

Qingxiu Dong
@qx_dong
Followers
2K
Following
470
Media
17
Statuses
128
PhD student @PKU1898. Research Intern @MSFTResearch Asia.
Joined August 2019
Thanks to @omarsar0 for sharing our work!

Reinforcement Pre-Training New pre-training paradigm for LLMs just landed on arXiv! It incentivises effective next-token reasoning with RL. This unlocks richer reasoning capabilities using only raw text and intrinsic RL signals. A must-read! Bookmark it! Here are my notes:

0
1
16

⏰ We introduce Reinforcement Pre-Training (RPT🍒) — reframing next-token prediction as a reasoning task using RLVR ✅ General-purpose reasoning 📑 Scalable RL on web corpus 📈 Stronger pre-training + RLVR results 🚀 Allow allocate more compute on specific tokens

31
149
957





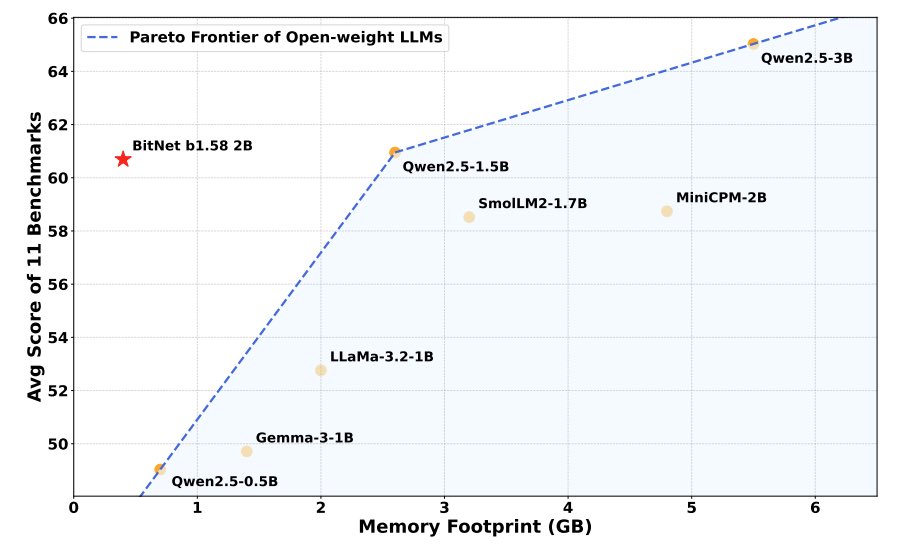
Excited to introduce BitNet b1.58 2B4T — the first large-scale, native 1-bit LLM🚀🚀 BitNet achieves performance on par with leading full-precision LLMs — and it’s blazingly fast⚡️⚡️uses much lower memory🎉 Everything is open-sourced — run it on GPU or your Macbook 🖥️⚙️
23
98
533

