
siyue.zhang
@siyue_zhang_sg
Followers
18
Following
6
Media
6
Statuses
12
RT @_akhaliq: SciArena. An Open Evaluation Platform for Foundation Models in Scientific Literature Tasks

0
22
0
RT @StellaLisy: 🤯 We cracked RLVR with. Random Rewards?!.Training Qwen2.5-Math-7B with our Spurious Rewards improved MATH-500 by:.- Rando….
0
344
0

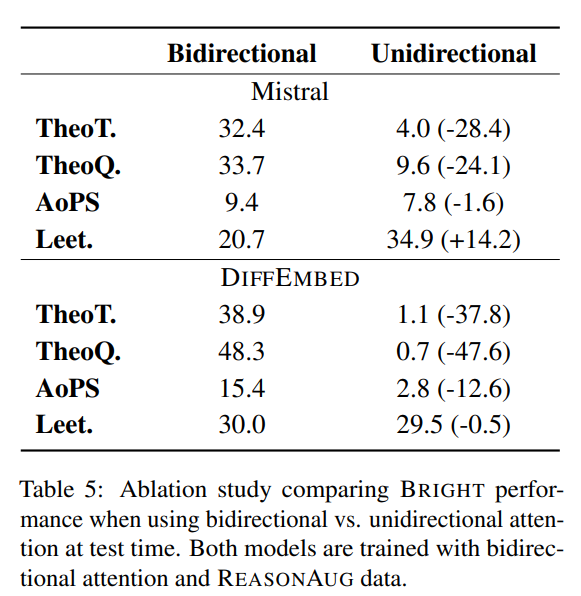
[7/8] Our ablation study shows attention in both directions—causal and reverse—is crucial for encoding long and complex documents. Reverse attention has a greater impact in DiffEmbed than in LLM-based models, and tasks such as TheoremQA, rely more heavily on reverse attention.
1
0
2
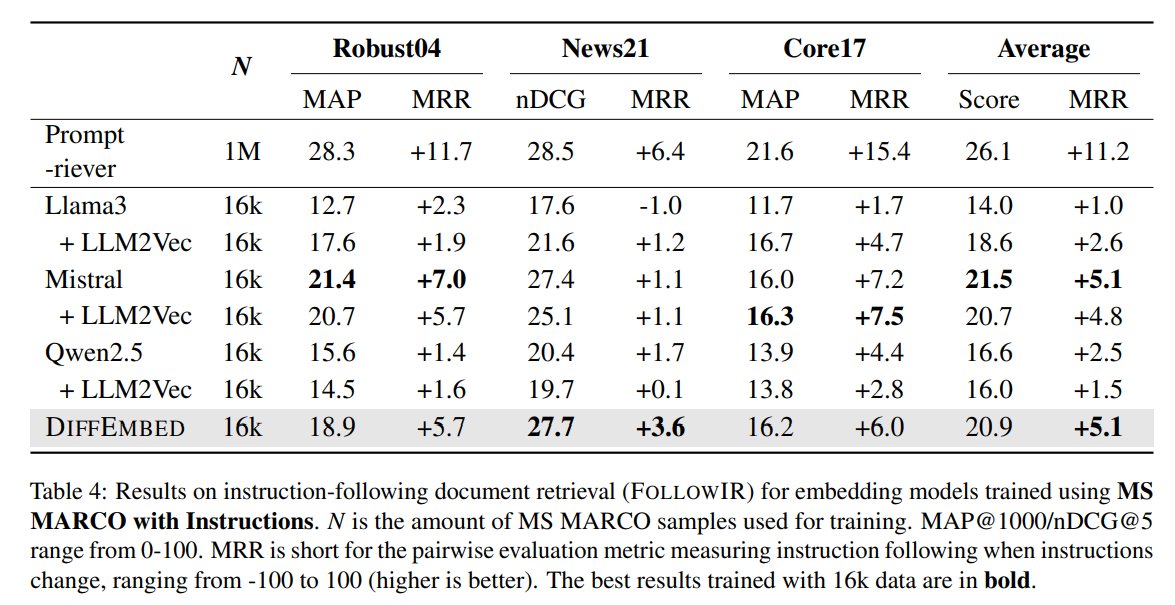
[6/8] DiffEmbed is on-par with LLM-based embedding models across various other tasks, including the instruction-following retrieval benchmark FollowIR and traditional text embedding tasks from MTEB.
