

Ming "Tommy" Tang
@tangming2005
Followers
43K
Following
32K
Media
2K
Statuses
70K
Director of bioinformatics at AstraZeneca. YouTube at chatomics. On my way to helping 1 million people learn bioinformatics. Also talks about leadership.
Boston, MA
Joined December 2011
The guide I wish I had 12 years ago: a step-by-step guide to replicate a genomics paper figure
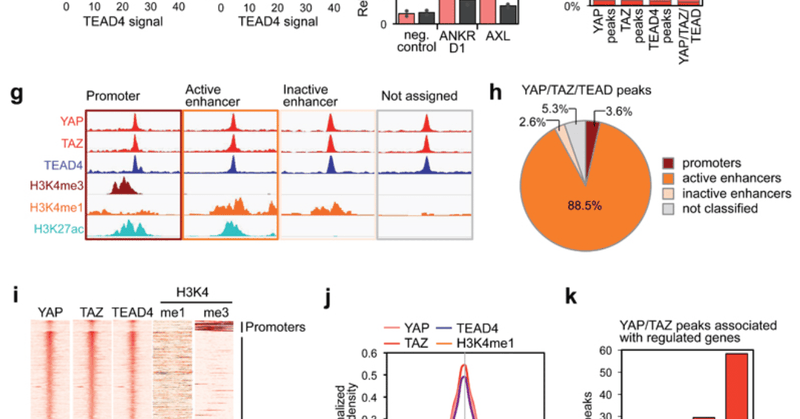
divingintogeneticsandgenomics.kit.com
9
88
573

Important findings from @MSKCancerCenter in @BloodPortfolio on progression rates in contemporary smoldering myeloma (~80% had baseline whole-body MRI or PET/CT imaging) Key findings that impact clinical practice: ✅Annual progression risk to CRAB is now ~5% (first 5 years), down
3
22
43
Enjoy this tweet? follow me @tangming2005 and join my newsletter to learn computational biology
0
0
1

Enzyme Engineering Database (EnzEngDB): a platform for sharing and interpreting sequence–function relationships across protein engineering campaigns 1. EnzEngDB is a new database designed specifically for enzyme engineering, offering a centralized repository for researchers to
0
13
60

Vir2vec: A Genome-Wide Viral Embedding https://t.co/yz3nTLH3m2
#biorxiv_bioinfo

biorxiv.org
Genomic language models (gLMs) have recently emerged as powerful numerical surrogates for DNA, but existing architectures are largely focused on human DNA or trained on limited viral references, and...
0
4
10
Life breaks sometimes. Pots fall. Kids get sick. What matters is how we respond. With patience. With love. With another pot. #lifelesson
0
0
3
This morning, cooking for my sick son, I finally get it. I'm not just making porridge. I'm passing something forward. The care my mom showed me when I was trying my best and failing? That's what I want my kids to feel from me.
1
0
1
She didn't yell. Didn't blame me. Just asked me to clean it up and cook another pot. That moment taught me something I'm only now understanding as a parent: Grace under pressure. Calm when things break. Teaching through gentleness, not punishment.
1
0
1
So I became the breakfast cook. White rice porridge every morning. A bowl for everyone, plus some buns. One day, I dropped the entire pot. Porridge everywhere. Floor covered. I ran to my mom's room, terrified, and told her what happened.
1
0
1
Stirring that pot, I'm suddenly 9 years old again. My mom had tuberculosis. Bedridden for months. We had medicine 30 years ago, but TB needed something else—rest and nutrition.
1
0
1
ChatGPT suggested ORS and white rice porridge once he could keep things down. This morning, I'm in the kitchen. One cup of white rice, extra water, low heat. Cooking it slow until it's soft and gentle on his stomach.
1
0
1
My son came home from school with Norovirus. Puking. Miserable. My wife and I anxious, trying everything to help him feel better.
3
0
2
Scikit-bio: a fundamental Python library for biological omic data analysis https://t.co/zRqpOMzXtR
1
22
91
Assessment of computational methods in predicting TCR–epitope binding recognition https://t.co/46lyJu61cr
1
6
39
Assessment of computational methods in predicting TCR–epitope binding recognition https://t.co/46lyJu61cr
1
6
39
Cheatsheet for purrr. Never repeat yourself again! #rstats If you are still using for loop, take a look at purrr::map() https://t.co/VDhr31fIFb
https://t.co/eXENp2vwoU
0
7
51
I hope you've found this post helpful. Follow me for more. Subscribe to my FREE newsletter chatomics to learn bioinformatics

divingintogeneticsandgenomics.kit.com
Why Subscribe?✅ Curated by Tommy Tang, a Director of Bioinformatics with 100K+ followers across LinkedIn, X, and YouTube✅ No fluff—just deep insights and working code examples✅ Trusted by grad...
1/ I’ve reviewed hundreds of bioinformatics GitHub repos in my career. Here’s the brutal truth: most tool documentation fails the people it’s meant to help. And it’s not because the algorithms are bad.
0
0
0
10/ Your code may be brilliant. But if users can’t figure out what to run, on what data, and what they’ll get… It might as well not exist.
1
0
0
9/ Key takeaways: Write for users, not peers Include example data Be explicit about I/O Test with beginners Focus on solving problems, not flexing algorithms
1
0
0
8/ The best devs I’ve met treat docs as part of the product — not an afterthought. Because poor docs make great code invisible.
1
0
0
7/ Before release, do the silent observer test: Ask a colleague who’s never seen your tool to run it. Say nothing. Every pause, every “wait, what?” = a documentation gap you must fix.
1
0
1