

Orfeo Morello
@orfeomorello
Followers
912
Following
9K
Media
57
Statuses
10K
Imagination is more important than knowledge
Italy
Joined December 2009


🔥 China is cooking - 15 seconds with Native Audio! Alibaba's Wan 2.6 is here! ✅Video duration from 3 to 15 seconds ✅Video resolution of 480p, 720p, or 1080p ✅ intelligent prompt rewriting

🚀 Wan 2.6 is now live on fal ! • Text-to-Video & Image-to-Video up to 1080p • Up to 15 second generations • Multi-shot video with intelligent scene segmentation • Import your own audio • Reference-to-Video - use 1-3 reference videos for character/object consistency
10
25
309
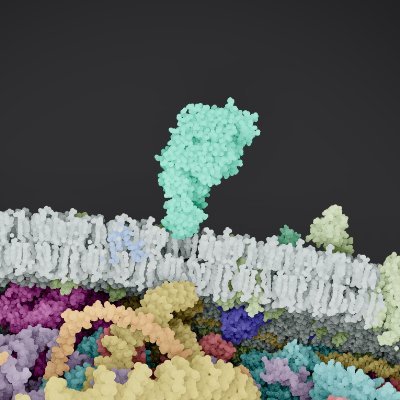
New paper from Apple - Sharp Monocular View Synthesis in Less than a Second Mescheder et al. @ Apple just released a very impressive paper (congrats! 🎉🥳). You give it an image and it generates a really great looking 3d Gaussian representation. Uses depth pro. It's really good.
25
157
2K

In collaboration with NVIDIA, the new Nemotron 3 Nano model is fully supported in llama.cpp Nemotron 3 Nano features an efficient hybrid, Mamba, MoE architecture. It's a promising model, suitable for local AI applications on mid-range hardware. The large context window makes it
developer.nvidia.com
Agentic AI systems increasingly rely on collections of cooperating agents—retrievers, planners, tool executors, verifiers—working together across large contexts and long time spans.
8
44
398

🚀 Announcing Echo — our new frontier model for 3D world generation. Echo turns a simple text prompt or image into a fully explorable, 3D-consistent world. Instead of disconnected views, the result is a single, coherent spatial representation you can move through freely. This
47
172
1K

A 100% open-source alternative to n8n! Sim is a drag-and-drop UI for creating powerful AI agent workflows: - Runs locally on your machine - Works with local LLMs I built a stock market research agent & connected it to Telegram in minutes. Here's a step-by-step guide:
36
261
2K

my current open-source ai stack > ocr - glm 4.6v / qwen 3 vl > coding - minimax m2 / glm 4.6 > writing - deepseek v3.2 / kimi k2 > general purpose - deepseek v3.2 > problem solving - deepseek speciale > image gen - z-image-turbo / flux 2 dev > image editing - qwen image edit /
26
78
935

ElevenLabs has officially LOST to Open-Source ResembleAI allows you to clone ANY voice without verification using on 5-10 seconds of audio, and dominates on paralinguistic tags for human-like expressions. Most "fast" text-to-speech models sound robotic. Most "quality" TTS
81
396
3K

🚀 Qwen Code v0.5.0 is here! ✨ What’s new: • VSCode Integration: Bundled CLI into VSCode release package with improved cross-platform compatibility • Native TypeScript SDK: Seamlessly integrate with Node/TS • Smart Session Management: Auto-saves and continue conversations •
github.com
What's Changed feat(i18n): add Russian language support by @fazilus in #1238 test(cli): add tests for /language command and fix LLM output language parsing by @afarber in #1236 fix: remove red...
48
168
1K

New TTS banger: Chatterbox Turbo 🤯 Zero-shot model that matches any reference voice with native paralinguistic tags, optimized for low-latency voice agents. ⬇️ Demo available on Hugging Face
9
90
641

TurboDiffusion: 100–205× faster video generation on a single RTX 5090 🚀 Only takes 1.8s to generate a high-quality 5-second video. The key to both high speed and high quality? 😍SageAttention + Sparse-Linear Attention (SLA) + rCM Github: https://t.co/ybbNBjgHFP Technical
22
126
678

NVIDIA releases Nemotron 3 Nano, a new 30B hybrid reasoning model! 🔥 Nemotron 3 has a 1M context window and the best in class performance for SWE-Bench, reasoning and chat. Run the MoE model locally with 24GB RAM. Guide: https://t.co/UAHCV8dMNC GGUF: https://t.co/XdmG9ZSnNQ
41
208
1K
Generate → Crop split → Upscale You can use @ailker's workflow here and do everything in one click https://t.co/urclXGta5c

The 3x3 grid is one of the biggest "cheats" of AI filmmaking this year. BUT it's not complete yet. The issue at the moment is that you lose character consistency in each shot's details, and upscaling in NBP is hit or miss. So, what's the best workflow to upscale each shot?
3
8
98

BREAKING: NVIDIA just dropped an open 30B model that beats GPT-OSS and Qwen3-30B — and runs 2.2–3.3× faster Nemotron 3 Nano: • Up to 1M-token context • MoE: 31.6B total params, 3.6B active • Best-in-class performance for SWE-Bench • Open weights + training recipe +
80
320
3K

Andrej Karpathy literally shows how to build apps by prompting in 30 mins https://t.co/WWY5mYSrC1
29
820
4K

My favourite LLM projects are - Olmo (this is like Linux from scratch /Gentoo of LLMs. They open source the entire data training recipe code and weights) - RWKV (RNN only LLM. Insane to think it works). Special mention: recurrentGemma - LiquidAI- they make enterprise grade small

Olmo 3.1 is here. We extended our strongest RL run and scaled our instruct recipe to 32B—releasing Olmo 3.1 Think 32B & Olmo 3.1 Instruct 32B, our most capable models yet. 🧵
11
47
556

Dolphin-v2 🐬 new document parsing model released by @ByteDanceOSS ✨ 3B - MIT license ✨ Works on any document: PDFs, scans, photos ✨ Understands 21 types of content: text, tables, code, formulas, figures & more ✨ Pixel-level precision via absolute coordinate prediction
14
134
766