

search founder
@n0riskn0r3ward
Followers
2K
Following
12K
Media
304
Statuses
4K
Solo entrepreneur passionate about AI and search tech. Building a niche search product and sharing what I learn along the way.
Joined June 2022
Could be within models or across models (think LLM as a jury > LLM as a judge). Not sure an LLM could reliably reason about the source of its error in this setting even if the ensembling method was an just an average but maybe a series of meta prompts that lean into the themes of.
0
0
2
In many ways, fine tuning/training good models just feels like ensemble maxxing. Along these lines a DSPy prompt optimizer idea inspired by @dianetc_ ‘s recent paper - instead of - find the best prompt - find the three best prompts who’s outputs, when averaged or ensembled in.
2
0
8
Gemini DeepThink being very slow (25+ mins per request) has a massive impact on my usage. Even if I think DeepThink will do a better job I use GPT-5 pro bc I get a response back ~5 times faster. Clearest DeepThink win is it’s much better at anything with an image.
0
0
1
GPT-5’s solution to every code change is a config flag. Don’t delete code, just add a flag that turns it off! . Most of the time the code change is about a bug so a config flag that goes around the bug is obnoxious and creates a compounding context rot situation.
2
0
7
Google's gemini docs are pretty lacking on this/wrong but according to the docs you can get logprobs (usually says you can get 20) from the gemini batch api. The batchGenerateContent endpoint throws an error saying - max 5 pls. If you request any your batch returns only errors.
1
1
0
Kinda curious how low you could get this number on MI300X for example or B200s with out of the box inference from sglang or vLLM… is there a person or site where I can just lookup stats from other people’s batch inference workloads? This one is 99.9% input tokens….
0
0
3
I didn’t do anything fancy here, just the default settings, I imagine there’s a lot you can do to make it faster but I just wanted a spin up and ballpark test. I also wanted log probs for a better price than is on offer ATM and this got me that as well.
1
0
1
My feed has a lot less discussion of inference speed or cost of running different models right now but I wanted to know how cheaply I could run Qwen/Qwen3-235B-A22B-FP8 on 8xH100 SXM at runpod’s “on demand” pricing for about $0.1 per M tokens with a big batch run.
2
1
9
On a more positive note - they do at least have a functioning business model so there's that.
1
0
0
Databricks reranker launch blog post is awk. They might as well have titled it - We made a reranker and it sucks! Pls don't ask us what our baseline is in this comparison or what the cost of using our reranker is! Just use voyage re-rank 2.5

3
1
15
V unclear to me what cursor is doing wrong but it's in a really rough state and while I should 100% be using one of the 1000 other amazing tools, that would require me to actually pay for something. which is just rude.
0
0
1
Tried to make my own "manual" mode and the model hates it, I can see from it's chain of thought summaries how confused it is but I can't edit the system prompt etc. so I can't fix the behavior. I just want the apply + approve/reject options on the individual suggestions.
1
0
0
In cursor, if I ask GPT-5 to make an edit to one script which I @ in the request. It will grep that one file 8 times and start exploring the local folder for 10 mins - which then makes the edit less effective and more distracted and is a giant waste of time.
1
0
0
The bootstrapped entreprenuer in me is hella annoyed with the part of me that's following my incentives and switching to the Codex CLI bc it's basically free with my existing monthly sub and somehow 10x better than GPT-5 in @cursor_ai for small single file edits.
1
0
3
In other discoveries today. Fireworks api's will give you 5 log probs. No more log probs for you. @DeepInfra will only give you the log prob of the token generated. And @togethercompute 's docs say they'll give you logprobs but instead they just give you an error. .
2
0
2
I think @FireworksAI_HQ might win the award for dumbest pricing setup. I want to pay you money - maybe just figure out how to let me do that with the least friction possible.

