
Reyna Abhyankar
@reyna_abhyankar
Followers
19
Following
32
Media
0
Statuses
12
Computer-Use Agents (CUAs) are improving every day but take up to tens of minutes to complete simple tasks. We built OSWorld-Human, a benchmark that measures efficiency - a first-step towards practical CUAs. Check out our blog post!.

Computer-use AI agents (CUAs) are powerful, but way too slow. A 2-minute human task can take a CUA over 20 minutes!. At Wuklab, we're building faster CUAs. Recently, we created OSWorld-Human, a new benchmark to close the speed gap between humans and machines. Read our full blog.
0
2
4
RT @yiying__zhang: Computer-use AI agents (CUAs) are powerful, but way too slow. A 2-minute human task can take a CUA over 20 minutes!. At….
0
4
0

Generate videos in just a few seconds. Try Grok Imagine, free for a limited time.
394
661
3K
RT @yiying__zhang: Boost your gen-AI workflow's quality by 2.8x with just $5 in 24 minutes! Check how Cognify autotunes gen-AI workflow’s q….
github.com
Multi-Faceted AI Agent and Workflow Autotuning. Automatically optimizes LangChain, LangGraph, DSPy programs for better quality, lower execution latency, and lower execution cost. Also has a simple ...
0
4
0
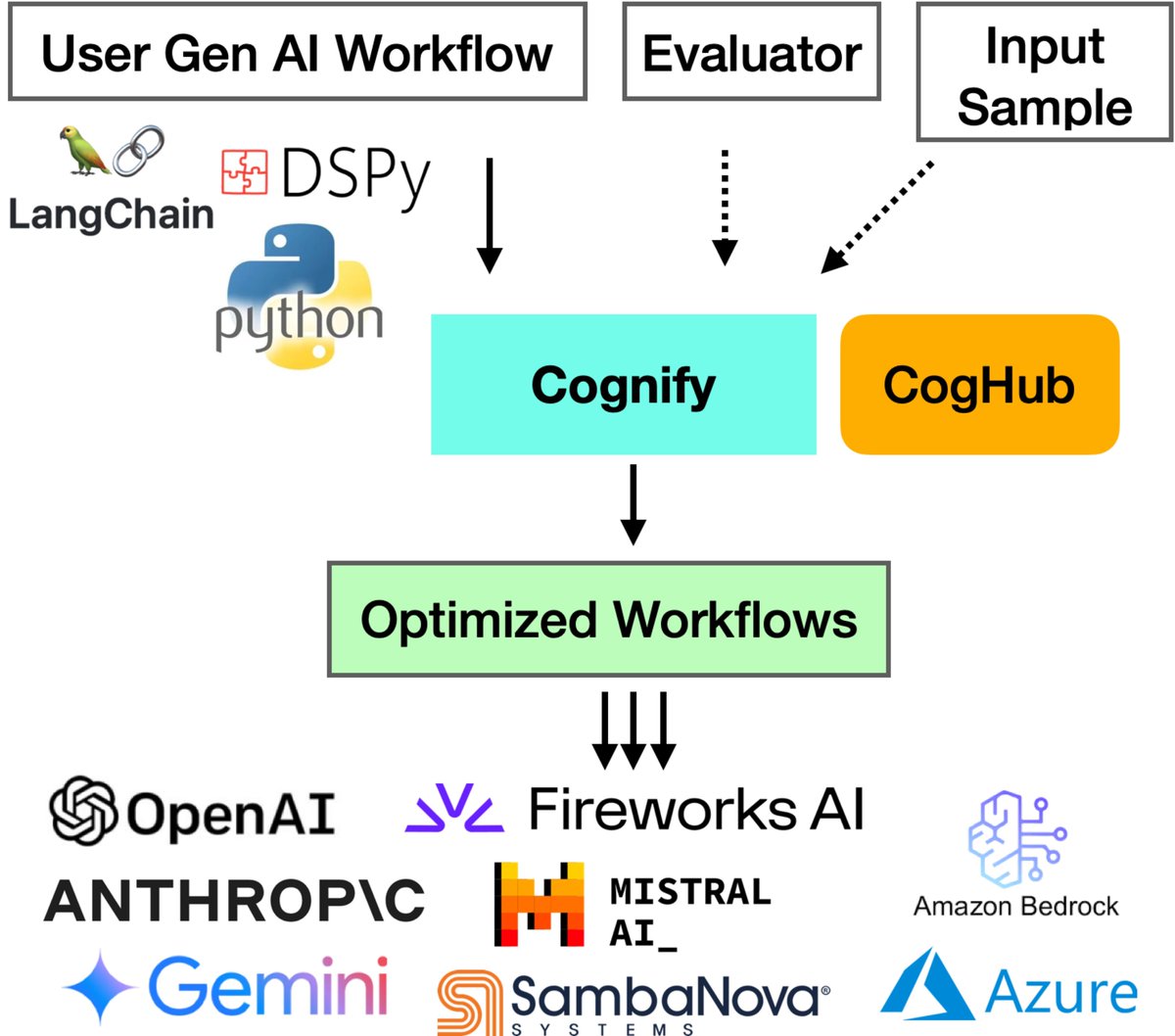
Check out our latest work: Cognify!.
Struggling with developing high-quality gen-AI apps? Meet Cognify: an open-source tool for automatically optimizing gen-AI workflows. 48% higher generation quality, 9x lower cost, fully compatible with LangChain, DSPy, Python. Read & try Cognify: #GenseeAI
0
0
2
RT @yiying__zhang: Struggling with developing high-quality gen-AI apps? Meet Cognify: an open-source tool for automatically optimizing gen-….
0
4
0
RT @yiying__zhang: WukLab's new study reveals CPU scheduling overhead can dominate LLM inference time—up to 50% in systems like vLLM! Sched….
0
12
0
RT @yiying__zhang: Join us at ICML in Vienna next Thursday 11:30-1pm local time (poster session 5) for our poster on InfeCept (Augmented, o….
0
1
0
RT @yiying__zhang: Today, LLMs are constantly being augmented with tools, agents, models, RAG, etc. We built InferCept [ICML'24], the first….
0
2
0
RT @yiying__zhang: LLM prompts are getting longer and increasingly shared with agents, tools, documents, etc. We introduce Preble, the firs….
0
5
0
RT @JiaZhihao: Generative LLMs are slow and expensive to serve. Their much smaller, distilled versions are faster and cheaper but achieve s….
0
73
0