
Rui Zhang
@ruizhang_nlp
Followers
3K
Following
2K
Media
14
Statuses
444
Researcher in #NLProc | Assistant Professor @PennStateEECS
University Park, PA
Joined April 2013
RT @snigdhac25: Will be attending #ACL2025. Happy to talk about the two papers being presented from our lab on.(1) Identifying unreliable n….
0
6
0
RT @jxmnop: new blog post. "All AI Models Might Be The Same" . in which i explain the Platonic Representation Hypothesis, the idea behind u….
0
163
0
RT @RyoKamoi: Our paper VisOnlyQA has been accepted to @COLM_conf #COLM2025! See you in Montreal🍁.We find that even recent Vision Language….
0
9
0
RT @YusenZhangNLP: HRScene got accepted at #ICCV2025!. HRScene is a novel unified benchmark for high-resolution image understanding with 25….
0
3
0
RT @snigdhac25: Another awesome work on improving fairness in summarization led by @HaoyuanLi9 and in collaboration with @ruizhang_nlp. Hao….
0
4
0
Congratulations @vipul_1011 !!!🎉.


1
0
9
RT @HaoyuanLi9: How can we improve the fairness of multi-document summarization (MDS). We propose FairPO, a preference tuning method that….
0
5
0
RT @jxmnop: excited to finally share on arxiv what we've known for a while now:. All Embedding Models Learn The Same Thing. embeddings fro….
0
623
0
Excited to share our latest work!. The development of process reward models (PRMs) is limited by manual labeling of step-level reasoning correctness. In this new paper led by @RyoKamoi, we use formal verification tools — formal logic and theorem proving — to automatically.

📢 New paper!.FoVer enhances PRMs for step-level verification of LLM reasoning w/o human annotation 🚀.We synthesize training data using formal verification tools and improve LLMs at step-level verification of LLM responses on MATH, AIME, MMLU, BBH, etc.

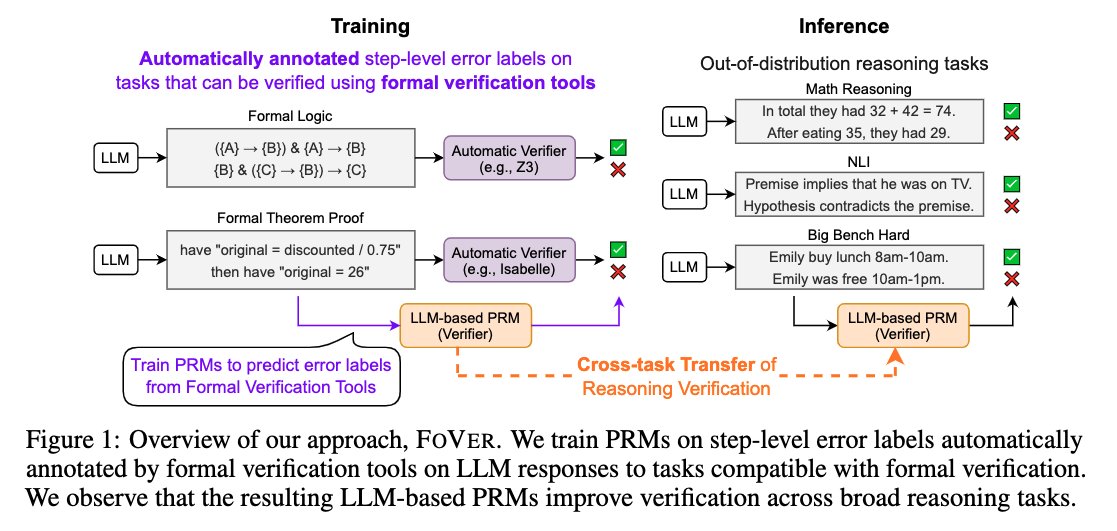
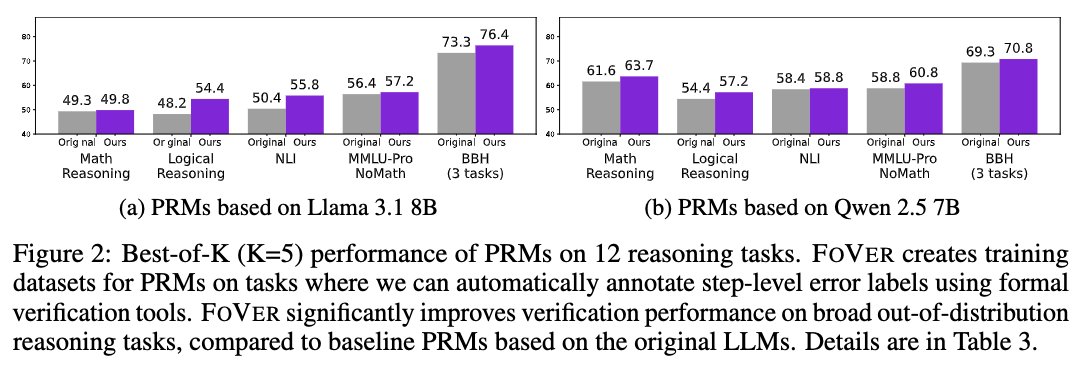
0
9
29
RT @RyoKamoi: Excited to share that I’ll be starting a research internship at Microsoft in Redmond! Looking forward to the research ahead a….
0
2
0
RT @iScienceLuvr: HRScene: How Far Are VLMs from Effective High-Resolution Image Understanding?. "we introduce HRScene, a novel unified ben….
0
11
0
🎉Our paper on fairness of multidoc summarization has received an SAC award at NAACL 2025! 🥳 We appreciate the recognition from senior area chairs. @HaoyuanLi9 and @YusenZhangNLP will present our work: Posters (Exhibit Hall), Session H: Oral/Poster 5, Thursday May 1,.

