
Tung Nguyen
@tungnd_13
Followers
2K
Following
16K
Media
79
Statuses
387
Ph.D. Candidate @UCLA. AI for Science. Student Researcher @GoogleDeepMind and Research Intern @MSFTResearch @NVIDIAAI.
Los Angeles, CA
Joined April 2020
Introducing ClimaX, the first foundation model for weather and climate. A fast and accurate one-stop AI solution for a range of atmospheric science tasks. Paper: https://t.co/9j10Xlvqzv Blog: https://t.co/D00VPds5hE Thread🧵 #ML #Climate #Weather #FoundationModel

35
173
844
Glad to have contributed a small part to this great research led by @XingyouSong :)

Our new regression language model approach enables LLMs to predict industrial system performance directly from raw text data. Learn how we applied it to Borg, Google’s large-scale compute infrastructure for cluster management, & copy the code. → https://t.co/azoyoVlTPP
0
0
18
Right before #imo2025, together with colleagues from Mountain View, NYC, Singapore, etc, we all gathered at @GoogleDeepMind headquarter in London for our final push for IMO. I believe that week was when all magic happened! We put all individual recipes (that we figured out


Very excited to share that an advanced version of Gemini Deep Think is the first to have achieved gold-medal level in the International Mathematical Olympiad! 🏆, solving five out of six problems perfectly, as verified by the IMO organizers! It’s been a wild run to lead this

24
40
553
(6/6) 📰 Please check out our paper for additional experiments, ablation studies, and discussions. We published the code and will release the checkpoints soon! Paper: https://t.co/0L94scWvau Code: https://t.co/O0Q9Tx8X41 Work done with my amazing co-first authors and advisor

github.com
Contribute to ArshKA/PhysiX development by creating an account on GitHub.
2
7
74
(5/6) 👀 See It in Action PhysiX generates high-fidelity rollouts that stay accurate over time. While other models blur or drift, PhysiX retains sharpness, physical realism, and temporal consistency—even far into the future.
1
3
33
(4/6) 🏆 The Results? Long-Horizon Accuracy PhysiX doesn't just predict the next frame well; its strength is in long-term rollouts. On shear flow, it reduces error by over 97% compared to the best baseline. Across eight diverse tasks from The Well benchmark, it consistently

1
2
25
(3/6) ⚙️How PhysiX Works: A 3-Step Pipeline 1️⃣ Universal Tokenizer: Encodes any physical field (fluids, solids, etc.) into discrete tokens, like words. 2️⃣ Autoregressive Transformer: Predicts the "next token" to simulate system evolution in space and time. 3️⃣ Refinement Module:

1
2
35
(2/6) 🧪 The Data Bottleneck in Physics Foundation models thrive on massive datasets. However, while there are billions of natural images and videos, even the largest physics simulation datasets have only tens of thousands of examples. PhysiX overcomes this by 1) transferring
1
2
30
🚀 Introducing PhysiX: One of the first large-scale foundation models for physics simulations! PhysiX is a 4.5B parameter model that unifies a wide range of physical systems, from fluid dynamics to reaction-diffusion, outperforming specialized, state-of-the-art models.
22
255
2K

Seeing text-to-text regression work for Google’s massive compute cluster (billion $$ problem!) was the final result to convince us we can reward model literally any world feedback. Paper: https://t.co/ojqkfrrDi5 Code: https://t.co/xpNRTxEUjF Just train a simple encoder-decoder

14
77
519

(1/6)Our work Reflect-DiT was accepted to #ICCV2025 ! Reflect-DiT allows the model to reflect on its past generations and textual feedback to self-correct and improve, extending reasoning to text-to-image generation.
1
23
96

Since our launch earlier this year, we are thrilled to witness the growing community around dLLMs. The Mercury tech report from @InceptionAILabs is now on @arxiv with more extensive evaluations: https://t.co/DnDxFvoX0E New model updates dropping later this week!

arxiv.org
We present Mercury, a new generation of commercial-scale large language models (LLMs) based on diffusion. These models are parameterized via the Transformer architecture and trained to predict...
3
41
255
CVPR-bound! ✈️ I'll be presenting CoLLM on Friday, 6/13 (Morning, #364) and looking for my next challenge as a full-time Scientist/Engineer. If you're hiring or just want to chat about exciting research, find me there! My work: https://t.co/0aMjTwpRSr
#CVPR2025 #JobHunt

🌟 CoLLM: A Large Language Model for Composed Image Retrieval (CVPR 2025) ✨A cutting-edge training paradigm using image-caption pairs 📊High-quality synthetic triplets for training & benchmarking 🔗Project: https://t.co/CbAa3rF9D5 📄Paper: https://t.co/iSLvGU4yHY
#LLM #CIR

1
6
22

🎉 Our paper “Representations Shape Weak-to-Strong Generalization” is accepted at #ICML2025! We study weak-to-strong generalization (W2SG)—a core problem in superalignment—and offer new insights into the role of models' internal representations in W2SG. 1/

1
8
26

Announcing the 2025 IJCAI Computers and Thought Award winner ✨Aditya Grover @adityagrover_, @InceptionAILabs @UCLA. Dr. Grover is honored for uniting deep generative models, representation learning & RL to advance scientific reasoning. Congratulations! https://t.co/Z3xESFizpi

3
13
72

I am excited to share my new paper "Streaming Sliced Optimal Transport". I introduce the first algorithm for computing sliced Wasserstein distance from sample streams to make sliced optimal transport even faster and more scalable. (1/10)
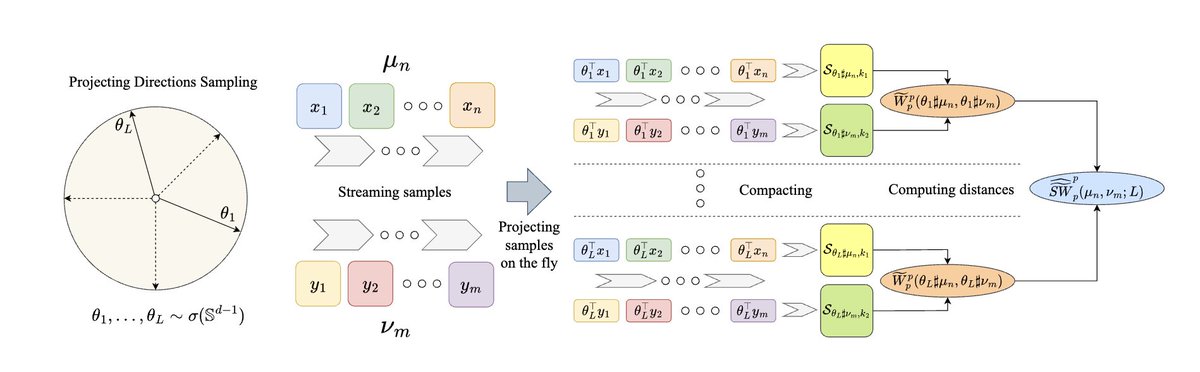
1
3
25
📢(1/11)Diffusion LMs are fast and controllable at inference time! But why restrict such benefits for processing text data? We are excited to announce LaViDa, one of the first and fastest large diffusion LM for vision-language understanding!!
3
40
168
Finally, LICO scales favorably with model size: larger backbones consistently yield better performance, making it a promising direction for scaling optimization with LLMs.

1
0
4
We also show that simple language instructions improve the model’s ability to reason in new domains, even when the task is non-linguistic.

1
0
3
Interestingly, we found that the pretrained LLM consistently outperforms a scratch model of the same size. This supports the idea that LLMs can transfer pattern-matching capabilities to entirely new domains.

1
0
3