1
0
3
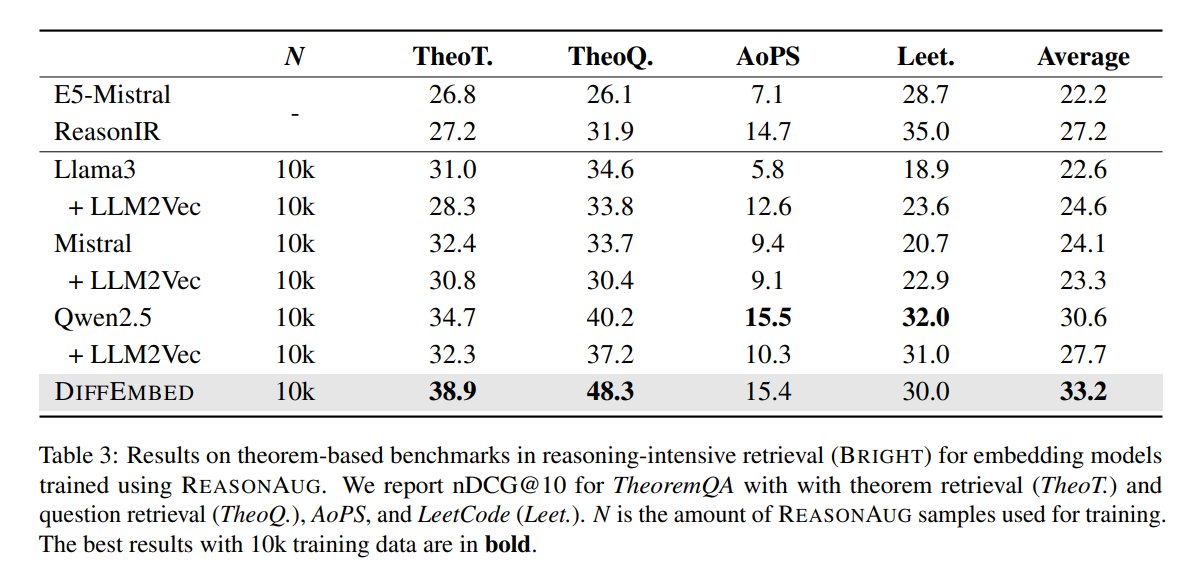
[5/8] DiffEmbed also shows strong performance in encoding logical documents, such as math and coding questions, on the reasoning-intensive retrieval benchmark BRIGHT. It achieves new state-of-the-art (SOTA) scores on these tasks.
1
0
2
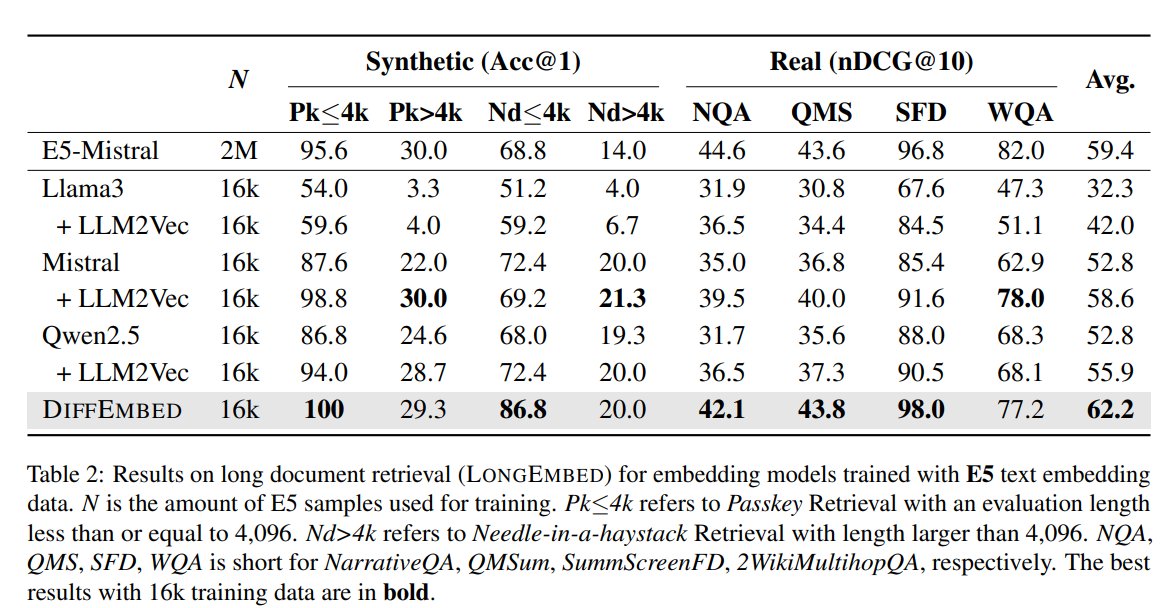
[4/8] We conduct a systematic evaluation of DiffEmbed (based on Dream-7B backbone) vs. LLM-based embedding models (with LLaMA3-8B, Mistral-7B, and Qwen2.5-7B backbones). DiffEmbed demonstrates superior long-document retrieval performance on LongEmbed over all baselines.