1
0
5
Outperforms Qwen 3's reranker for me which was previously the best reranker in my testing. Also outperforms GPT-5-mini on most metrics. Doesn't quite best Gemini 2.5 Flash Lite, though this is $0.05 per M tokens. It's a Qwen 2.5 train.

📣 Announcing rerank-2.5 and 2.5-lite: our latest generation of rerankers! .• First reranker with instruction-following capabilities.• rerank-2.5 and 2.5-lite are 7.94% and 7.16% more accurate than Cohere Reranker v3.5.• Additional 8.13% and 7.55% performance gain with


1
1
8
Google has had their share of big company problems over the years but those are a guarantee. The fact they’re at all relevant right now much less predicted to have the best model by the end of the month is no small managerial feat.
1
0
0
When you compare Google’s success in AI to Azure and AWS’s inability to run inference on an open source model released by a company they own 49% of, it’s all the more remarkable.

We've launched benchmarks of the accuracy of providers offering APIs for gpt-oss-120b. We compare providers by running GPQA Diamond 16 times, AIME25 32 times, and IFBench 8 times. We report the median score across these runs alongside minimum, 25th percentile, 75th percentile and
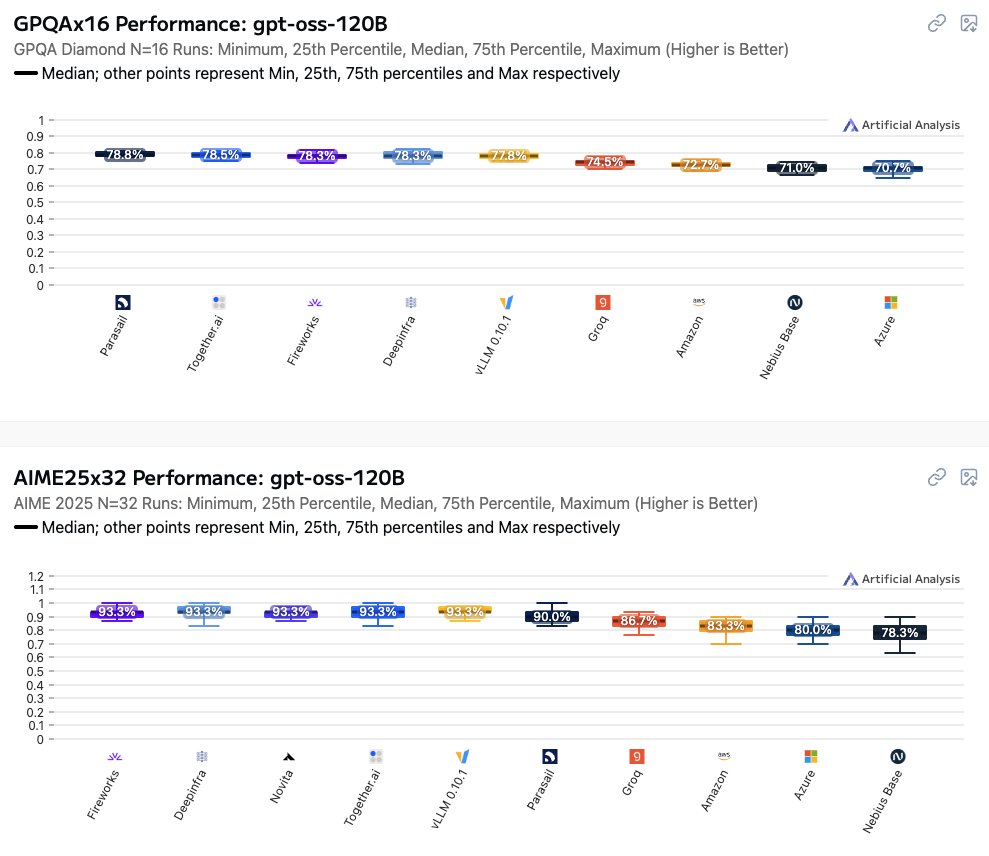
1
0
3