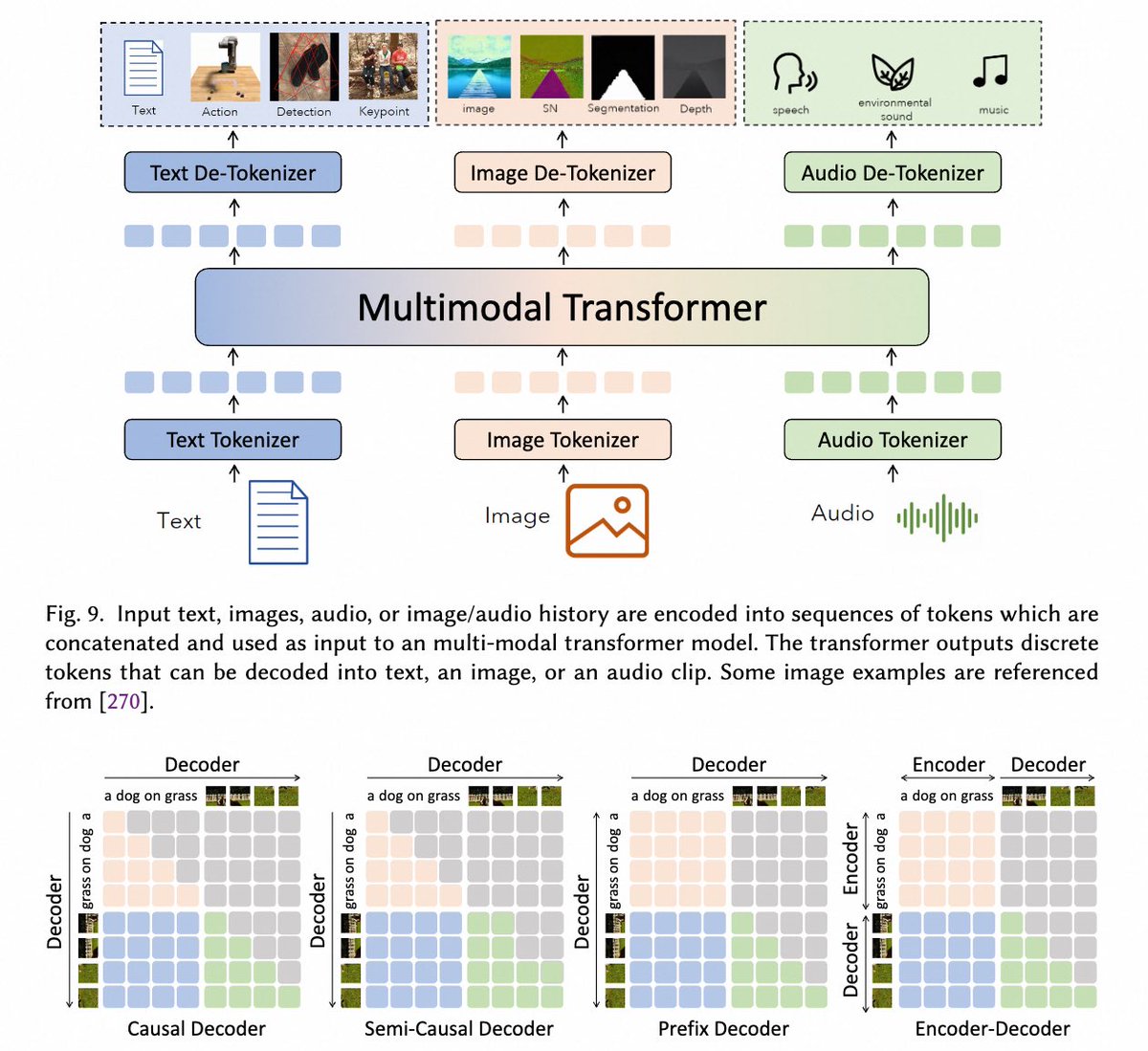
Proud to introduce our latest work “Next Token Prediction Towards Multimodal Intelligence: A Comprehensive Survey” as our new year gift for the multimodal learning community! Paper: https://t.co/fpMfOYexbr Github: https://t.co/9g9hq6yYrT



