
Chaojun Xiao
@xcjthu1
Followers
242
Following
4
Media
4
Statuses
19
PhD Student @TsinghuaNLP @OpenBMB, LLM
Joined March 2021
We release Ultra-FineWeb, a high-quality pre-training corpus with 1.1 T tokens !!.

🚀 Introducing Ultra-FineWeb 🔥.~1T English and 120B Chinese tokens!.~Training fuel of MiniCPM4!. 🎯 Highlights.~Efficient Verification Strategy: Reduces data verification cost by 90%.~High-Efficiency Filtering Pipeline: Optimizes selection of both positive and negative samples.
0
1
10
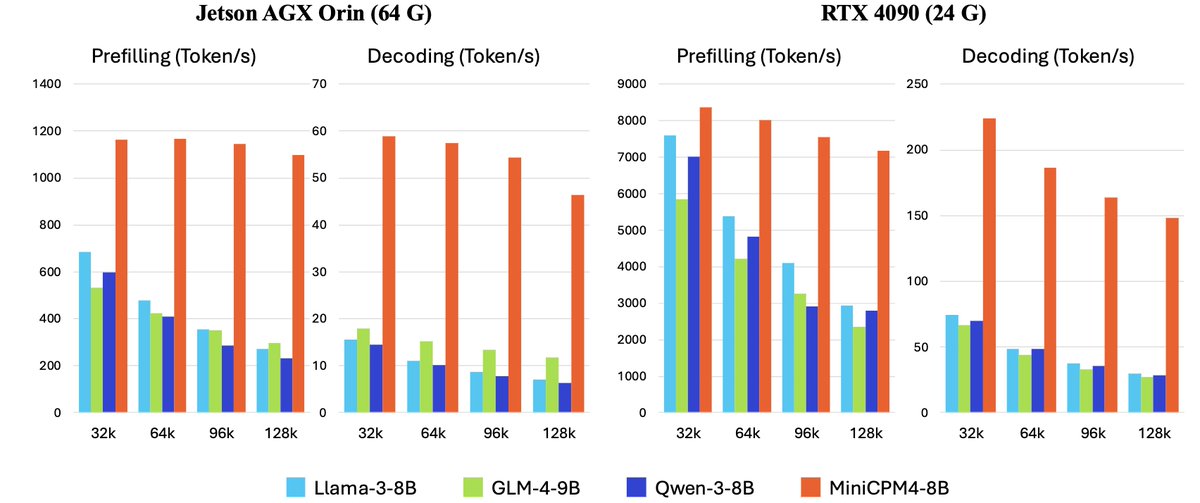
Efficiently scaling the context length !!!!.
🚀 MiniCPM4 is here! 5x faster on end devices 🔥.✨ What's new:.🏗️ Efficient Model Architecture.- InfLLM v2 -- Trainable Sparse Attention Mechanism.🧠 Efficient Learning Algorithms.- Model Wind Tunnel 2.0 -- Efficient Predictable Scaling.- BitCPM -- Ultimate Ternary Quantization

0
0
5
RT @ZhiyuanZeng_: Is a single accuracy number all we can get from model evals?🤔.🚨Does NOT tell where the model fails.🚨Does NOT tell how to….