🟢 Announcing the #NAACL2025 Award Winners! . The Best Paper and Best Theme Paper winners will present at our closing session.

0
5
20
This work is led by my first PhD student Yusen @YusenZhangNLP, who is graduating soon and actively seeking a postdoc position in academia. It has been an absolute pleasure to work with him. Please consider hiring him!.

🚀 How Far Are VLMs from Effective High-Resolution Image Understanding?.👉 We found: Still far. 🆕 Introducing HRScene Benchmark:.📸 25 Real-world Scenes + 🧪 2 Diagnostic NIAH Tests.🏙️ 8 Categories: Daily, Paper, Urban Planning, etc. 🖼️ Resolution: 1,024 × 1,024 ➡️ 35,503 ×


0
5
11
As Vision Language Models treat images as tokens, high-resolution images create long sequences, similar to long-context challenges in LLMs. In this new paper, we release a benchmark to test VLMs capabilities to understand high-resolution images, up to hundreds of millions of.
🚀 How Far Are VLMs from Effective High-Resolution Image Understanding?.👉 We found: Still far. 🆕 Introducing HRScene Benchmark:.📸 25 Real-world Scenes + 🧪 2 Diagnostic NIAH Tests.🏙️ 8 Categories: Daily, Paper, Urban Planning, etc. 🖼️ Resolution: 1,024 × 1,024 ➡️ 35,503 ×
0
5
17
RT @SFResearch: 🔥 Phenomenal Day 1 of poster sessions at #ICLR25! ✨ . Attending tomorrow? Visit us at Booth #G03 to dive into how our groun….
0
3
0
RT @vipul_1011: Ever wondered how much you can trust a benchmark?. We did too - so we built SMART to make them smarter!. I will be presenti….
0
7
0
RT @sarkarssdas: Try GReaTerPrompt to supercharge your prompts — whether you're using open-source models or API-based models! 👇.
0
1
0
📢 GreaterPrompt is Now Live!. We're excited to introduce GreaterPrompt, a unified, customizable, and high-performance open-source toolkit for prompt optimization. 🔍 Key Features:.- 5 Optimization Methods: APO, APE, PE2, GReaTer, and TextGrad.- 4 Model Families: GPT, Mistral,
0
6
21
RT @HaoyuanLi9: How can we evaluate the fairness of summaries for multiple documents with different social attribute values, like sentiment….
0
5
0