1
55
256

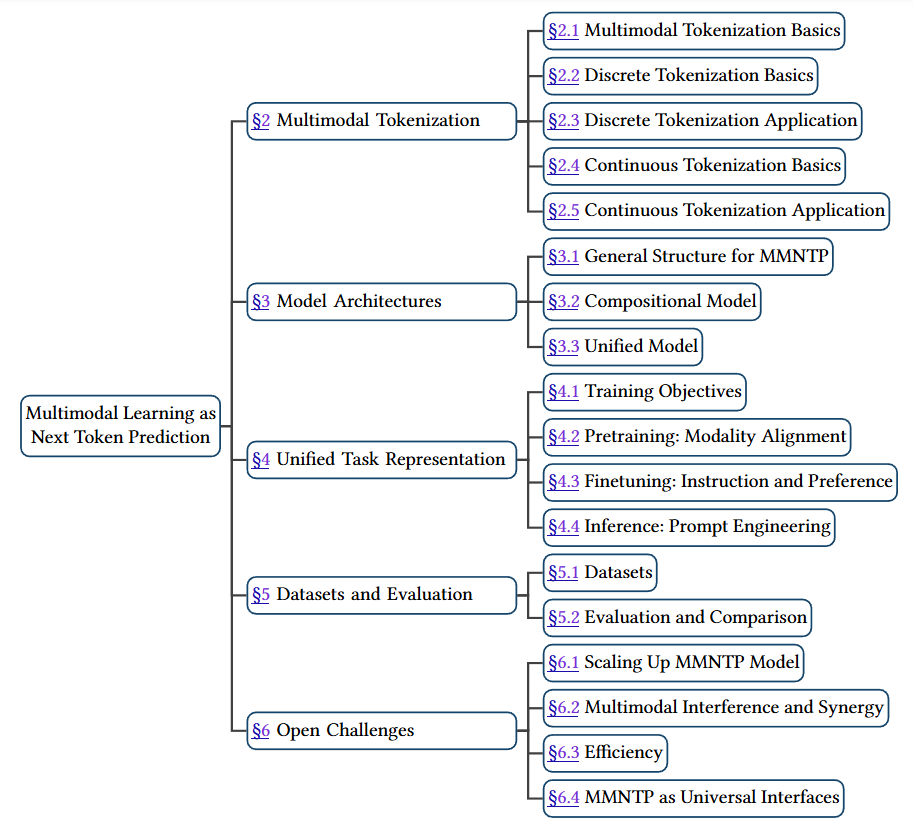
🎆Survey of the Year: 𝐍𝐞𝐱𝐭 𝐓𝐨𝐤𝐞𝐧 𝐏𝐫𝐞𝐝𝐢𝐜𝐭𝐢𝐨𝐧 𝐓𝐨𝐰𝐚𝐫𝐝𝐬 𝐌𝐮𝐥𝐭𝐢𝐦𝐨𝐝𝐚𝐥 𝐈𝐧𝐭𝐞𝐥𝐥𝐢𝐠𝐞𝐧𝐜𝐞: 𝐀 𝐂𝐨𝐦𝐩𝐫𝐞𝐡𝐞𝐧𝐬𝐢𝐯𝐞 𝐒𝐮𝐫𝐯𝐞𝐲 arXiv: https://t.co/M5H0VoVpSX HugFace: https://t.co/9QqIuoA1AB Github: https://t.co/T4Kac2aDaw


2
64
273
About to arrive in #Miami 🌴 after a 30-hour flight for #EMNLP2024! Excited to see new and old friends :) I’d love to chat about data synthesis and deep reasoning for LLMs (or anything else) —feel free to reach out!
0
2
24

🚀Introducing MixEval-X, the first real-world, any-to-any benchmark. https://t.co/XJeUAYMDhQ It extends all benefits of MixEval to multi-modal evaluations, including real-world query distribution, fast yet accurate model ranking, high standards evaluation across modalities!

🏇 Frontier players are racing to solve modality puzzles in the quest for AGI. But to get there, we need consistent, high-standard evaluations across all modalities! 🚀 Introducing MixEval-X, the first real-world, any-to-any benchmark. Inheriting the philosophy from MixEval,

