
Adaline
@tryadaline
Followers
759
Following
294
Media
32
Statuses
99
Iterate, evaluate, deploy, and monitor LLMs.
Playground
Joined January 2024
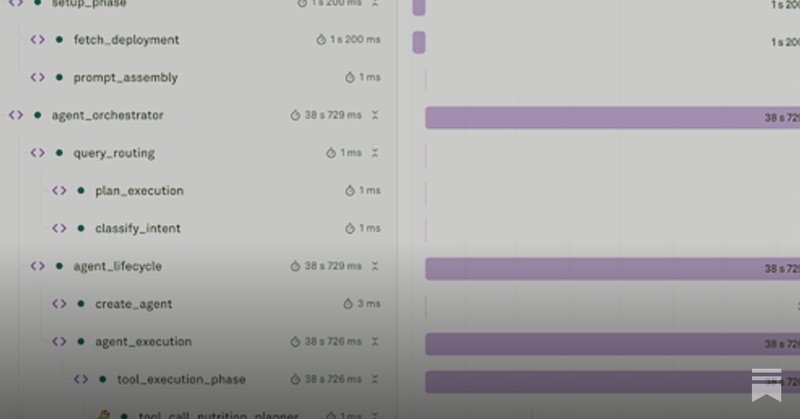
RAG Isn’t One Pipeline. It’s Three Layers of Intelligence. Most RAG failures stem from treating it as a single pipeline. Real systems behave more like operating systems — layered, selective, and adaptive. Layer 1: Orchestration Reads intent. Chooses the path. Retrieval becomes
0
0
1
Read the entire blog here:
labs.adaline.ai
From intent classification to cost optimization: A complete guide to intelligent RAG architecture.
0
0
1
Retrieval Isn’t the Expensive Part. Retrieving Without Thinking Is. Traditional RAG retrieves for every query. That’s the real cost problem; not essentially the embeddings, not vector DBs, not models. The system has no judgment. So it does everything, every time. Agentic RAG
1
0
1
RAG doesn’t fail because vector DBs are weak. It fails because it thinks too little. Most RAG systems run on autopilot: query, embed, retrieve, dump, and pray. That’s not intelligence. That’s machinery pretending to be smart. The real cost isn’t tokens. It’s the lack of
1
0
1

AI PMs Will Shape The Next Decade. Most PMs think AI is just another feature. It is not. AI changes the physics of building products. An AI PM is not a requirements manager. An AI PM is a systems thinker who designs behavior, not buttons. They align user intent with intelligent
1
0
0

Why Evaluation and Deployment Define Prompt Quality? Most AI failures start with one quiet mistake. A prompt that no one evaluated and a deployment that no one controlled. Teams treat prompts like text. In reality, a prompt is a system. It reacts to messy user input, evolving
1
0
1
6/6: Read the Full Analysis. The future belongs to teams that evaluate agents correctly. The blog explains the crisis and offers a practical framework to build safer, more reliable agent systems. Read the full post on Adaline Labs here:

labs.adaline.ai
Evidence-based evaluation strategies that go beyond traditional AI metrics to ensure safety and reliability at scale.
0
0
0
5/6: Benchmarks That Actually Matter. Use Agent-SafetyBench for risk. GAIA for general capability. SWE-bench and WebArena for grounded tasks. No single benchmark is enough. Multi-method evaluation protects against overestimated performance.
1
0
0
4/6: Break Agents Down Before Testing End-to-End. Test routers, tools, memory, and skills separately. Then run full tasks to validate reasoning chains. Finally, monitor behavior in production. This turns evaluation into a safety system rather than a single score.
1
0
0
3/6: The Four Dimensions That Matter. True evaluation covers capability, safety, consistency, and real-world stability. Agents must plan well, resist misuse, behave predictably, and complete tasks under friction. Missing any dimension leads to silent failures.
1
0
0
2/6: Benchmarks Are Warning Us. Agent-SafetyBench shows no model scoring above 60% on safety risks. OpenAI–Anthropic tests reveal hallucinations in tool-restricted settings. Evidence is clear. Agents need an evaluation built for real environments, not toy prompts.
1
0
0
1/6: Static Metrics Cannot Measure Dynamic Agents. Agents plan, act, and change state. Two runs can take different paths. Accuracy scores cannot capture drift, tool misuse, or unstable reasoning. This is why traditional evaluation collapses for agents.
1
0
0
The AI Agent Evaluation Crisis. AI agents do not fail loudly. They fail quietly in the gaps our metrics ignore. Static tests cannot measure dynamic reasoning or tool use. Let’s explore. 👇🏼
1
0
1

The Quiet Skill That Makes AI Products Actually Work. Let’s ask a simple question. Why do two teams use the same model, same prompts, and same stack, yet only one ships a product users trust? Most teams test for correctness. Great teams test for behavior. That distinction
1
0
1
6/6: The Organism Model Is Here Agentic development turns software into systems that metabolize feedback. The full blog breaks down how this shift works. Read it to see how products start learning on their own. https://t.co/IUDIf1KpwG
0
0
0
5/6: Products Start To Evolve. When planning, coding, testing, and reviewing run in a loop, the system learns. Products improve through feedback rather than releases. Evolution becomes the core unit of progress.
1
0
0