

Vincent Abbott
@vtabbott_
Followers
7K
Following
3K
Media
149
Statuses
517
Maker of *those* diagrams for deep learning algorithms | @mit @mitlids incoming PhD
Perth 🔜 Boston
Joined July 2022
Category theory may not be an ur-theory of maths, but robustly thinking about composition (eg deep learning algorithms) without it seems impossible.
0
2
16
Ok figuring out how to model kernels *within* kernels to capture how multiple levels of the memory hierarchy interact. Using "kernel" to mean a category-theory parallelized morphism is shockingly useful for modelling all of this.
0
0
17
In the categorical deep learning package I'm making, composing operations modifies them by aligning axes. Axes are therefore symbols, and the random uids of these symbols are rendered as colors!

1
9
97
Ok I really need to make a post about why the memory access requirements of AB*BC matrix multiplication is not;. AB+BC. But is instead,. ABC(CacheSize)^(-0.5). And how this is actually quite easy to derive.
0
0
17
I derived a category-theoretic notion of a (CUDA) kernel as a parallelised function that works *shockingly* well, turning fusion into a compositional property. The remaining hurdle is figuring out how to deal with streamable/looped operations.



7
26
507
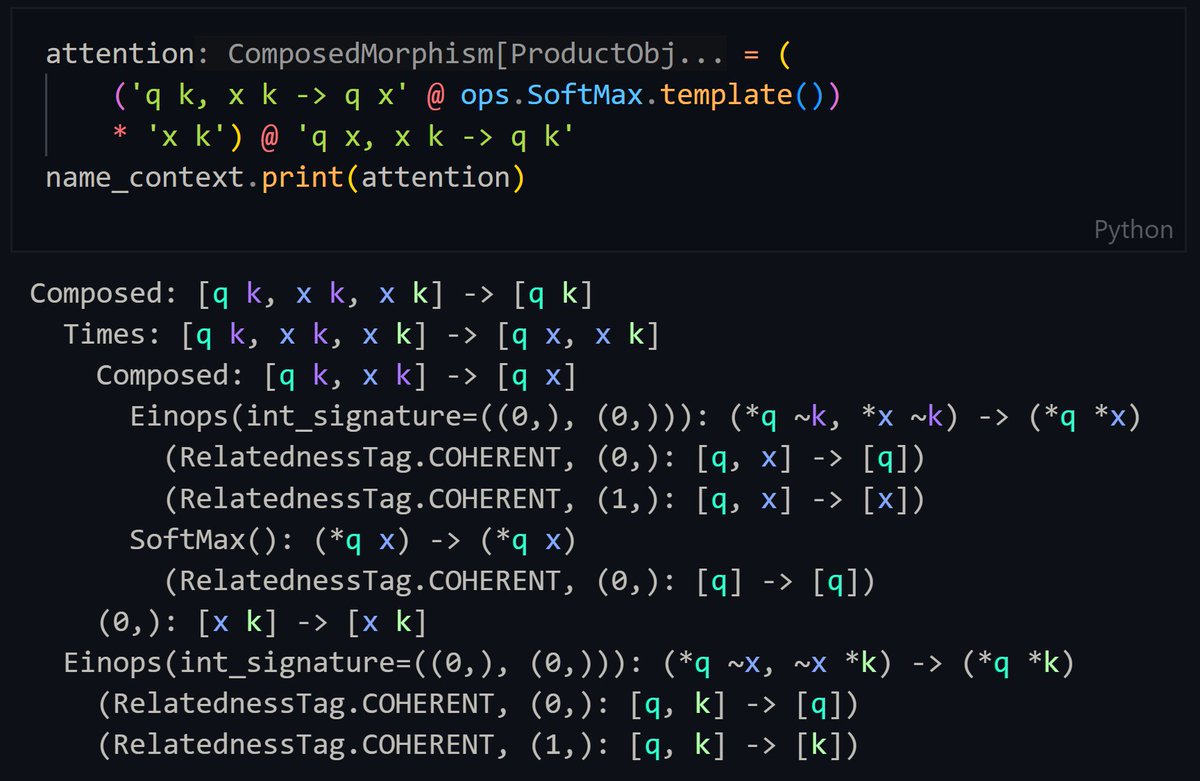
Spent the last week doing a major refactor to better model when fused GPU operations are possible. Another benefit - here's attention in one line!
3
10
173
Just got the automatic derivation of FlashAttention's performance model to work! Algebraic descriptions and generated diagrams now support low-level kernels + derive memory usage and bandwidth requirements. Compiled fusion for general/non-elementwise operations is up next.




