
Pieter Delobelle
@pieterdelobelle
Followers
502
Following
528
Media
42
Statuses
142
Postdoctoral AI researcher on LLM pretraining, tokenization & safety - Prev: @apple, @aleph__alpha, @milaNLProc, PhD & postdoc @KU_Leuven
Berlin
Joined April 2012
Over the last weeks I worked on synthetic datasets, so I made a small LLM scheduler to process large batches reliably, called LLMQ. It's a simple CLI tool that submits jobs (from jsonl or a HF dataset) to RabbitMQ, where multiple workers can take jobs from their queue.
1
1
10
🥳 Our paper "ProbLog4Fairness: A Neurosymbolic Approach to Modeling and Mitigating Bias" is accepted at #AAAI2026! ProbLog4Fairness lets you write down how you think bias enters your dataset using probabilistic logic, then automatically corrects for it during neural network
1
2
2

When is a language hard to model? Previous research has suggested that morphological complexity both does and does not play a role, but it does so by relating the performance of language models to corpus statistics of words or subword tokens in isolation.
1
4
0
We start with the MLP layer, as that provides the biggest VRAM wins and also parallelize the attention heads for a good speedup. Full blog post: https://t.co/Tfgwi3bMiM
0
0
1
I wrote a new blogpost on implementing tensor parallelism for my "llm inference from scratch" series. Now our inference engine can finally serve models that don't fit into one GPU.
I built an LLM inference engine from scratch to learn what goes into serving models efficiently. Starting from @karpathy's nanoGPT with a simple generate() function, I added KV caching, fused sampling (from Flashinfer), CUDA graphs, etc... Let me share some insights. (1/4 🧵)
1
0
6

Breaking: we release a fully synthetic generalist dataset for pretraining, SYNTH and two new SOTA reasoning models exclusively trained on it. Despite having seen only 200 billion tokens, Baguettotron is currently best-in-class in its size range.
80
151
1K
The gap between training models and serving them efficiently is often underestimated. Most researchers don't realize what goes into production inference. Code and detailed analysis available here: ⚙️ https://t.co/FZEU86AyxF 🧑💻 https://t.co/WhYZXHUsid More optimizations
pieter.ai
LLM inference from scratch
0
0
0
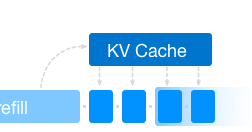
But KV caching alone isn't enough. Sampling was taking 1.77ms per step, since we were sorting the entire vocabulary. Fused rejection sampling kernels eliminated this bottleneck. I also captured the CUDA graphs for prefill and decode phases, which helps a lot for smaller batches.
1
0
0
The most important performance gain is KV caching. Before: recompute attention for every token (compute-bound). After: cache keys/values (memory-bound). This change enables batch parallelism and is foundational for serving LLMs profitably.
1
0
0
I built an LLM inference engine from scratch to learn what goes into serving models efficiently. Starting from @karpathy's nanoGPT with a simple generate() function, I added KV caching, fused sampling (from Flashinfer), CUDA graphs, etc... Let me share some insights. (1/4 🧵)
2
4
16
I also added support for YAML to configure the pipelines, so processing an entire HF dataset is as easy as: $ llmq submit -p example-pipeline.yaml epfl-llm/guidelines Here, each sample will get translated and formatted into markdown. https://t.co/YqsLr3fRzQ
github.com
A Scheduler for Batched LLM Inference. Contribute to iPieter/llmq development by creating an account on GitHub.
0
0
0
Just merged pipeline support into LLMQ, my distributed LLM inference scheduler. You can now define multi-stage workflows where each stage can use different models/workers. Results go through queues with independent scaling per stage.
1
0
2
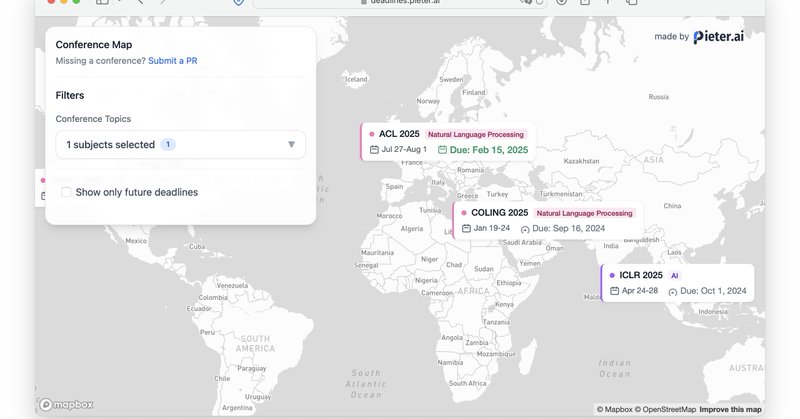
Finally got around to updating my AI conference deadline tracker. I added some new deadlines and a globe view
2
5
19

First high-performance inference for hierarchical byte models. @LukasBluebaum and I developed batched inference for tokenizer-free HAT (Hierarchical Autoregressive Transformers) models, developed by @Aleph__Alpha Research. In some settings, we outcompete the baseline Llama.🧵
2
7
28
Serving an LLM efficiently (=profitably) is highly non-trivial and involves a lot of different design choices. Mixture of experts, as used by Deepseek, complicates this a lot. I really learned to appreciate this from @tugot17 while I was at @Aleph__Alpha, so check out this deep

What are the profit margins of serving DeepSeek 🐳? @schreiberic and I discuss large-scale MoE inference in depth. Blog post link below
0
1
9
@thomas_wint Thanks to EuroEval for the evaluations. Their dataset is here:
0
0
2
5 year old BERT-style models are still winning for Dutch. I was looking at the EuroEval benchmarks and to my surprise are the models we trained in 2019 (RobBERT w/ @thomas_wint ) still SOTA. It takes 70x larger generative models (24B+) to match our 355M parameter encoder model.
2
1
13
I also release some synthetic datasets I made with LLMQ by translating fineweb to Dutch and German. And with a permissive license (ODC-by). 🇩🇪 500k rows translated with @Unbabel's Tower+ 72B: https://t.co/rbpIv3aDME 🇳🇱 1.5M rows translated with Tower+ 9B

huggingface.co
Over the last weeks I worked on synthetic datasets, so I made a small LLM scheduler to process large batches reliably, called LLMQ. It's a simple CLI tool that submits jobs (from jsonl or a HF dataset) to RabbitMQ, where multiple workers can take jobs from their queue.
0
0
7