0
91
0
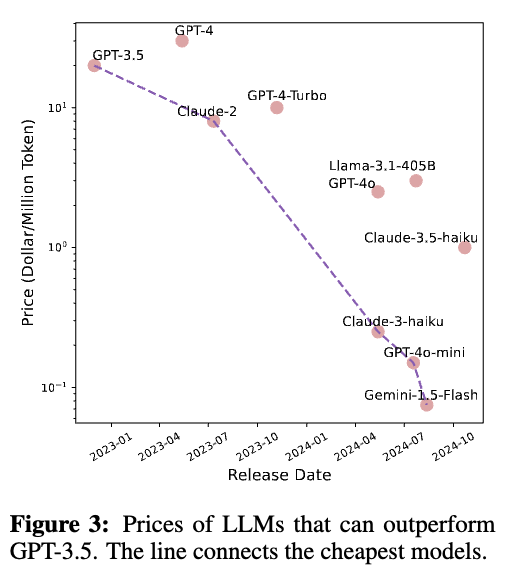
3/4.Key Corollary:.- Inference costs dropping exponentially💰.- Edge AI gaining importance (Moore's Law × Density Law)📱.- ChatGPT accelerated density growth significantly 🚀.- Model compression ≠ Density improvements 🔄.- Each model has a short "optimal cost-effective period"⚡️


1
3
42
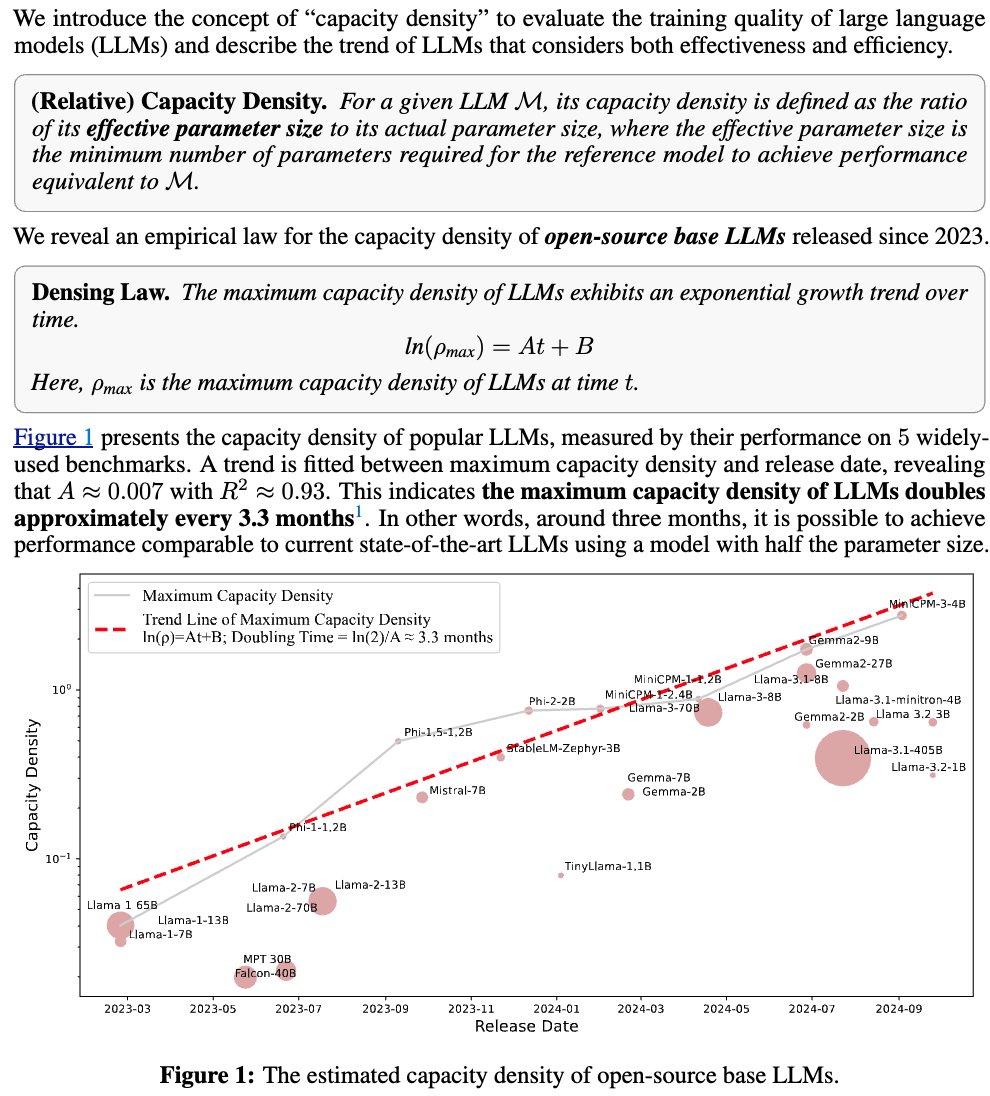
2/4.Based on the evaluation of 5 downstream tasks, capability density DOUBLES every 3.3 months. It indicates that in 3.3 months, we can achieve performance comparable to the current state-of-the-art LLM using a model with only HALF the number of parameters!.