4
20
244
Adding multi-level performance models to diagrams. This will allow performance models of FlashAttention / matmul / distributed MoEs to be dynamically calculated. Colors indicate execution at different levels, and the hexagons indicate a partitioned axis.

1
3
77
Algebraic definition of a transformer which automatically generates configurations, diagrams, torch modules and - now - performance models!




5
51
440
Automatically generated diagram of Transformer + Multi-Layer Perceptron. Python code generates a json, which is loaded by TypeScript and rendered. Axes sizes are stored internally and labelled, allowing for safe deep learning code.

3
10
101
RT @vtabbott_: @SzymonOzog_ I'll be refactoring the code to allow for texture packs at some point. This is actually a good resource for sty….
0
1
0
Working on making automatically generated diagrams *aesthetic*. Here is attention, generated from a mathematical definition. Note how there are multiple k and m values, as the code found that these two values can be independently set.

5
21
149
Base Morphism: The function we are parallelising. Mathematically, it's domain/codomain are lifted. Physically, it is executed separately on multiple cores. Prelifts/Postlifts: These define the indexes of how domains/codomains are lifted. Are we extracting rows, columns, or.
1
0
16
This formulation took me a year+ to derive. It explains why and how deep learning models benefit from GPUs, and serves as the basis for a framework-independent representation of models. It's a mathematical formulation of broadcasting—extending an operation over additional axes.

3
10
140
I'm working on symbolically expressed deep learning models. Built on standard definitions, we can provide a web of features from different modules. One module produces a model, another converts it to PyTorch, another exports it to JSON, and another loads to TypeScript and renders




2
28
314
The implementations I'm working on are based on novel algebraic/categorical constructs that can–at last–properly represent broadcasting. This will allow deep learning models to be symbolically expressed, from which Torch implementations, diagrams etc follow. Here's a sneak peak!

1
7
77
Making progress with automatically generating diagrams of deep learning models (here's multi-head attention). Next up, automated performance modelling + conversion from PyTorch to data structure that allows for diagram generation + performance modelling.

