
Venkat Raman — inference/acc
@venkat_systems
Followers
347
Following
3K
Media
89
Statuses
1K
distributed systems, low latency, inference, cuda | 🦀 | hobbies: ⛷️ 🏊🏽♂️ 📷
µs, ns, 80% speed-of-light
Joined January 2013
inspired by @uccl_proj n thunderkittens by @HazyResearch 🙏, my attempt at successfully challenging nvidia nccl perf: - starting with single process p2p all_reduce sum on 2xA100. - mpi p2p, h100, b200 n b300 is wip. - will oss soon once apis n abstractions are stable
0
0
2

huggingface tgi & mistral dot rs engines are written in rust. However if we look at intranode tp inference, they use uds. they also use protobuf over pickle. but vllm & sglang (uses same parts of vllm) use cpu shmem the former are leaving so much perf gains on the table for
vllm n sglang cpu-side engine overhead can be ns instead of µs, if written in c++ / rust.. this in turn will improve gpu util 30-60% gain in sustained goodput / tco based on my local experiments but it comes at a cost of research to production speed n researcher friendly
0
0
1
i might be late to this.... in last 15 years, there are different generations of support, lead gen, crm, marketing, sales tools... let's say 2-3 players per market segment and per geo region still there are so many startups in this space... in ai era, this is on speeed feels
2
0
0
is anyone from openai still using codex cli internally ? i miss using it.. i want to, but every time it just shits the bed 😭😭
0
0
0
@thorstenball i was thinking along these lines too talk is cheap -> code is cheap is so surreal.. enabled by VC & labs subsidizing vibe coding all the oss agent frameworks are fungible.. infra on the other hand is not basic app layer infra is starting to get fungible too… next 2-3years
0
0
0
aged like wine ! (just a day old though 😜)

Anthropic is acquiring @bunjavascript to further accelerate Claude Code’s growth. We're delighted that Bun—which has dramatically improved the JavaScript and TypeScript developer experience—is joining us to make Claude Code even better. Read more:
1
0
0
vllm n sglang cpu-side engine overhead can be ns instead of µs, if written in c++ / rust.. this in turn will improve gpu util 30-60% gain in sustained goodput / tco based on my local experiments but it comes at a cost of research to production speed n researcher friendly
2
0
3

I agree @claudeai ASCII charts are bangers !

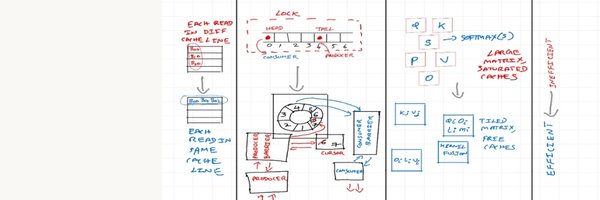
With some Claude-generated ASCII charts, StringZilla now looks quite competitive for: 1. non-cryptographic hashing (vs xxHash, aHash?) 2. exact substring and byte-set search (vs memchr?) 3. UTF-8 tokenization (vs standard libs, regex, ICU?) Will update StringWars benchmark
0
0
2
update: found out that this optimization is not really valid as it doesn’t adhere to challenge spirit.. there is a benchmarking bug… reverted it with @m_sirovatka ‘s help @GPU_MODE discord is amazing 🙏🏽 wish i started there sooner than just their youtube channel
finally cursor <> gemini 3 pro worked for me... helped to beat my personal best 55 µs --> 24.4 µs gpu mode's Blackwell NVFP4 Kernel Hackathon finally in top 12 now 😅🎉
0
0
3
gemini 3 pro is also suffering from infinite loops similar to 2.5 pro
0
0
1
CUDA moat also comes from well designed abstractions and APIs that are backwards compatible.. let's take NCCL for example.. it supports different execution mode, topologies, diverse hw interconnects (nvlink, pcie, etc.,) one can get started quickly and take things to
@zephyr_z9 CUDA moat is same as python moat.. ecosystem n researchers n gpu engineers love it.. actual programmability.. nvidia provides low level apis so that u can write better n more performant versions of their high order frameworks.. i agree with u automated, manual or ai assisted
0
0
0
finally cursor <> gemini 3 pro worked for me... helped to beat my personal best 55 µs --> 24.4 µs gpu mode's Blackwell NVFP4 Kernel Hackathon finally in top 12 now 😅🎉
5 hours with cursor <> 4.5 opus Kernel #1 - NVFP4 Batched GEMV beat my personal best 106 µs --> 55 µs gpu mode's Blackwell NVFP4 Kernel Hackathon
0
0
0
HFT, system software, gpu kernels dev will teach you that 10µs is actually really long time https://t.co/fSZikc6218

Database System development will make you realise that 1 millisecond is actually a really really really long time ~300 tx/ms TigerBeetle vs 1 tx/ms PostgreSQL https://t.co/m4WbFfEPzO
0
0
1
5 hours with cursor <> 4.5 opus Kernel #1 - NVFP4 Batched GEMV beat my personal best 106 µs --> 55 µs gpu mode's Blackwell NVFP4 Kernel Hackathon
0
0
1
gemini-3-pro is cool, but it is unusable in cursor, i'm already on cli waitlist any better way to use it productively ? i guess google is still scaling up infra for this model
0
0
0