1
6
48
1/4 🚀 Densing Law of LLMs 🚀. OpenAI's Scaling Law showed how model capabilities scale with size. But what about the trend toward efficient models? 🤔. We introduce "capacity density" and found an exciting empirical law: LLMs' capacity density grows EXPONENTIALLY over time!

2
42
317
RT @nlp_rainy_sunny: (Repost) We are thrilled to introduce our new work 🔥#SparsingLaw🔥, a comprehensive study on the quantitative scaling p….
0
4
0
5/5 Our paper aims to offer a fresh perspective on LLM research and inspire more efficient, scalable foundation models. We also discuss open issues and future research directions in this emerging field. Read the full paper:
0
0
1
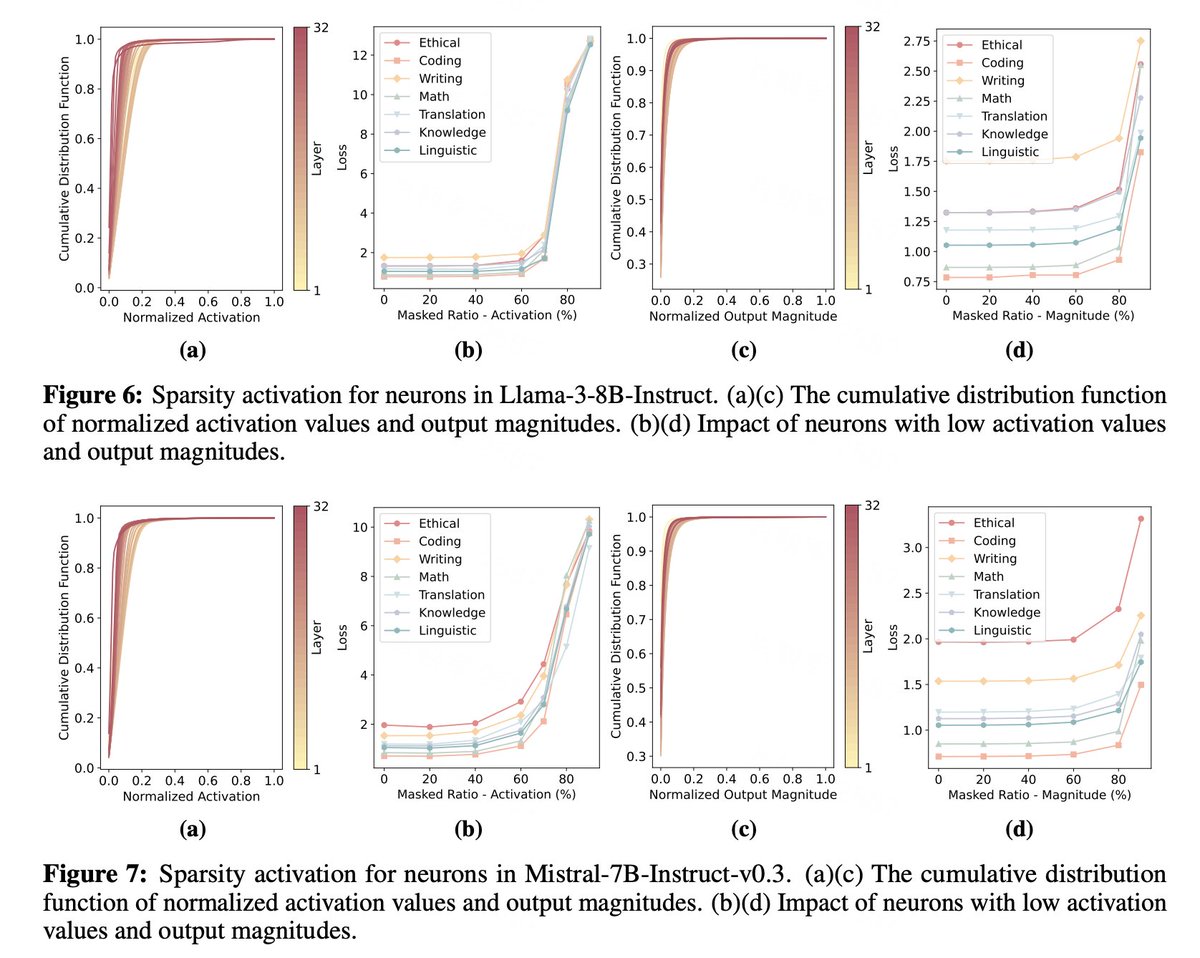
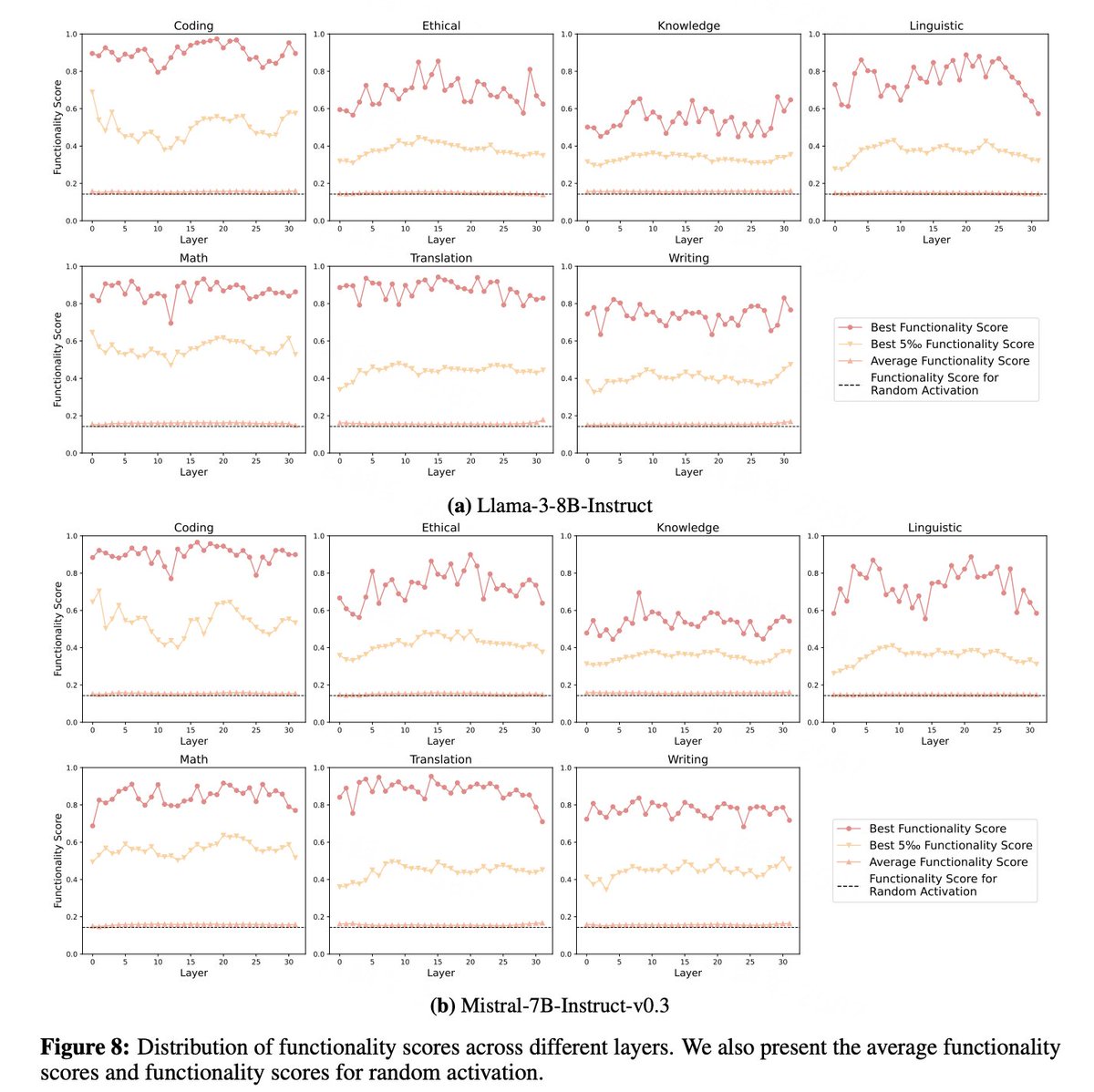
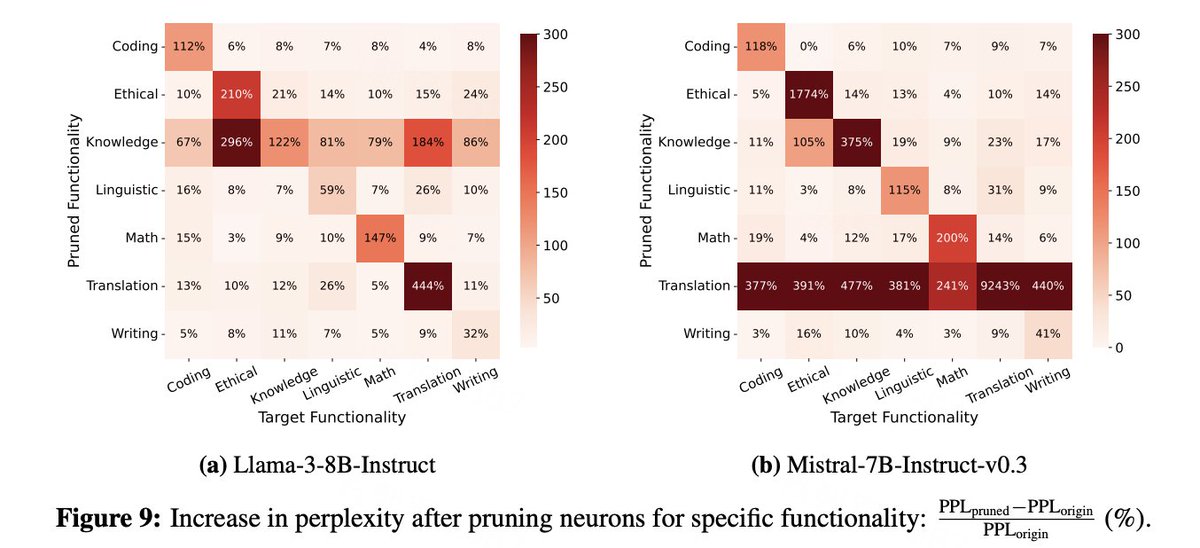
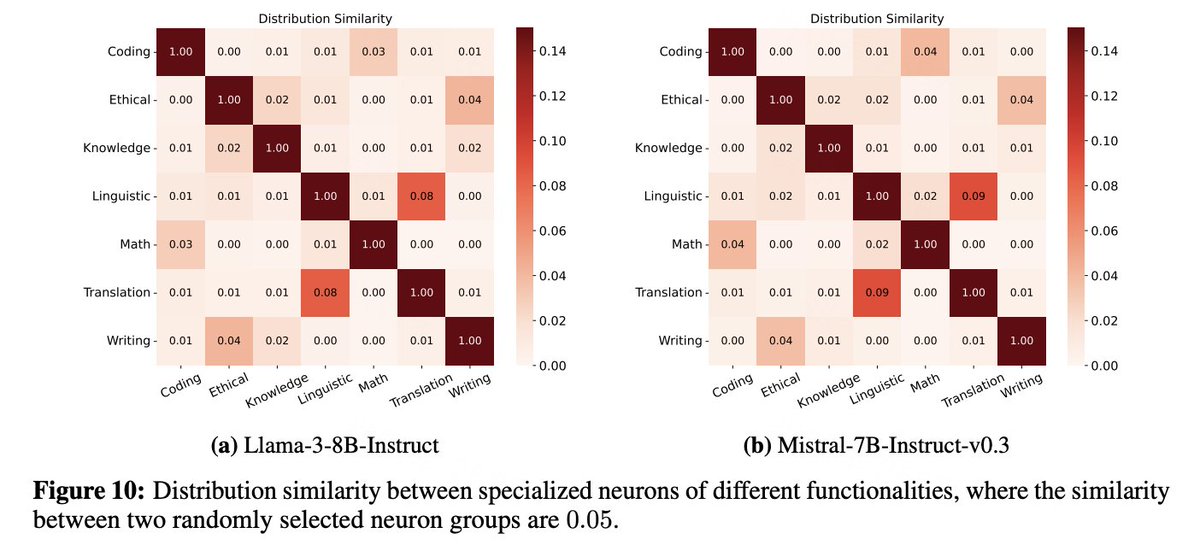
4/5 We conducted empirical analyses on Llama-3-8B-Instruct and Mistral-7B-Instruct-v0.3, revealing:.- Sparse activation patterns.- Functional specialization of neurons.- Functional partitions within the models
0
0
2
3/5 Benefits of our approach:.✅ Efficient inference on resource-limited devices.✅ Dynamic assembly of modules for complex tasks.✅ Scalable capabilities through modular design.✅ Potential for continuous model updates and improvements.