3
9
85
The advantage of this approach vs PyTorch is the entire model is symbolically defined with all constituent axes etc. noted. The symbolic definition is agnostic to the choice of platform, and a compiler can be made for JAX, CUDA etc. while using the same underlying symbolic.
1
0
11
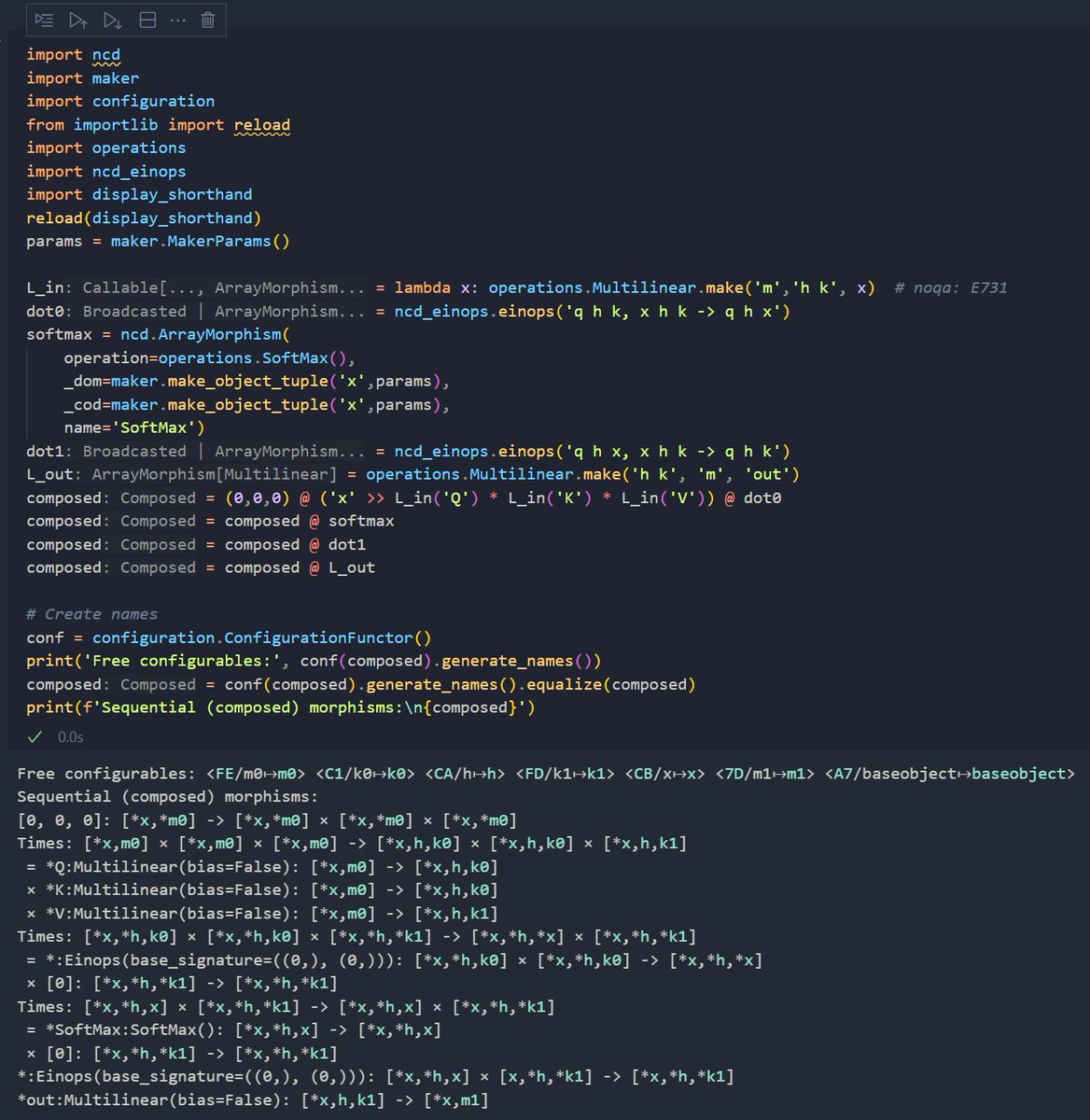
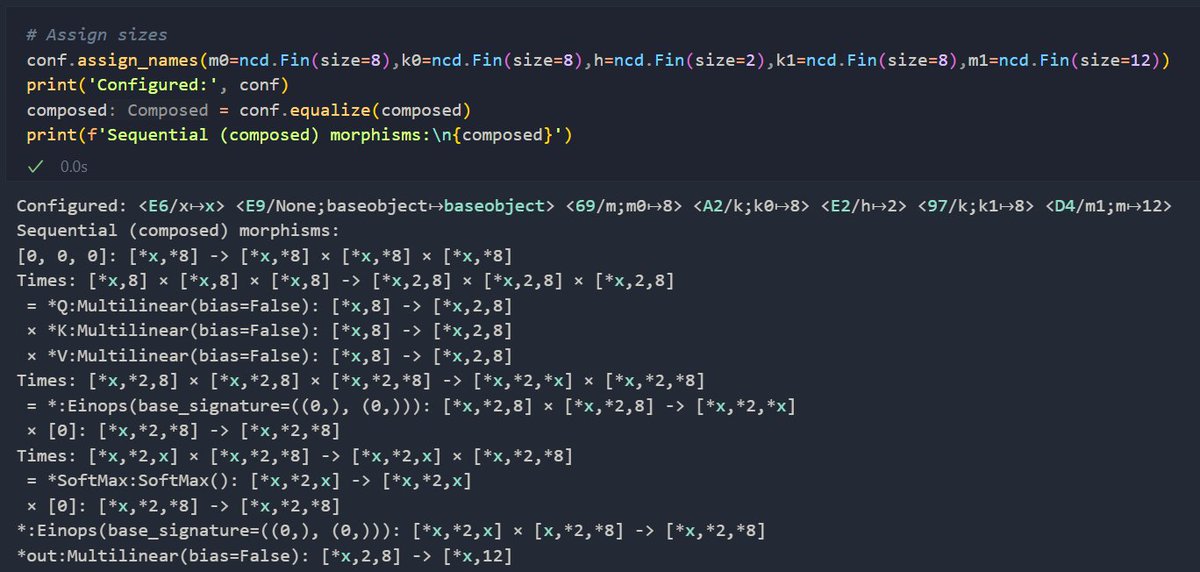
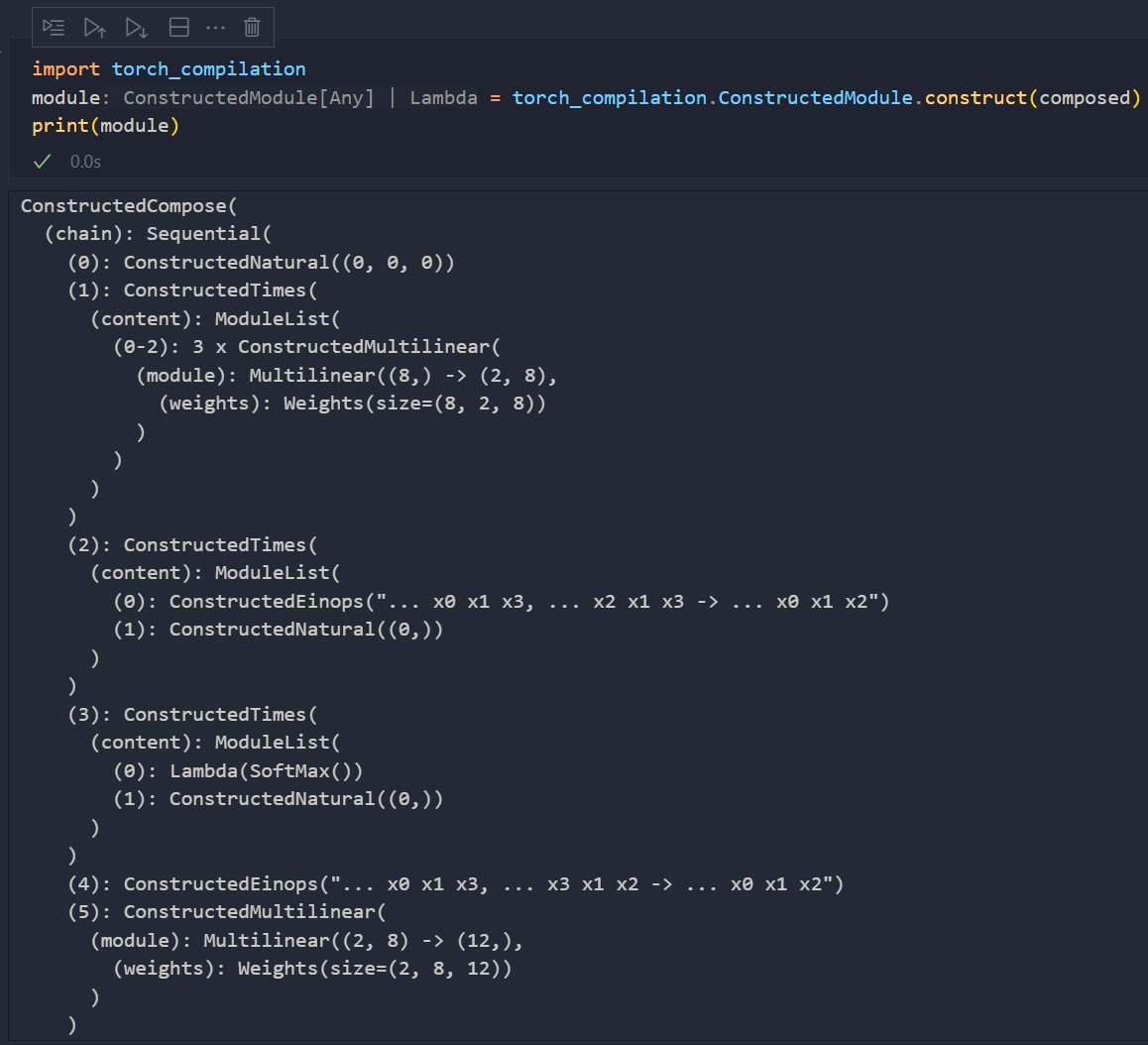
I'm coding up NCDs for automated diagramming, compilation, and performance analysis of deep learning algorithms. Here's a preview of symbolically defining attention, automatically discovering configurable axes + assigning a configuration, and compiling a torch module ~~
3
6
84
Recently posted w/ @GioeleZardini and @sgestalt_jp. Diagrams indicate exponents are attention’s bottleneck. We use the fusion theorems to show any normalizer works for fusion and we replace SoftMax with L2, and implement it thanks to @GerardGlow47445! Even w/o warp shuffling TC.

Vincent Abbott, et al.: Accelerating Machine Learning Systems via Category Theory: App.
2
5
26