1
0
3
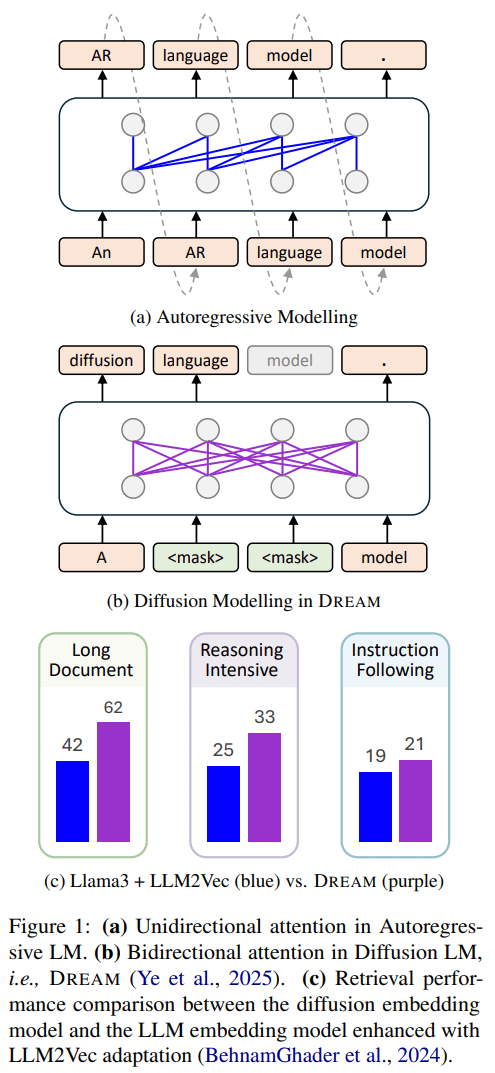
[3/8] We propose to adopt Diffusion Language Models for text embeddings (DiffEmbed). Our hypothesis is that diffusion embeddings, when trained at scale with a bidirectional attention architecture, are better suited to capturing global context for long and complex documents.
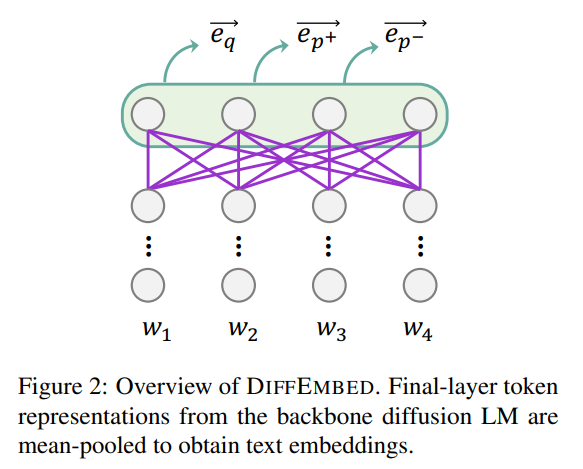
1
0
3
[2/8] Although (autoregressive) LLMs have been powerful backbones for recent embedding models (with LLM2Vec adaptations), they have a fundamental limitation in causal attention used during pre-training, which misaligns with the bidirectional nature of text embedding tasks.
1
0
2
[1/8] How embeddings from Text Diffusion Models ✨compare to those from LLMs 🦙? Check out our work “Diffusion vs. AR Language Models: A Text Embedding Perspective”! We introduce a new diffusion-based embedding model that excels in long-document and reasoning-intensive retrieval.
1
5
22