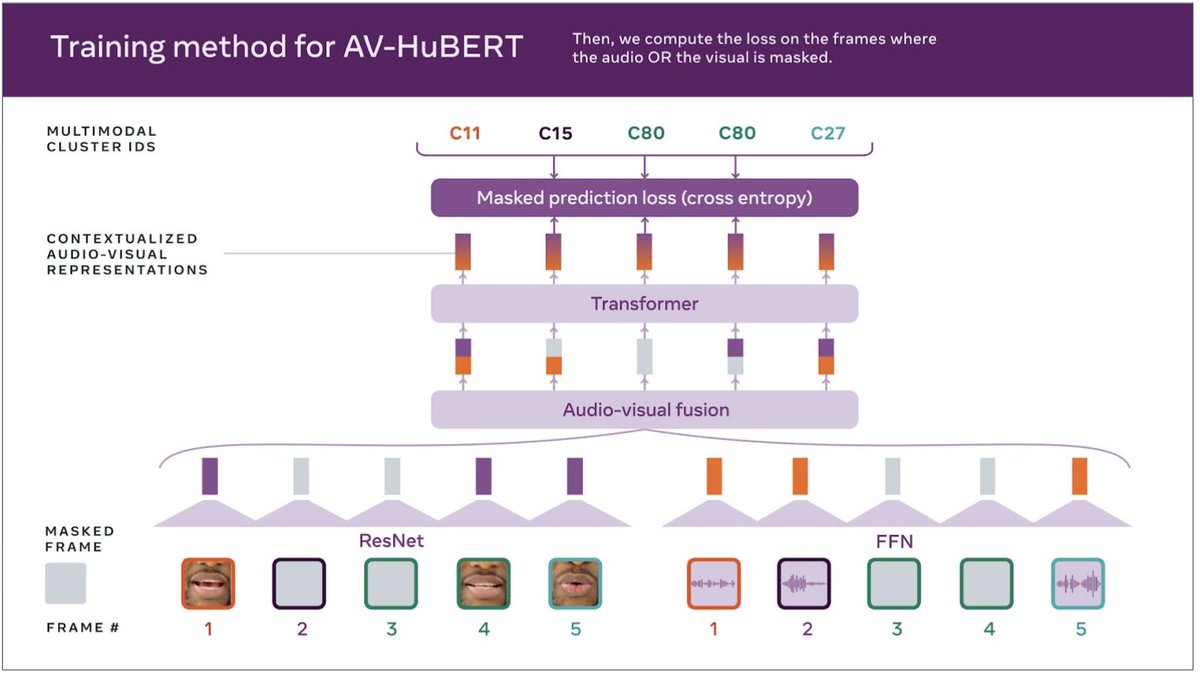
Happy to share our newest model for audio-visual representation learning.

To help build more versatile & robust AI speech recognition tools, we are announcing Audio-Visual HuBERT (AV-HuBERT), a state-of-the-art self-supervised framework for understanding speech that learns by observing & hearing people speak.
0
3
20
RT @AIatMeta: We built universal speech recognition models with 4.5M hours of English speech across 10 sources and 120 countries. The model….
0
98
0
RT @huggingface: Transformers can read and write, but how well can they listen and speak 🗣️?. Find out by pitting your models against the S….
0
83
0
The new SUPERB benchmark for self-supervised speech representations.
In collaboration with @ntu_spml, @LTIatCMU, & @jhuclsp we introduce SUPERB, a benchmark using 10 speech processing tasks to standardize evaluations of #unsupervised models used in speech processing advancements. Submit & evaluate your models here:
0
1
15
Excited to have HuBERT in @huggingface !.

🎙️A new speech model is in town! . HuBERT shows exciting results for downstream audio tasks, including Emotion Classification, Speaker Verification, . You can now try it out it with 🤗Transformers and the 🤗Hub:. 👉
0
1
2
HuBERT representations have impressive performance on ASR, generation, compression, and SUPERB downstream tasks. The code and pre-trained models are now available.
We are releasing pretrained HuBERT speech representation models and code for recognition and generation. By alternating clustering and prediction steps, HuBERT learns to invent discrete tokens representing continuous spoken input. Learn more:

0
0
1