

Rui Pan
@rui4research
Followers
275
Following
120
Media
17
Statuses
60
PhD student at UIUC, @OptimalScale maintainer. Research Intern at Meta GenAI
Joined December 2018
RT @AIatMeta: Today is the start of a new era of natively multimodal AI innovation. Today, we’re introducing the first Llama 4 models: Lla….
0
2K
0
RT @RickyRDWang: 🚀 Introducing MA-LoT Theorem Framework: An open-source multi-agent framework utilizing the Long Chain-of-Thought to boost….
0
9
0
RT @wzihanw: 🚀 Introducing Chain-of-Experts (CoE), A Free-lunch optimization method for DeepSeek-like MoE models!. within $200, we explore….
0
165
0
😆Excited to share our latest work on LLM Pruning🔥. 🚀Surpass llama-3.2-1B in MMLU with 1000x less cost.✅Enable flexible model size customization.⭐Key techniques:. • Adaptive Pruning which considers layer-wise importance. • Highly frequent interleaved training that



1
8
23

Generate videos in just a few seconds. Try Grok Imagine, free for a limited time.
4
6
37
RT @Alibaba_Qwen: The burst of DeepSeek V3 has attracted attention from the whole AI community to large-scale MoE models. Concurrently, we….
0
2K
0
RT @HanningZhangHK: We introduce Entropy-Regularized Process Reward Model where we formulate the multi-step mathematical reasoning task und….

arxiv.org
Large language models (LLMs) have shown promise in performing complex multi-step reasoning, yet they continue to struggle with mathematical reasoning, often making systematic errors. A promising...
0
9
0
Thanks so much to all the amazing authors in the paper @Dominicliu12 @shizhediao @RenjiePi @mircale2003 @Glaciohound. LISA also achieves the fastest speed when compared to other baselines according to a third-party evaluation. -
github.com
Use PEFT or Full-parameter to CPT/SFT/DPO/GRPO 500+ LLMs (Qwen3, Qwen3-MoE, Llama4, GLM4.5, InternLM3, DeepSeek-R1, ...) and 200+ MLLMs (Qwen2.5-VL, Qwen2.5-Omni, Qwen2-Audio, Ovis2, InternVL3, Lla...
0
0
1
Support of LISA in LMFlow ( is partial right now. Now the support of LISA + FSDP is in progress.

github.com
An Extensible Toolkit for Finetuning and Inference of Large Foundation Models. Large Models for All. - OptimalScale/LMFlow
1
0
1


The convergence property is also similar to full-parameter training

1
0
0
Presenting our LISA paper at NeurIPS 2024😆.- Dec. 13 at 4:30 pm (Friday afternoon).- West Ballroom A-D #5708. Fine-tuning 7B in a single GPU❔ Randomly freezing ~90% self-attention layers every 5-20 iterations allows that!🚀It is.- 3x Fast.- Memory-efficient.- Good at



1
9
24
RT @shizhediao: Now the post-training of Hymba is officially supported by LMFlow! 🚀.Big thanks to LMFlow folks @Dominicliu12 . @rui4researc….
0
3
0
NVIDIA Hymba-1.5B Instruction Fine-tuning, powered by LMFlow🚀.

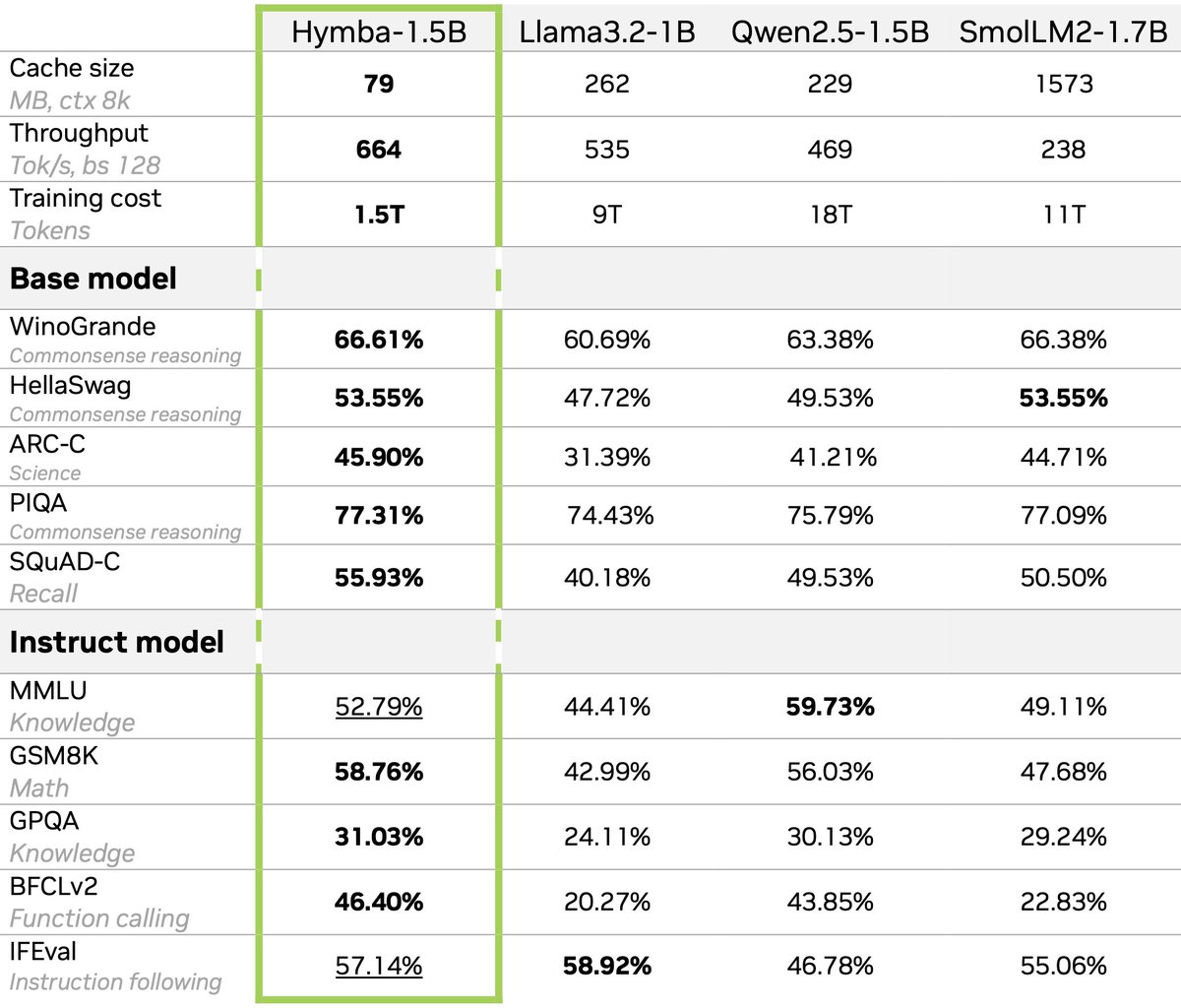
🚀 Introducing Hymba-1.5B: a new hybrid architecture for efficient small language models!. ✅ Outperforms Llama, Qwen, and SmolLM2 with 6-12x less training.✅ Massive reductions in KV cache size & good throughput boost.✅ Combines Mamba & Attention in a Hybrid Parallel
0
3
12
RT @TingAstro: After a year of hard work and many failures along the way, AstroMLab is proud to present AstroSage-LLaMA-3.1-8b. Specific….
0
21
0