
Pauline Luc
@paulineluc_
Followers
509
Following
30
Media
1
Statuses
27
Research Scientist @ Google DeepMind - working on video models for science. Worked on video generation; self-supervised learning; VLMs - 🦩; point tracking.
Joined April 2012
RT @joaocarreira: Scaling 4D Representations – new preprint and models now available

github.com
Contribute to google-deepmind/representations4d development by creating an account on GitHub.
0
42
0
So pleased and proud to share with you what our team has been up to, on an ambitious journey to build a video foundation model for scientific domains ! ✨ 🚀 🎞️ 🧪 #ICCV2025 #AI4Science.

Thrilled to share our latest work on SciVid, to appear at #ICCV2025! 🎉.SciVid offers cross-domain evaluation of video models in scientific applications, including medical CV, animal behavior, & weather forecasting 🧪🌍📽️🪰🐭🫀🌦️. #AI4Science #FoundationModel #CV4Science.[1/5]🧵
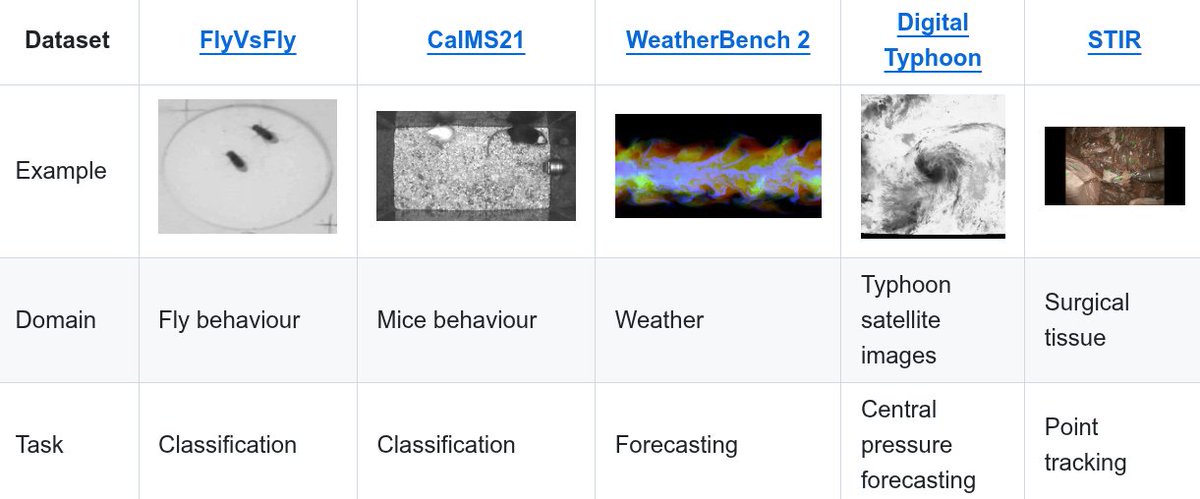
0
1
14

RT @skandakoppula: We're excited to release TAPVid-3D: an evaluation benchmark of 4,000+ real world videos and 2.1 million metric 3D point….
0
58
0
RT @CarlDoersch: We present a new SOTA on point tracking, via self-supervised training on real, unlabeled videos! BootsTAPIR achieves 67.4%….
0
64
0
RT @Mesnard_Thomas: Thrilled to present to you Gemma!.A family of lightweight, state-of-the art and open models by @GoogleDeepMind. We prov….
0
8
0
RT @alexsablay: Our latest release.@MistralAI. Mixtral 8x7B mixture of experts .- performance of a GPT3.5 .- inference cost of a 12B mod….
0
15
0
RT @PierreStock: Mixtral 8x7B is here, 11 weeks only after Mistral 7B. Outperforms Llama 2 70B and GPT 3.5 on most benchmarks, at the infer….
0
27
0
RT @demishassabis: Thrilled to share #Lyria, the world's most sophisticated AI music generation system. From just a text prompt Lyria produ….
0
512
0
RT @arankomatsuzaki: Demystifying CLIP Data. Reveals CLIP’s data curation approach and makes it open to the community. repo: .
0
41
0
RT @emilymbender: Okay, so that AI letter signed by lots of AI researchers calling for a "Pause [on] Giant AI Experiments"? It's just dripp….
0
475
0
RT @anas_awadalla: 🦩 Introducing OpenFlamingo! A framework for training and evaluating Large Multimodal Models (LMMs) capable of processing….

laion.ai
Overview. We are thrilled to announce the release of OpenFlamingo, an open-source reproduction of DeepMind's Flamingo model. At its core,...
0
459
0
RT @AntoineYang2: Introducing Vid2Seq, a new visual language model for dense video captioning. To appear at #CVPR2023. Work done @Google w….
0
16
0
RT @DeepMind: In case you missed it. Flamingo 🦩 a new SOTA visual language model. Read more below ⬇️. Paper: Blog:….

deepmind.google
We introduce Flamingo, a single visual language model (VLM) that sets a new state of the art in few-shot learning on a wide range of open-ended multimodal tasks.
0
24
0
RT @conormdurkan: Chatting with Flamingo about images is definitely the most organic experience I’ve had with an ML model. The ability to r….
0
7
0
RT @antoine77340: Finally able to share what I have been working on this year! 🦩 .Tldr: We took our best LM (Chinchilla), froze it and adde….
0
8
0
RT @arthurmensch: 10B extra parameters for adaptation and visual conditioning, new cross-modality data and a lot of love makes Chinchilla a….
0
5
0
RT @Inoryy: A group of Flamingos is called “flamboyance” which could be an apt description for the family of vision-language models I’m thr….
0
5
0
RT @millikatie: Great to finally share our newest addition to the DeepMind large-scale model zoo! 🦩.
0
14
0
RT @malcolm_rynlds: Was a total pleasure to be part of the team for Flamingo. Lots of exciting capabilities that we are just beginning to e….
0
3
0
RT @yanahasson: A lot happenned in the last year ! I defended my PhD and joined @DeepMind where I worked with an incredible team on Flaming….
0
20
0