

Leo Boytsov
@srchvrs
Followers
9K
Following
31K
Media
231
Statuses
25K
Machine learning scientist and engineer speaking πtorch & C++. Past @LTIatCMU, @awscloud. Opinions sampled from MY OWN 100T param LM.
Pittsburgh, PA
Joined November 2009
🧵📢Attention folks working on LONG-document ranking & retrieval! We found evidence of a PROFOUND issue in existing long-document collections, most importantly MS MARCO Documents. It can potentially affect all papers comparing different architectures for long document ranking.⏩.
4
14
131
Pretraining has apparently hit the wall, but OpenAI researchers still believe in RL. This sure makes sense: learning from doing is a much more powerful paradigm.

GPT-5 is good. But model performance gains are still slower than in past years and this year has been a technically challenging one for OpenAI researchers. The inside story here.

0
0
3
A new formulation of the survivor bias paradox by @jerepick .

linkedin.com
Two years ago I asked GPT the question: "a plane crashes in the andes. where do they bury the survivors?" It answered that the survivors would be buried either near the crash site, or in a local town...
0
0
1
RT @lmthang: It’s my great honor to have just received the test-of-time award at #ACL2025 from @aclmeeting for our paper “Effective Approac….
0
21
0
Statistically speaking, chances of a life-changing experience (aka you won't need to work for money anymore) are very small (could be well under 1%), but you won't be able to finish your degree, which may change your life in more profound ways. 🟦.
0
0
5
🧵This! Same is true for PhD programs. If you lose interest in doing research & publishing papers, or you feel it's not your path otherwise, it's sure fine to drop out of a program, but I don't think it's worth doing just to join a startup. ↩️.

Don't drop out of college to start or work for a startup. There will be other (and probably better) startup opportunities, but you can't get your college years back.
1
0
10
It is a spot-on observation that the nature of search optimization is changing. However, in my view, an LLM is not a new user in the sense of being the ultimate consumer of information. Rather, it is a user in terms of the target optimization metric. Search now needs to support.

1
0
7

RT @thomasahle: What do we know about the new DeepMind and OpenAI methods for RL on hard reasoning?. - Google say they used a new RL method….
0
2
0
A very inspiring result. Congratulations everyone involved!.

First official Gold medal at IMO from DeepMind🥇 with Gemini Deep Think. A general purpose text-in text-out model achieving gold medal is something quite unthinkable just about one year ago and here we are! The frontier of AI is incredibly exciting! . Happy to have co-led /.
0
0
1
RE: if your text contains em-dashes (long dashes), it's likely generated or co-generated by ChatGPT. Fun fact, if you ask it to provide suggestions rather than revisions. It will complain about the lack of what it considers to be "typographically correct" symbols 😅: .“5-10x” →.
0
0
3
News are getting old very quickly nowadays. @alexwei_ and the team reports that an experimental variant of an OpenAI model is estimated to achieve the level of a gold medalist at IMO using a generalist model. Great achievement: I hope this model will be available to a general.
A blog post on evaluating LLMs on 2025 International Math Olympiad. The best LLM scored 31% (Gemini) and the next best one (o3-high) scored only 16%: Such a huge gap: Great job Gemini team! It is actually not yet clear if Gemini will be at a bronze level, but it's unlikely.
0
0
2
Results? If read tables correctly, there's only very modest boost in both recall & NDCG, which is within 2%. Given that the procedure requires a second retrieval, it does not seem to worth an effort. 🟦.
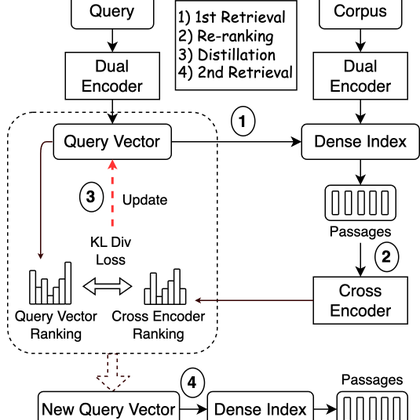
dl.acm.org
0
0
3
PRF was not forgotten in the neural IR times, but how does it perform really? Revanth Gangi Reddy & colleagues ran a rather thorough experiment and published it SIGIR. ↩️.
1
0
2
It was doc2query before doc2query and, in fact, it improved performance (by a few%) of the IBM Watson QA system that beat human champions in Jeopardy!.↩️.
research.ibm.com
Statistical source expansion for question answering for CIKM 2011 by Nico Schlaefer et al.
1
0
2
I think this is a problem of completely unsupervised and blind approach of adding terms to the query. If we had some supervision signal to filter out potentially bad terms, this would work out better. In fact, a supervised approach was previously used to add terms to documents!.
1
0
3
Fixing this issue produced a sub-topic in the IR community devoted to fixing this issue and identifying cases where performance degrades substantially in advance. Dozens of approaches were proposed, but I do not think it was successful. Why⁉️.↩️.
1
0
2
PRF tends to improve things on average, but has a rather nasty property of tanking outcomes for some queries rather dramatically: When things go wrong (i.e., unlucky unrelated terms are added to the query), they can go very wrong. ↩️.
1
0
2
PRF is an old technique introduced 40 years ago in the SMART system (arguably the first open-source IR system). ↩️.
🧵40 years ago the SMART IR system was released. It introduced a few key concepts including vector space interpretation of the retrieval process and the relevance feedback algorithm. I also think it was probably the first open source search engine. ↩️.
1
0
2
🧵Pseudo-relevance feedback (PRF) (also known as blind feedback) is a technique of first retrieving/re-ranking top-k documents and adding some of their words to the initial query. Then, a second retrieval/ranking stage uses an updated query. ↩️.
1
0
8
For the record I think models are still pro mne to shortcuts but with more data (including pretraining), better architectures, and much larger number of parameters, the accuracy on many realistic tasks has improved dramatically (also many fewer silly mistakes are made).
🧵Just a decade ago, we had models that could not detect cows on the beaches due to over relying on shortcuts like presence of green grass, but now we have capable action models that interact with websites directly from pixels. ↩️.
0
0
0