0
0
0
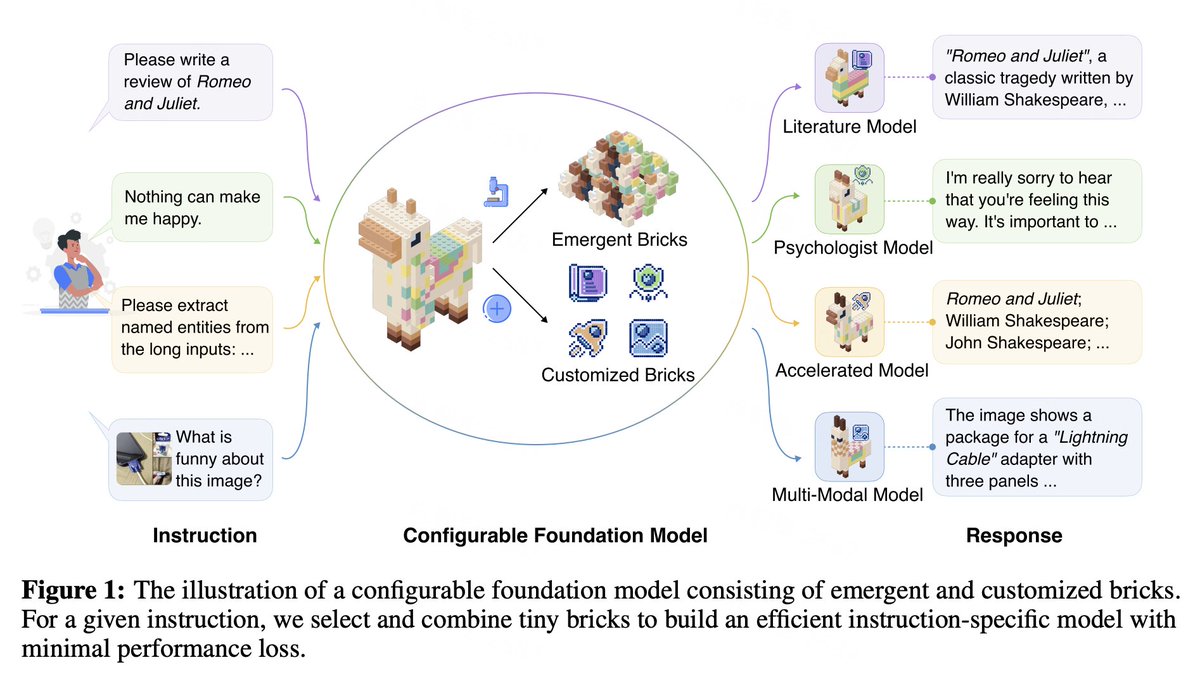
2/5 Key Concepts:.- Emergent bricks: Functional neuron partitions that emerge during pre-training.- Customized bricks: Post-training modules to enhance LLM capabilities.- Brick operations: Retrieval, routing, merging, updating, and growing.
0
0
0
1/5 🚀 Excited to share our latest paper on Configurable Foundation Models! 🧠. Inspired by the human brain's functional specialization, we propose a concept: Configurable Foundation Model, a modular approach to LLMs.

8
24
79
RT @TsinghuaNLP: Pre-trained models show effectiveness in knowledge transfer, potentially alleviating data sparsity problem in recommender….
0
6
0
RT @TsinghuaNLP: Welcome to the @TsinghuaNLP Twitter feed, where we'll share new researches and information from TsinghuaNLP Group. Looking….
0
11
0