

Nicolas DUFOUR
@nico_dufour
Followers
364
Following
596
Media
28
Statuses
159
PhD student at IMAGINE (ENPC) and GeoVic (Ecole Polytechnique). Working on image generation. https://t.co/xA3XJiMuQR
Paris, France
Joined April 2010
🌍 Guessing where an image was taken is a hard, and often ambiguous problem. Introducing diffusion-based geolocation—we predict global locations by refining random guesses into trajectories across the Earth's surface! . 🗺️ Paper, code, and demo:
6
37
151
RT @TimDarcet: @chrisoffner3d There's an irreducible error, so 99.99 is probably impossible.However, like in LLMs, we can keep scraping poi….
0
2
0
1
0
15
Congrats to @AIatMeta and @p_bojanowski team for the DinoV3 release! . Seeing it outperforms CLIP on "cultural knowledge" based task like geoloc make me very hopeful for it working really well in VLMs!.
1
0
13
🌍 Geoloc is a fantastic downstream benchmark:. - Requires fine-grained visual understanding (textures, vegetation, road signs, architecture). - Tests global generalization . - Forces models to pick up real-world cues. That’s why DinoV3 shining here is such a big deal 🚀.
1
0
18
Even crazier 🤯 DinoV3 works in some out-of-distribution setups too — as long as there are geographical cues 🌄🗺️. (Remember: the network is trained only on road images!). Where DinoV2 totally failed, DinoV3 is holding up 👊

1
0
17
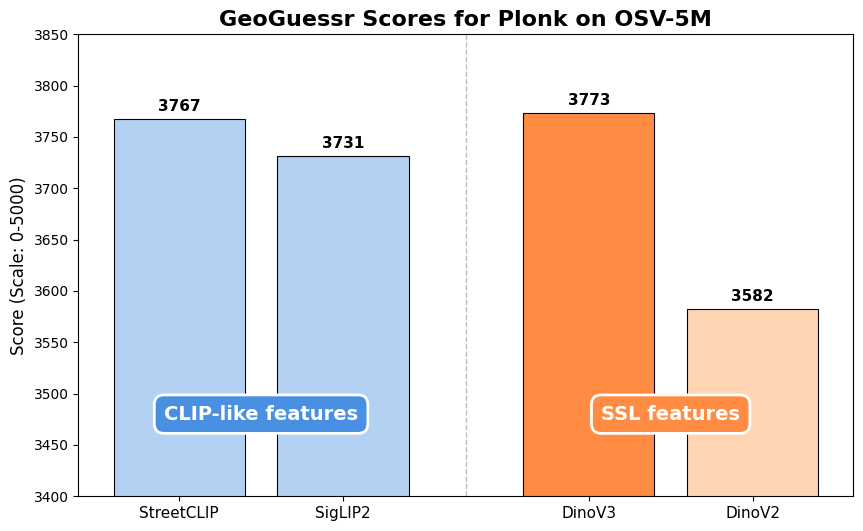
The setup 👉 We use our riemannian flow matching model PLONK (CVPR25: Around the World in 80 Timesteps: A Generative Approach to Global Visual Geolocation) 🌍. We simply swap StreetCLIP with DinoV3 as a drop-in backbone, and train on OpenStreetView-5M. And boom 💥 — DinoV3 wins.


1
2
32
🚀 DinoV3 just became the new go-to backbone for geoloc!.It outperforms CLIP-like models (SigLip2, finetuned StreetCLIP)… and that’s shocking 🤯.Why? CLIP models have an innate advantage — they literally learn place names + images. DinoV3 doesn’t.
2
29
245
I had the privilege to be invited to speak about our work "Around the World in 80 Timesteps" at the French Podcast @UnderscoreTalk ! If you speak french, check it out!. If you want to learn more
0
4
21
RT @iScienceLuvr: Diffusion Beats Autoregressive in Data-Constrained Settings. Comparison of diffusion and autoregressive language models f….
0
120
0
RT @JunyuXieArthur: Movies are more than just video clips, they are stories! 🎬. We’re hosting the 1st SLoMO Workshop at #ICCV2025 to discus….
0
16
0
Come see us in poster 186 to see our poster Around the World in 80 timesteps: A generative Approach to Global Visual Geolocation!
0
2
13
RT @nico_dufour: 🌍 Guessing where an image was taken is a hard, and often ambiguous problem. Introducing diffusion-based geolocation—we pre….
0
37
0
RT @antoine_guedon: I'm at #CVPR2025 to present our paper 🍵MAtCha Gaussians🍵, today Friday afternoon, Hall D, Poster 53!. If you're in Nas….
0
3
0
RT @nico_dufour: I will be at #CVPR2025 this week in Nashville. I will be presenting our paper "Around the World in 80 Timesteps:.A Genera….
0
5
0
We will present it at:. "3rd Workshop on Generative Models for Computer Vision" Wednesday 11 of June, 1pm. Main Conference: Sunday 15 of June, 10h30am, Poster 186.
0
0
1
I will be at #CVPR2025 this week in Nashville. I will be presenting our paper "Around the World in 80 Timesteps:.A Generative Approach to Global Visual Geolocation". We tackle geolocalization as a generative task allowing for SOTA performance and more interpretable predictions.

1
5
9
RT @nico_dufour: @pabloppp So in my experience, At this small scale, textual adherence is actually the "easiest" to have. We worked at thos….

arxiv.org
Recent text-to-image generation models have achieved remarkable results by training on billion-scale datasets, following a `bigger is better' paradigm that prioritizes data quantity over...
0
1
0
RT @nico_dufour: @pabloppp You can check We train a 330M params model for around 500 H100 hours. I've been moderniz….

arxiv.org
Conditional diffusion models are powerful generative models that can leverage various types of conditional information, such as class labels, segmentation masks, or text captions. However, in many...
0
1
0
RT @pabloppp: What is a reasonable amount of GPU hours to train to convergence a "small" t2i diffusion model? 🤔 What would be considered gr….
0
2
0