1
4
8
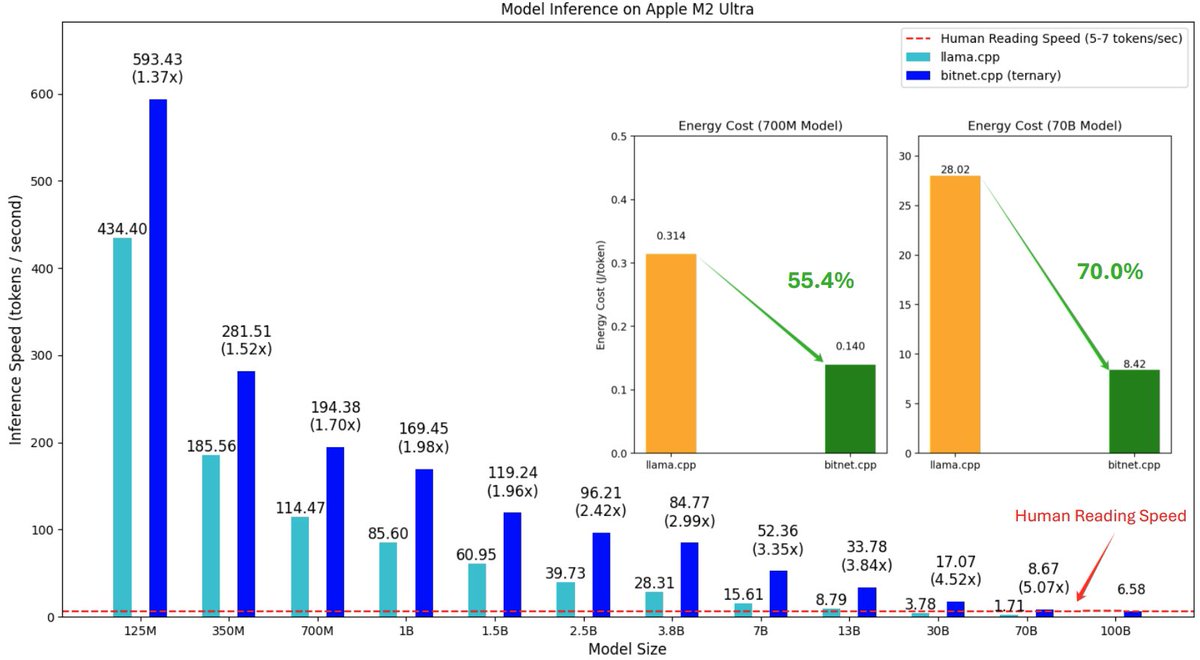
How to deploy a 100B model on your CPU devices? 🔥 Excited to introduce bitnet.cpp, our inference framework for BitNet b1.58 🚀🚀 https://t.co/nVAGhE8n5A
12
70
363
Github: https://t.co/qGqEb8EKbR Project Page: https://t.co/MKql3LWaMa HFDataset: https://t.co/DfCReeORWQ OmniJudge:

huggingface.co
0
1
4
OpenAI o1 scores 94.8% on MATH dataset😲 Then...how should we proceed to track and evaluate the next-gen LLMs' math skills? 👉Omni-Math: a new, challenging benchmark with 4k competition-level problems, where OpenAI o1-mini only achieves 60.54 acc Paper: https://t.co/Qggc7paGwe

10
24
134
✨A Spark of Vision-Language Intelligence! We introduce DnD-Transformer, a new auto-regressive image gen model beats GPT/Llama w/o extra cost. AR gen beats diffusion in joint VL modeling in a self-supervised way! Github: https://t.co/NZNA0Xt2mR Paper:

huggingface.co
2
17
77
(Perhaps a bit late) Excited to announce our survey on ICL has been accepted to #EMNLP2024 main conf and been cited 1,000+ times! Thanks to all collaborators and contributors to this field! We've updated the survey https://t.co/Ev7iMn6IHR. Excited to keep pushing boundaries!

arxiv.org
With the increasing capabilities of large language models (LLMs), in-context learning (ICL) has emerged as a new paradigm for natural language processing (NLP), where LLMs make predictions based...
2
43
213

🤔 Are LLMs Ready for Real-World Data Science Challenges? 🚀 We’ve just open-sourced our #EMNLP2024 work DA-Code, a cutting-edge benchmark designed to push LLMs to their limits in real-world data science tasks. Get involved and challenge your models! https://t.co/D3Qvg8OOFS

3
5
19

🤔How much potential do LLMs have for self-acceleration through layer sparsity? 🚀 🚨 Excited to share our latest work: SWIFT: On-the-Fly Self-Speculative Decoding for LLM Inference Acceleration. Arxiv: https://t.co/8PfUyyuqN6 🧵1/n

1
6
16
How can we guide LLMs to continually expand their own capabilities with limited annotation? SynPO: a self-boosting paradigm training LLM to auto-learn generative rewards and synthesize preference data. After 4 iterations, Llama3&Mistral achieve over 22.1% win rate improvements


3
21
112